架构设计
- AI程序员自动化开发环境索引
- AI编程IDE使用说明
- 为trae和cursor安装vscode扩展
- 前端AI编程规则模板
- 后端Java项目AI编程规则
- 前端AI自动生成页面
- 使用chrome devtools mcp将axure原型重新实现为vue页面
- 自动化测试工具chrome devtools mcp
- 使用chrome devtools mcp一键将所有页面都点击一次
- vscode开发java的必要设置
- vscode常用插件
- AI辅助编程
- cline&&AI编程插件
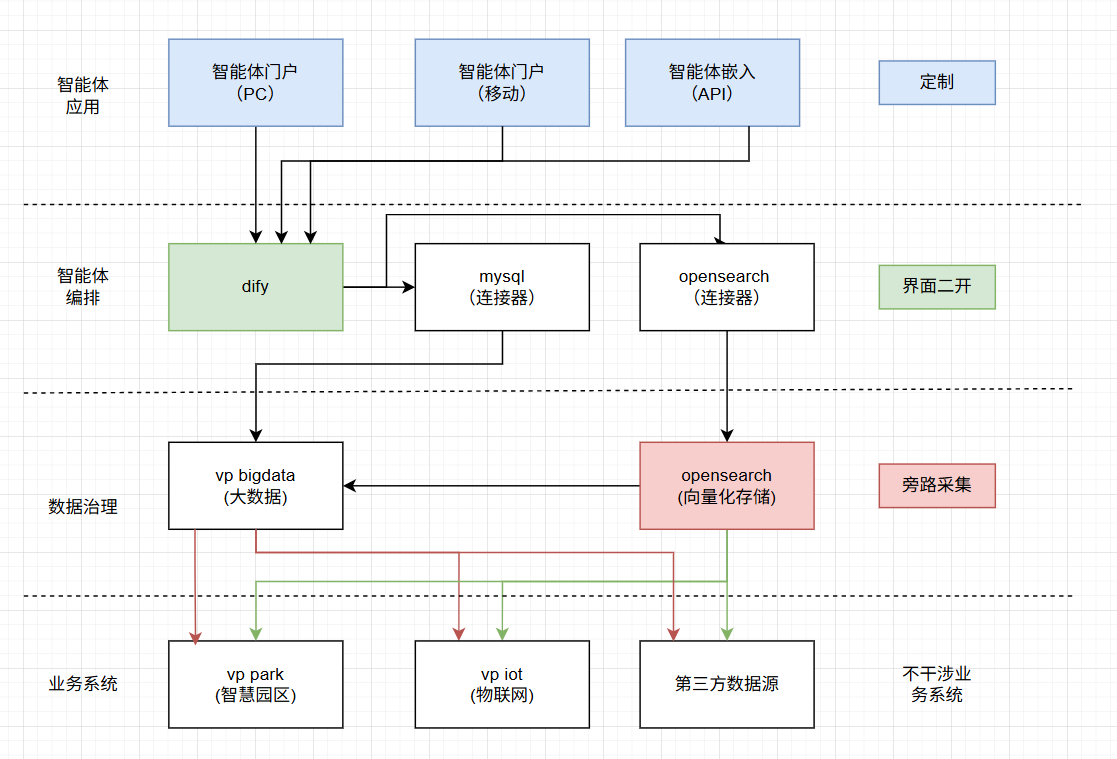
- dify 1.13.2 安装部署 && vplark
- openclaw&&个人AI助理
- 开启openclaw 开启 http 端点
- hermes-agent 智能体
- hermes-agent开启http端点
- 人人框架微服务版开发环境和安装部署
- java后台开发规范
- 高并发性能优化设置&&tomcat设置
- 代码规范插件
- 微服务开发中的一些小工具&&小技巧
- 人人框架代码生成器安装部署
- 软件增加license管理
- 各应用平台注册地址
- 信息系统安全定级说明
- create-springboot-project
- springboot 集成 mybatis
- springboot 集成mybatis-plus
- springboot 集成mybatis-plus通用CRUD
- create-vite-vue-project
- npm和yarn
- hbuilder项目转vue项目&&jenkins uniapp
- CVE漏洞扫描插件
- 漏洞修复&&springboot&&springframework&&springcloud之间的对照关系
- maven版本强行一致方法
- 建设数据中台、业务中台、物联中台,三中台的必要性
- 关于xx实验室信息化系统建设的必要性
- 运维支持考试题
- jvm常见参数
- axure私有分享配置方法
- markdown可视化编辑工具
- 本网站下的所有qq829.cn的域名都被更换为iovhm.com
- 好用的项目管理软件分享
- 软件系统开发流程
- 安装claude
- idea中使用claude code
- 在vscode中使用claude code
- AI生成成套文档
- 使用openclaw进行软件开发前中期系统设计分析
- 使用openclaw进行软件开发前中期系统设计分析
- ai生成各种软件架构图示
- AI生成成套文档-01-立项报告
- AI生成成套文档-02-1-功能清单
- AI生成成套文档-02-2-建设方案说明书
- AI生成成套文档-03-需求规格说明书
- AI生成成套文档-04-进度计划表
- AI生成成套文档-05-测试报告
- AI生成成套文档-06-操作手册
- AI生成成套文档-07-验收报告
- AI生成成套文档-08-结项报告
- 各种文件格式转md
- cursor多工作区&&前后台一起开发
AI程序员自动化开发环境索引
产品经理
- 工具:axure
- 原型发布共享网站:http://axure.whdev.vpclub.cn/
- 配置axure私有分享:https://iovhm.com/book/books/bbcbf/page/axure
- 墨刀:https://modao.cc/ (请联系我加入企业)
工具
- markdown转word:https://iovhm.com/book/books/bbcbf/page/markdown
UI设计师
- sketch:
- UI共享预览网站:
AI程序员
- (java)在idea中使用claude code:https://iovhm.com/book/books/bbcbf/page/ideaclaude-code
- (H5)在vscode中使用claude code:https://iovhm.com/book/books/bbcbf/page/vscodeclaude-code
- openclaw:https://iovhm.com/book/books/bbcbf/page/openclawai
- AI编程IDE使用说明:https://iovhm.com/book/books/bbcbf/page/aiide
- AI插件方式:https://iovhm.com/book/books/bbcbf/page/clineai (2025年12月3日,不在推荐使用插件方式)
前端规则模板
- 前端AI编程规则模板:https://iovhm.com/book/books/bbcbf/page/ai-OMV
- 前端自动生成代码:https://iovhm.com/book/books/bbcbf/page/ai-0zf
- 使用chrome devtools mcp 复制网站:https://iovhm.com/book/books/bbcbf/page/chrome-devtools-mcpaxurevue
- AI生成页面:https://iovhm.com/book/books/bbcbf/page/ai-uSV
后端开发规则模板
- Java项目AI编程规则: https://iovhm.com/book/books/bbcbf/page/javaai
文档规则模板
- 功能清单:https://iovhm.com/book/books/bbcbf/page/ai-02-1
- 建设方案说明书:https://iovhm.com/book/books/bbcbf/page/ai-02-2
- 立项报告:https://iovhm.com/book/books/bbcbf/page/ai-01
- 需求规格说明书:https://iovhm.com/book/books/bbcbf/page/ai-03-jAv
- 进度计划表:https://iovhm.com/book/books/bbcbf/page/ai-04
- 测试报告:https://iovhm.com/book/books/bbcbf/page/ai-05
- 操作手册:https://iovhm.com/book/books/bbcbf/page/ai-06
- 验收报告:https://iovhm.com/book/books/bbcbf/page/ai-07
- 结项报告:https://iovhm.com/book/books/bbcbf/page/ai-08
测试和安全
- CVE漏洞扫描插件:https://iovhm.com/book/books/bbcbf/page/cve
- 使用chrome devtools mcp测试系统:https://iovhm.com/book/books/bbcbf/page/chrome-devtools-mcp
- 使用chrome devtools mcp测试系统:https://iovhm.com/book/books/bbcbf/page/chrome-devtools-mcp-ZAp
自动发布
AI编程IDE使用说明
2025年11月29日,最强的是cursor。编写的代码基本上一次通过
cursor
下载地址: https://cursor.com/cn/download
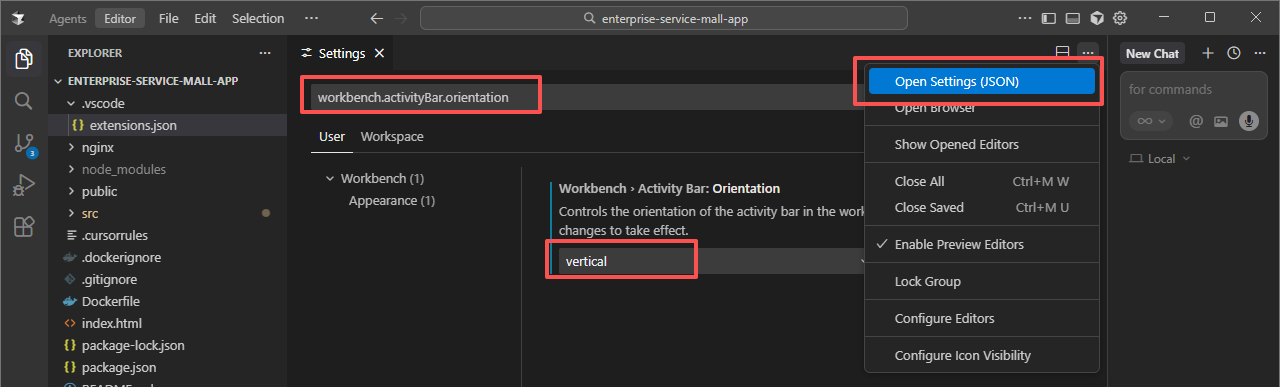
恢复为vscode界面
配置为中文:ctrl+shift+p > Configure Display Language
恢复vscode界面:ctrl+shift+p > Open User Settings(JSON)
{
"editor.fontSize": 14,
"workbench.colorTheme": "Visual Studio Dark",
"workbench.activityBar.orientation": "vertical",
"terminal.integrated.defaultProfile.windows": "Git Bash"
}
或者 file -> preferences -> vs code settings ,搜索框输入 workbench.activityBar.orientation 或者点击右上角的三个小点,选择open settings (json)
设置项目规则
有时候生成代码并不符合我们的项目要求和编程规范,需要设置一个编程规则
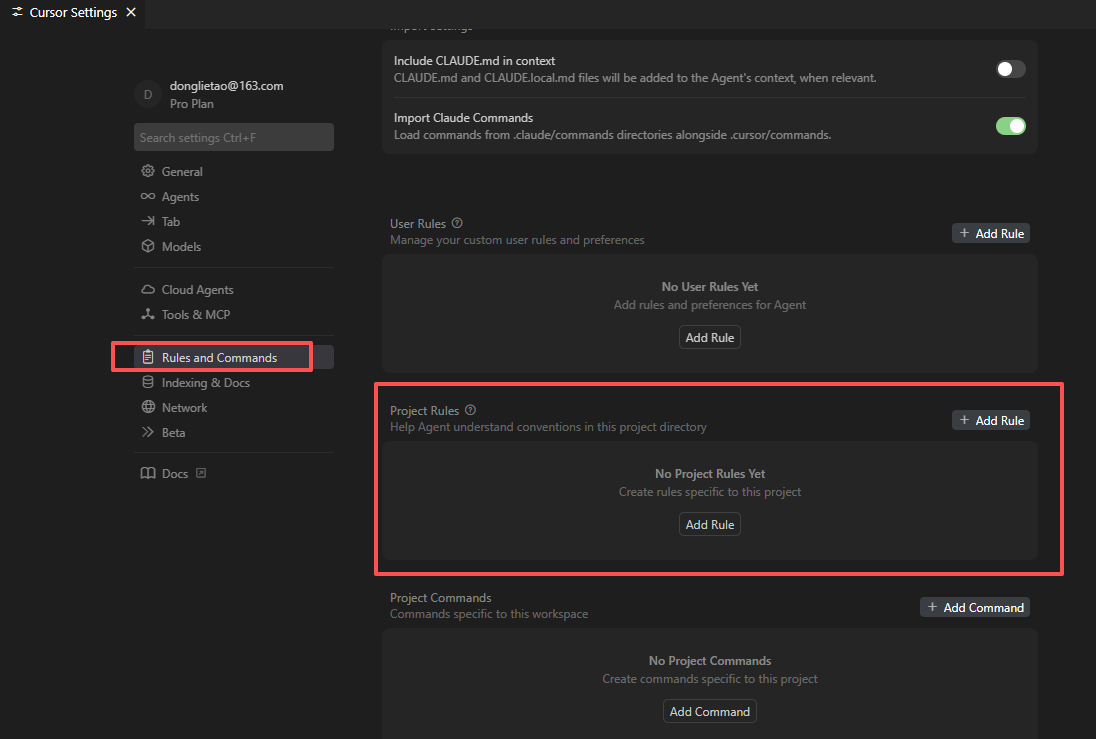
官方帮助:https://cursor.com/cn/docs/context/rules
本文后面章节给出了各项目方向的规则
# vi ./cursor/rules/global.mdc
---
alwaysApply: true
---
trae
下载地址: https://www.trae.cn/ide/download
设置使用git bash作为默认终端
ctrl+shift+p > Open User Settings(JSON)
{
"editor.fontSize": 14,
"workbench.colorTheme": "Visual Studio Dark",
"workbench.activityBar.orientation": "vertical",
"terminal.integrated.defaultProfile.windows": "Git Bash"
}
设置项目规则
有时候生成代码并不符合我们的项目要求和编程规范,需要设置一个编程规则
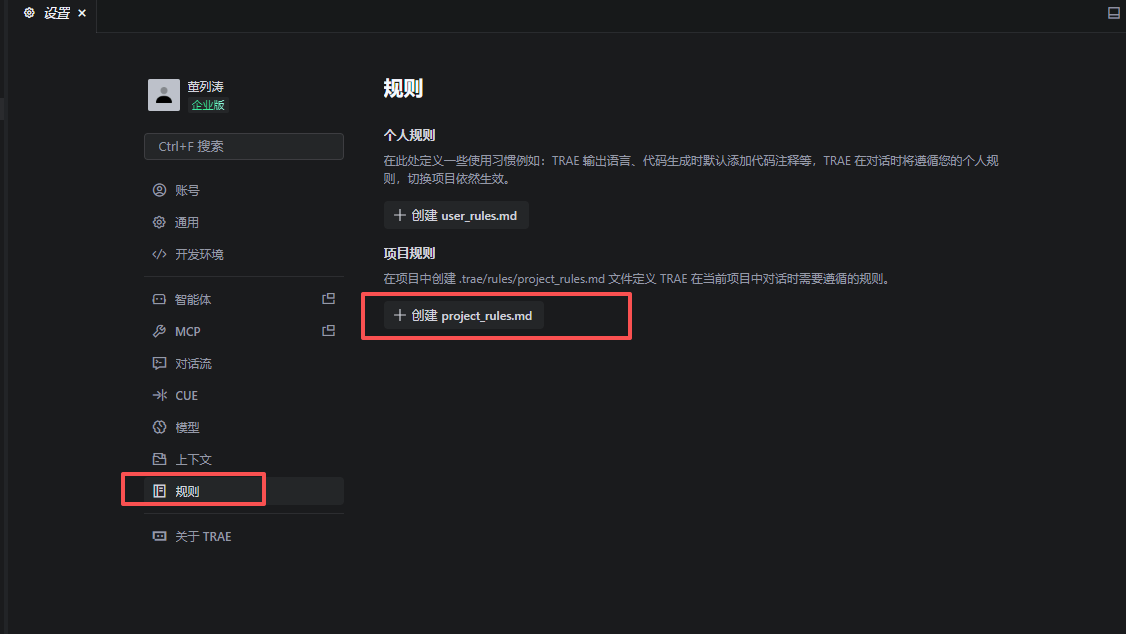
# vi ./trae/rules/project_rules.md
官方帮助:https://docs.trae.cn/ide/rules
本文后面章节给出了各项目方向的规则
voideditor
这是一个完全开源免费的工具,可以接入自己的模型服务,在不合适链接互联网服务的时候就非常有用了
下载地址:https://github.com/voideditor/binaries
设置项目规则
# vi .voidrules
qoder
下载地址: https://qoder.com/download
设置项目规则
AI自动化测试
- 使用chrome devtools mcp 自动化测试: https://iovhm.com/book/books/bbcbf/page/chrome-devtools-mcp
为trae和cursor安装vscode扩展
trae和cursor本身就是从vscode修改而来的,但是这两个软件不能直接安装vscode的扩展市场的插件。
可以从vscode扩展市场把插件下载回来后本地导入安装
方法一
先在vscode找到插件,点击设置图标的下载VSIX下载
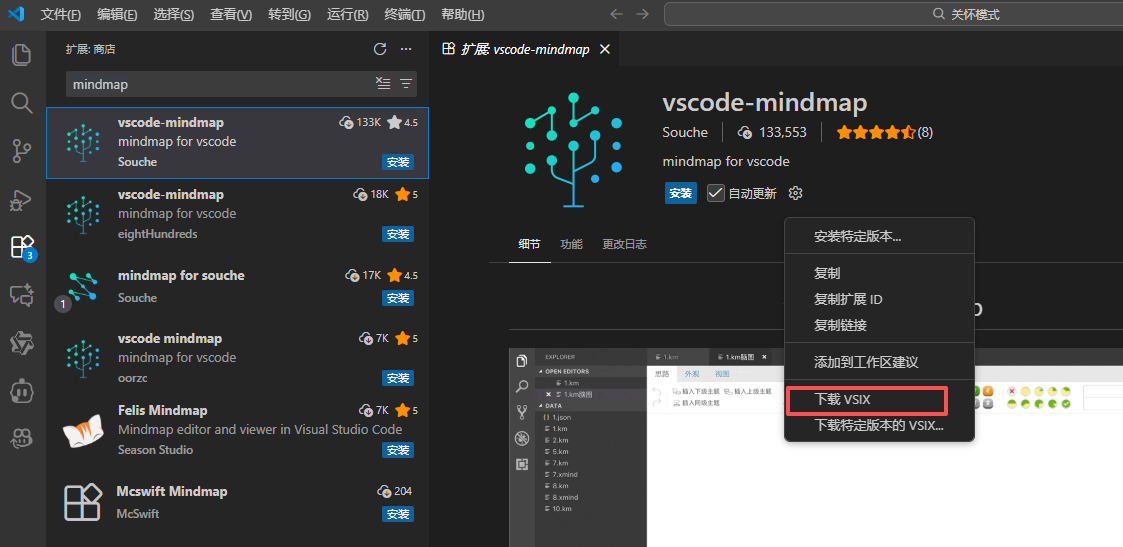
导入下载的插件或者将插件拖入插件面板
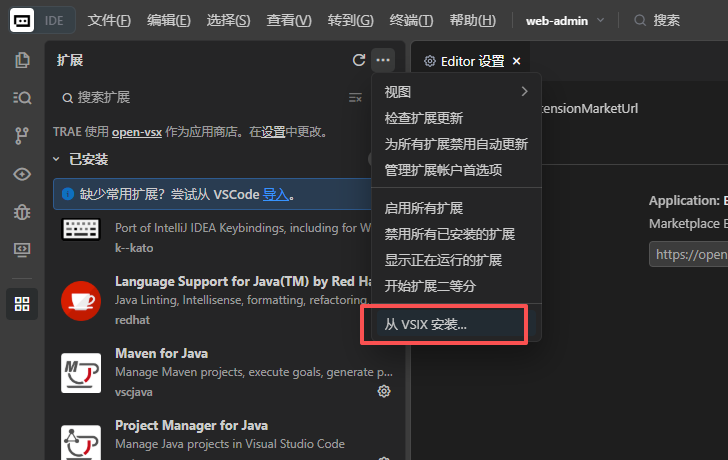
方法二
1、前往vscode插件市场: https://marketplace.visualstudio.com/
2、搜索插件
3、记录插件的两个主要信息
- itemName:URL Query 中的 itemName 字段,并将小数点(.)前后的内容分成以下两个字段:
- fieldA:anthropic
- fieldB:claude-code
- version
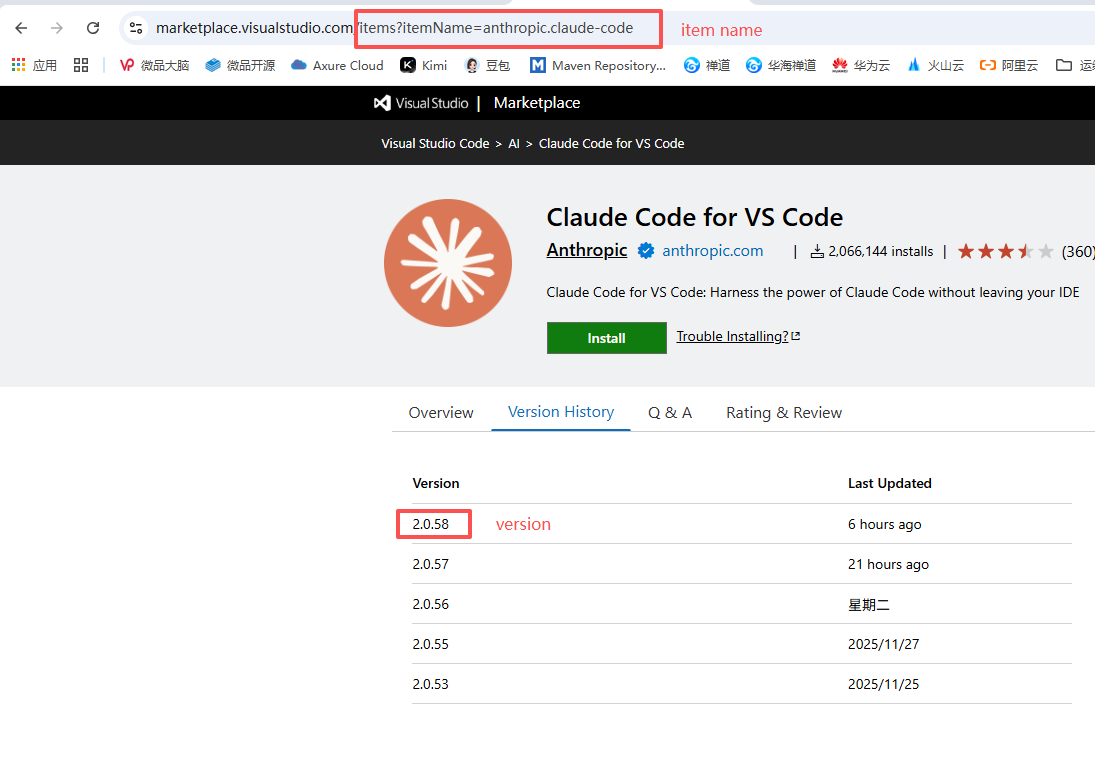
4、获取下载地址,将提取出来的三个字段,替换到下方的URL
https://marketplace.visualstudio.com/_apis/public/gallery/publishers/${itemName.fieldA}/vsextensions/${itemName.fieldB}/${version}/vspackage
例如
https://marketplace.visualstudio.com/_apis/public/gallery/publishers/anthropic/vsextensions/claude-code/2.0.58/vspackage
5、导入下载的插件或者将插件拖入插件面板
前端AI编程规则模板
当前页面实现正确,在保证功能完整、健壮、可阅读的前提下精简代码。并尽可能提升可阅读性、工程一致性、增加注释。
app项目
# 项目规范
## 项目说明
- 本项目基于 Vue 3 + TypeScript
- UI 组件库:Vant 4.9
- 优先使用 Vant 组件,避免重复造轮子
- 构建工具采用 Vite,推荐使用 rolldown-vite 作为插件进行打包优化
## 文件结构规范
### 目录结构
```
src/
├── assets/ # 静态资源(图片、字体等)
│ ├── images/ # 图片资源
│ ├── icon/ # 图标资源
│ ├── styles/ # 全局样式
├── components/ # 全局组件
├── views/ # 页面视图组件
│ ├── index/ # 首页
│ ├── detail/ # 活动详情页
│ ├── profile/ # 我的
│ ├── login/ # 登录
│ ├── register/ # 注册
│ ├── forget/ # 忘记密码
│ ├── reset/ # 重置密码
├── router/ # 路由配置
├── utils/ # 工具函数
├── main.ts # 应用入口
├── App.vue # 根组件
```
### Vue 单文件组件(SFC)格式
1. **必须使用标准 SFC 格式**,文件扩展名为 `.vue`
2. **块顺序固定**:`<template>` 、 `<script>` 、 `<style>`,不可调换
3. **TypeScript 支持**:如需使用 TypeScript,`<script>` 块需声明 `lang="ts"`
## Vue 3 语法规范
### Script 部分
- **默认使用 `<script setup lang="ts">` 语法**,简化组件定义
- 使用 Vue 3 Composition API:`ref`、`reactive`、`computed`、`watch`、`watchEffect`、`provide`、`inject` 等
- **禁止使用 Vue 2 语法**:
- 禁止使用 `this`、`$refs`、`$emit` 等
- 推荐使用 `defineProps`、`defineEmits`、`defineExpose`、`defineModel`
### Template 部分
- 编写**语义化、易读的 HTML 结构**
- 使用 Vue 3 指令:`v-if`、`v-for`、`v-model`、`v-bind`、`v-on` 等
- 事件处理使用 `@` 简写形式
- `v-for` 必须添加 `:key` 属性,并使用唯一标识符
- 避免在模板中写复杂的表达式,复杂逻辑应提取到 `setup` 中
- 示例:
```vue
<template>
<div class="service-card">
<h2>{{ title }}</h2>
<p v-if="description">{{ description }}</p>
<ul>
<li v-for="item in items" :key="item.id">{{ item.name }}</li>
</ul>
<button @click="handleClick">点击</button>
</div>
</template>
```
### Style 部分
- **必须添加 `scoped` 属性**,避免样式全局污染
- 需要穿透样式时,使用 `:deep()` 选择器(Vue 3.0+ 推荐语法)或 `/deep/`(兼容模式)
- 优先使用 Vant 组件自带样式,减少自定义样式
- 使用 less 作为 css 预处理器,优先使用原生 css 变量
- 简单覆盖浏览器默认样式
## UI 组件使用规范
### Vant 组件
- **优先使用 Vant 组件**,避免重复造轮子
- 常用组件已在 `main.ts` 中全局注册,可直接使用
- 如需使用未注册的组件,在 `<script>` 中按需导入
- 组件使用示例:
```vue
<van-button type="primary" size="large">按钮</van-button>
<van-icon name="success" />
<van-list
v-model:loading="loading"
v-model:finished="finished"
:finished-text="'没有更多了'"
@load="onLoad"
>
<van-cell v-for="item in items" :key="item.id" :title="item.title" />
</van-list>
```
- 组件属性优先使用 TypeScript 类型约束:
```typescript
import { VanButtonProps } from 'vant'
const buttonProps = ref<Partial<VanButtonProps>>({
type: 'primary',
size: 'large'
})
```
### 第三方组件
- 若需使用其他第三方 UI 组件,必须在 `<script>` 中导入
- 在模板中以标签形式使用,遵循组件文档规范
- 使用 date-fns 作为日期处理库
- 使用 lodash 作为工具库
- 使用 axios 作为请求库
- 使用 vue-i18n 作为国际化库,自动翻译对应的语言
- 使用 pinia 作为状态管理库
- 使用 crypto-js 作为加密库,使用 aes 算法
- 使用 vConsole 作为调试库,在开发环境下启用
- 使用 animate.css 作为动画库,添加基础的页面动画效果
## 代码质量要求
1. **禁止输出无用内容**:仅保留符合 Vue 3 SFC 约定的代码结构及必要注释
2. **遵循 Vue 3 最佳实践**:所有组件、方法、属性和事件需按 Vue 3 推荐方式声明和使用
3. **保持代码简洁**:避免冗余代码,优先使用组合式 API 的简洁写法
4. **类型安全**:使用 TypeScript 时,确保类型定义完整准确,避免使用 `any` 类型
5. **代码规范**:遵循 eslint 和 prettier 的代码规范
6. **注释规范**:
- 组件文件头部添加组件功能说明
- 复杂逻辑添加内联注释
- API 调用添加注释说明用途
## 响应式数据管理
- 使用 `ref()` 定义基本类型响应式数据
- 使用 `reactive()` 定义对象类型响应式数据
- 使用 `computed()` 定义计算属性
- 使用 `watch()` 或 `watchEffect()` 处理副作用
- `watch` 用于监听特定数据源的变化
- `watchEffect` 用于自动收集依赖的副作用
- 优先使用双向绑定传值,尽可能避免直接操作组件实例方法
- 复杂状态管理使用 Pinia 存储
## 路由与导航
- 使用 hash 模式路由,使用 `createWebHashHistory()` 创建路由历史记录
- 使用 `vue-router` 的 Composition API:`useRoute()`、`useRouter()`
- 路由跳转使用 `router.push()` 或 `router.replace()`
- 查询参数通过 `route.query` 获取
- 路由参数通过 `route.params` 获取
- 优先使用异步加载路由组件,使用 `load` 属性
- 路由守卫使用 Composition API 风格
## 性能优化
- 使用 prefetch 预加载非关键资源
- 使用 lazyload 懒加载非关键资源
- 自动生成 favicon 文件,并支持 PWA 和 OG标签 的规范
- 精简构建产物,去除无用代码和注释,移除 sourcemap 文件
- 定义好开发、测试和生产环境的环境变量,定义好 vite 开发服务器的代理
- 使用 `v-memo` 指令优化 v-for 列表渲染性能
- 避免在模板中使用复杂计算,将计算逻辑移至 setup 中
app 项目:https://iovhm.com/book/attachments/17
后台管理系统
大屏项目
后端Java项目AI编程规则
springboot单项目,对应人人框架企业版单体服务版
# 项目规则说明
## 项目技术栈
- 基础技术栈:Java 17、Spring Boot、mybatis、MyBatis-Plus
- 数据库:MySQL 5.7
- 缓存:Redis 5.0
- 消息队列:RabbitMQ 3.8
- 日志:SLF4J、Logback
- 工具类:Lombok、Hutool
- 构建工具:Maven
## 文件目录结构
- `sketch-viewer-admin`:spring boot 项目,为管理员界面提供RESTful API接口,包含Controller、DTO、VO、Mapper、Service、ServiceImpl、exception、interceptor
- `sketch-viewer-api`:spring boot 项目,为APP界面提供RESTful API接口,包含Controller、DTO、VO、Mapper、Service、ServiceImpl、exception、interceptor
- `renren-common`:spring boot 项目,公共模块,禁止直接修改本文件夹的任何文件,包括子文件夹
- `renren-dynamic-datasource`:spring boot 项目,动态数据源模块,禁止直接修改本文件夹的任何文件,包括子文件夹
- `doc`:文件夹,禁止直接修改本文件夹的任何文件,包括子文件夹
- `docker`:文件夹,禁止直接修改本文件夹的任何文件,包括子文件夹
## sketch-viewer-admin 目录
- spring boot 项目,使用maven构建
- 本项目虽然支持多种数据库,但默认使用MySQL 5.7数据库,暂时不需要支持其他数据库。
- db 目录:禁止直接修改本文件夹的任何文件,包括子文件夹
- db2 目录:在数据库设计阶段,所有生成的业务数据库表结构定义文件必须统一存储在项目根目录下的 `db2` 目录中,针对每个业务模块,需在 `db2` 目录下创建对应的子目录,子目录名称与业务模块名称保持一致(采用小写蛇形命名法,如 `order_management`)。
- src/main/java/io/renren/modules/demo:这是一个示例模块,新添加的模块都应该严格参考此模块的结构、命名规范、接口定义、实现示例。
- java开发规范
- 类命名规范:采用大驼峰命名法,如 `OrderManagementController`。
- 方法命名规范:采用小驼峰命名法,如 `getOrderDetail`。
- 变量命名规范:采用小写蛇形命名法,如 `order_id`。
- 常量命名规范:采用全部大写字母,单词之间用下划线隔开,如 `MAX_ORDER_COUNT`。
- Controller 层的 RESTful API 接口规范
- 禁止在Controller层直接操作数据库。所有与数据库相关的操作必须通过Service层完成。Controller层的职责仅限于处理HTTP请求、调用Service层的方法,并将结果返回给客户端。数据传递应使用DTO(Data Transfer Object),而不是直接使用数据库实体(Entity)或DAO(Data Access Object)。
- Controller 层的 RESTful API 接口必须使用POST方法(@PostMapping),参数必须通过请求体(@RequestBody)传递,禁止使用GET方法传递业务参数。禁止使用PUT(@PutMapping)、DELETE(@DeleteMapping)等方法。
- Controller 层的 RESTful API 接口必须返回JSON格式的响应体,必须使用io.renren.common.utils.Result<T> 类封装响应体,其中T为接口调用结果数据的类型。io.renren.common.utils.Result<T> 类的定义如下:
```java
public class Result<T> {
private int code;
private String msg;
private T data;
}
```
- 数据操作规范
- 所有数据操作都必须使用MyBatis-Plus提供的CRUD方法,仅在必要时才使用MyBatis的Mapper接口。
- 数据库操作实现应该优先考虑使用MyBatis-Plus提供的CRUD方法,仅在必要时才使用MyBatis的Mapper接口。
- 数据库设计规范
- 数据表命名规范:采用小写蛇形命名法,如 `order_management`。
- 数据表字段命名规范:采用小写蛇形命名法,如 `order_id`。
- 数据表都必须包含一个主键字段,主键字段命名为 `id`,数据类型为 `BIGINT`,并设置为自增。
- 数据表必须包含一个 `create_date` 字段,数据类型为 `datetime`,用于记录数据创建时间。
- 数据表必须包含一个 `update_date` 字段,数据类型为 `datetime`,用于记录数据最后更新时间。
- 数据表必须包含一个 `creator` 字段,数据类型为 `bigint`,用于记录数据创建人ID。
- 数据表必须包含一个 `updater` 字段,数据类型为 `bigint`,用于记录数据最后更新人ID。
- 数据表必须包含一个 `delete_flag` 字段,数据类型为 `tinyint(1)`,默认值为 `0`,用于记录数据是否被逻辑删除,0表示未删除,1表示已删除。
```
前端AI自动生成页面
网上教程说的是链接到figma,那意味着需要改变UI和产品的工作方式,让他们放弃已经熟悉的生产力工具;而且figma收费也不便宜。
使用AI的目的是提高生产力,为了自己提高生产力而需要别人降低生产力是不可取的。
如果需要实现下图的效果,首先需要分析页面布局,告诉AI IDE应该如何生成代码
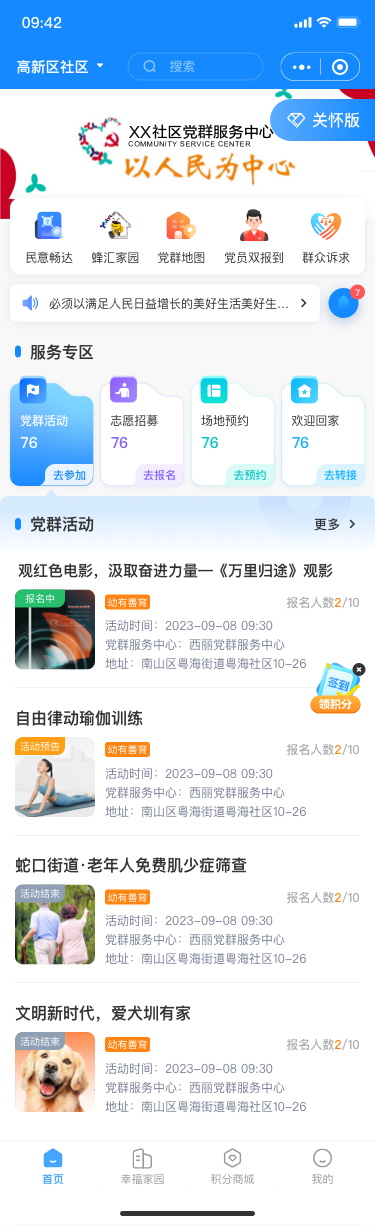
编写布局描述MD文件
方法一:手工描述页面布局
推荐:简单、可控、快捷 , 利用markdown的层级标签描述清晰可见
# 移动端首页布局大纲
## 顶部导航区
- 高度:90px
- 背景:#1589FF
- 左侧:地区下拉选择框
- 从后端获取地区列表
- 字体:16px,加粗
- 颜色:#fff
- 中间:搜索框
- 圆角:20px
- 左侧:搜索图标
- 右侧:清除图标
## 广告轮播区
- 高度:250px
- 3-5 张自动轮播 Banner
- 右侧浮动按钮
- 返回顶部图标
- 宽度:84px
## 快捷入口区
- 高度:150px
- 水平布局5个按钮,每个按钮可以点击跳转
- 图片,大小40px
- 文字,14px,加粗
## 公告区
- 高度:100px
- 左侧小喇叭图标
- 大小:40px
- 中间:公告标题,滚动显示
- 从后端获取公告列表
- 右侧:更多图标
- 大小:40px
## 服务专区
- 高度:150px
- 标题栏:左侧图标,标题文字,右侧更多图标
- 服务项:水平布局4个卡片,每个卡片可以点击跳转
- 背景底图
- 左上角:图标,大小40px
- 水平垂直居中
- 文字:服务名称
- 文字:数量
- 右下角文字:“去参加”
## 党群活动
- 标题栏:左侧图标,标题文字,右侧更多图标
- 活动项:水平多条卡片,每个卡片可以点击跳转
- 从后端获取活动列表
- 活动卡片:
- 第一行:活动标题
- 第二行:活动内容
- 左侧:活动图片
- 宽度:120px
- 右侧活动内容
- 文明时代,爱犬圳有家
- 幼有善育,右侧:报名人数2/10
- 2025-01-01 10:00-12:00
- 西丽党群服务中心
- 地址:北京市海淀区西丽大街100号
方法二:让IDE根据效果图自动分析,然后手工修改
不推荐:trae的效果不如cursor好,部分按钮、卡片识别不准确
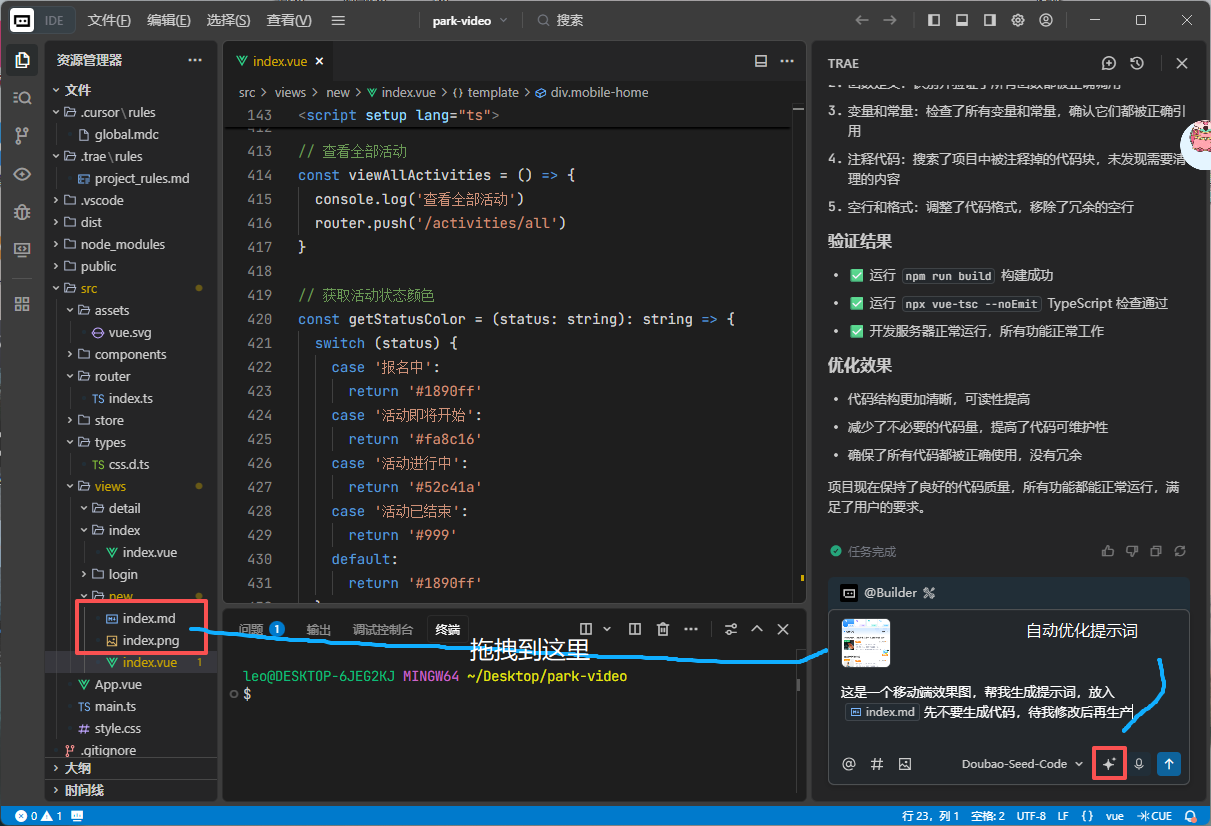
将效果图拖拽到对话窗口,输入你想要做的事情:
这是一个移动端效果图,帮我生成提示词,放入 <index.md> 先不要生成代码,待我修改后再生成代码
还可以点击下方的提示词优化,生成更优的提示词
根据提供的移动端效果图,生成一份详细的设计提示词并保存至 <index.md> 文件中。提示词应包含界面布局结构、色彩方案、交互元素说明、排版要求及特殊设计细节等关键信息。请确保提示词内容完整且专业,能够准确传达设计意图。当前阶段仅需完成提示词文档的创建,无需进行代码实现,待提示词经过审核修改确认后,再进行后续的代码开发工作。
实现代码
输入你想要做的事情的提示词,也可以让IDE自动优化
根据 <index.md> 中的描述,生成符合项目规范的移动端代码
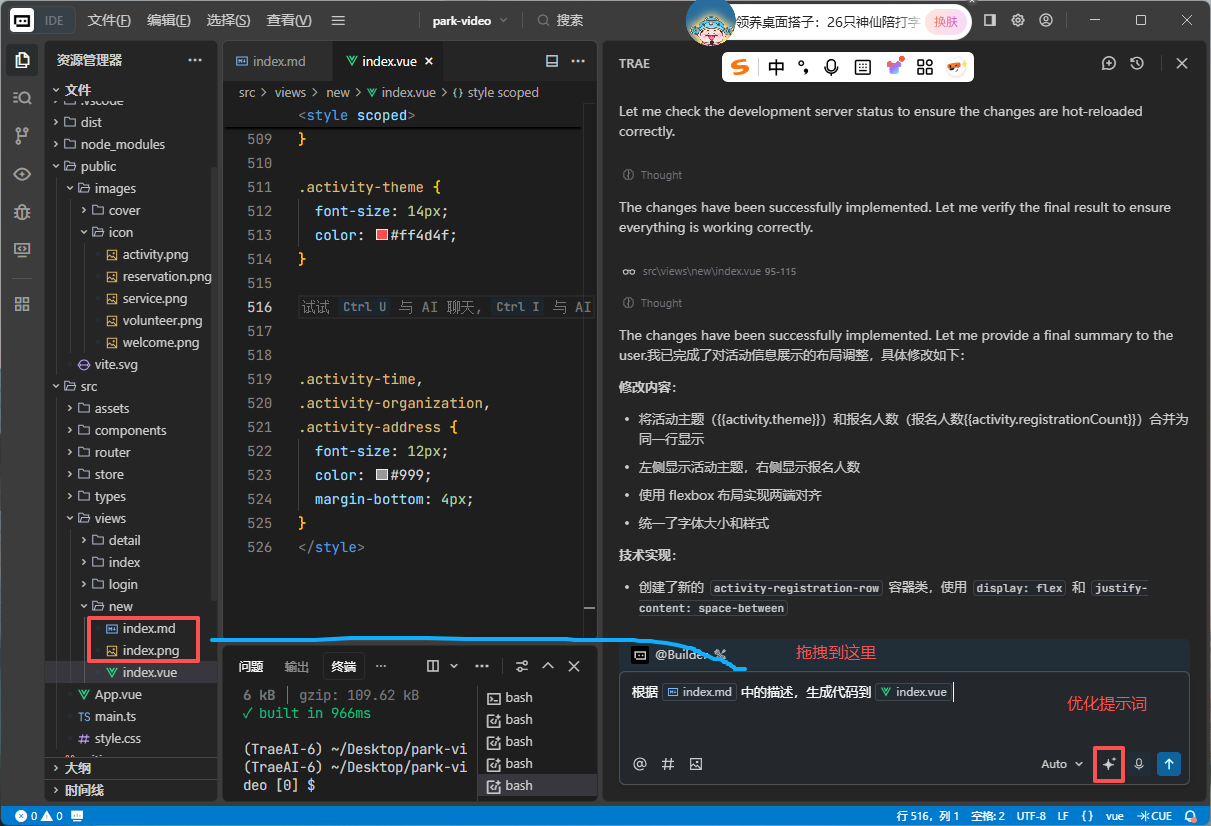
未经过任何修改的实现效果,耗时1个小时
- 编写布局描述文件:40分钟
- 生成代码:10分钟
- 必要的调整:10分钟
先分析、有目标、有逻辑、描述的越清楚,才能实现还原度更好的效果
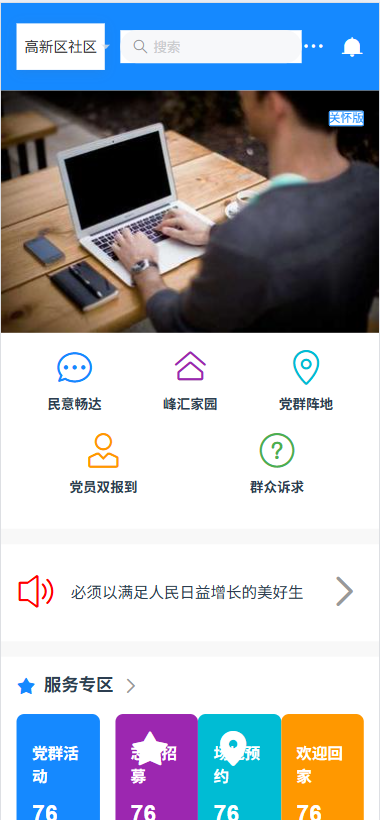
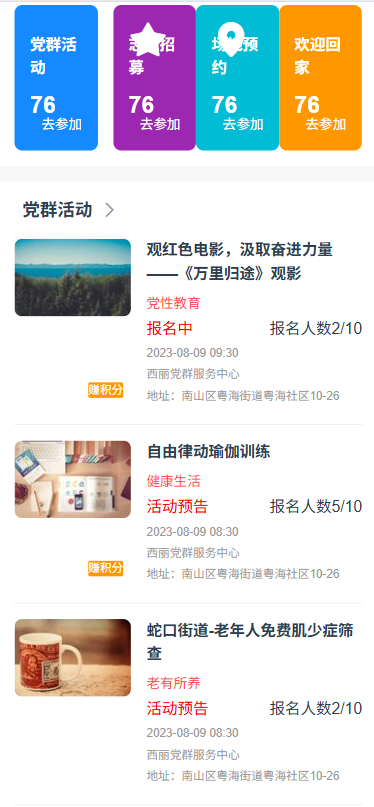
继续调整代码
选中实现有问题的区块代码,ctrl+u ,然后在输入框输入你想要继续修改的提示词
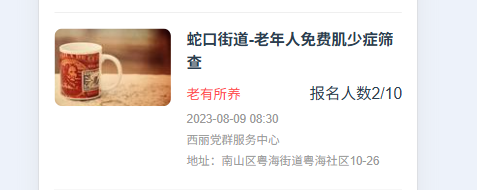
例如:实现与效果图不一致,活动分类与报名人数不是在同一行
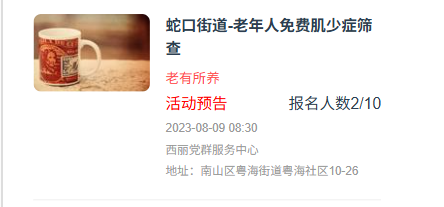
{{ activity.theme}}应该 和 报名人数{{ activity.registrationCount }}在同一行
修正后
使用chrome devtools mcp将axure原型重新实现为vue页面
安装chrome devtools mcp
{
"mcpServers": {
"chrome-devtools": {
"command": "npx",
"args": [
"-y",
"chrome-devtools-mcp@latest"
]
}
}
}
打开axure原型预览
开始使用自然语言创建项目
- 创建空项目
创建一个功能完整的移动端应用项目,包含基础的应用框架结构。需实现底部导航栏功能,导航栏应包含三个主要选项卡,分别为"首页"、"列表"和"我的"。确保应用框架具备页面路由管理、状态管理基础架构和响应式布局设计,以适应不同移动设备屏幕尺寸。底部导航栏需实现点击切换页面功能,当前选中项应有明显的视觉标识,并确保在应用启动时默认显示正确的初始页面。
项目级安装`yarn`,使用yarn安装vant , vue-router ,pinia ,swiper ,crypto-js
使用chrome devtools 打开原型页面并分析和创建对应的页面
使用chrome devtools mcp 打开http://127.0.0.1:32767/15.00.38/index.html
这是axure的原型预览页面,按项目要求实现这个页面到index.vue
保持现有元素和布局不变,参考@public/xvH3GTQIlVovTIZM-image-1764727739274.png 风格,对@src/views/index/index.vue 进行美化
实现我的页面
实现detail页面,当点击@src/views/index/index.vue 中的精彩活动时进行跳转,将数据共享为外部json数据
使用 Chrome DevTools MCP 打开 http://yapi.xxx/xxx,提取 `.right-content` 的 API 文档,按项目实现 API 函数,并在 XXX 区块中集成展示。
自动化测试工具chrome devtools mcp
马上体验
https://iovhm.com/book/attachments/21
简介
chrome官方推出的AI控制chrome的工具,可以使用自然语言驱动浏览器做自动化表单填写、模拟点击事件、获取网络请求,性能分析,console日志分析。
前置要求,需要安装nodejs 24
安装
手工安装
{
"mcpServers": {
"chrome-devtools": {
"command": "npx",
"args": [
"-y",
"chrome-devtools-mcp@latest"
]
}
}
}
通过界面安装
示例为trae的方法,cursor的设置地方法大同小异
文件 -> 首选项 -> 设置
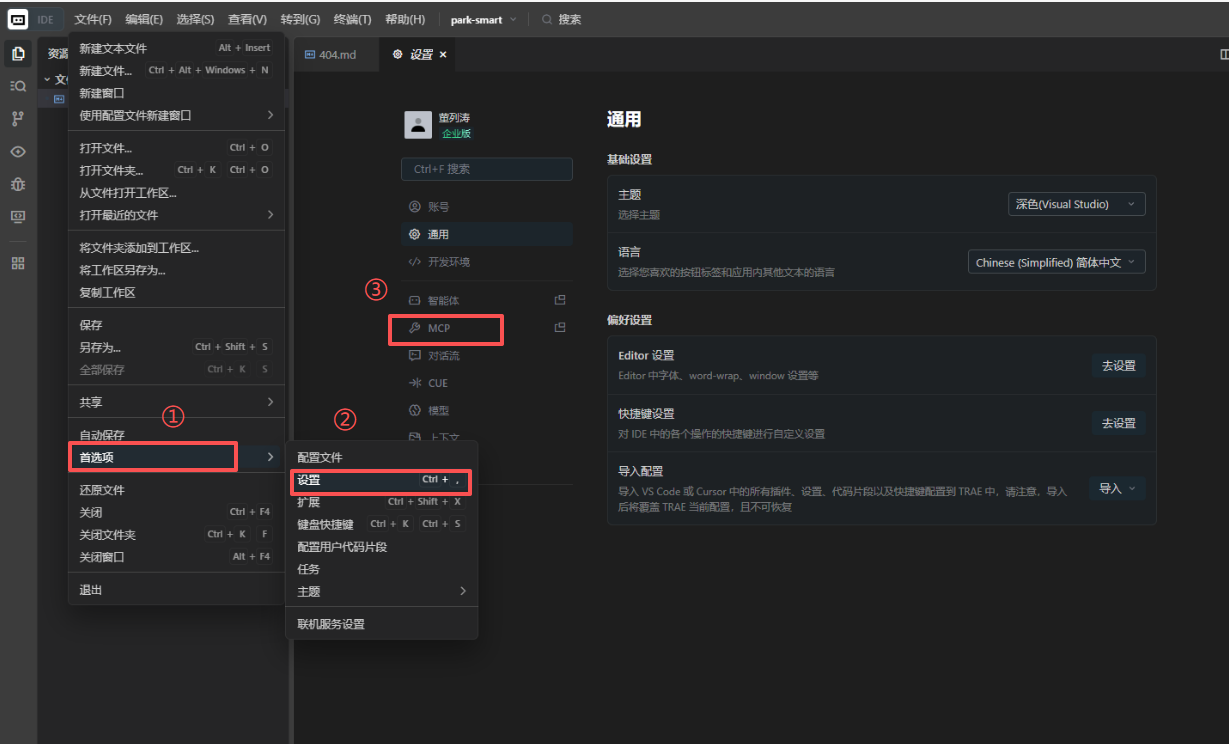
选择从市场添加,搜索Chrome Devtools mcp

设置对话框使用MCP模式
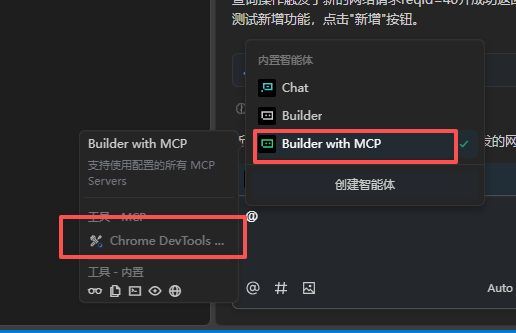
编写全局测试规则
# 1.测试概述
本方案旨在系统性验证目标应用系统所有功能页面的可访问性、稳定性及性能表现,确保用户能够正常访问和使用各项功能。
# 2.测试目标
- **目标网站URL**:来自用户输入的URL或者当前上下文的URL
- **全面覆盖**:系统性验证平台所有页面(包括动态生成的页面)的可访问性
- **功能验证**:验证页面的核心交互功能(查询、分页、排序等)是否正常工作
- **错误检测**:确保每个页面无白屏、404、500等HTTP错误状态码和访问异常,确保页面调用的所有API接口无异常,无404、500等错误状态码
- **日志分析**:检查并记录浏览器控制台错误日志,确保无JS错误、网络请求错误等异常,无其他异常信息
- **性能监控**:评估页面加载性能,识别性能瓶颈
# 3.测试工具与环境
- **主要工具**:Chrome DevTools MCP
- **测试方法**:严格使用**Chrome DevTools MCP**工具进行测试,不要生成任何测试代码
- **浏览器**:Google Chrome
- **网络环境**:稳定网络连接
- **分辨率**:1920x1080 (标准测试分辨率)
- **测试超时设置**:单个页面测试超时时间为30秒,超过此时间视为测试失败
# 4.测试执行流程
## 4.1初始化测试环境
- **打开目标网站**:见**目标网站URL**
- **登录处理**:
- 如遇登录页面,暂停测试流程,待人工登录完成后继续
- **登录状态判断标准**:通过检查页面URL变化(从登录页跳转到主页面)或检查页面中是否存在特定元素(如用户头像、用户名、退出按钮等)来判断登录是否成功
- 登录成功后,等待首页完全加载完成(通过Network面板确认无pending请求)
- **加载确认**:等待首页完全加载完成(通过Network面板确认无pending请求,且DOMContentLoaded事件已完成)
## 4.2页面测试执行流程
- **页面访问**:访问目标URL
- **初始加载等待**:
- 等待页面DOMContentLoaded事件完成
- 通过Network面板监控,等待所有关键网络请求完成(无pending状态的XHR/Fetch请求)
- 如果页面有加载动画或骨架屏,等待其消失
- **动态等待机制**:优先使用网络请求完成状态判断,如果30秒内仍有pending请求,则记录为超时并继续测试
- **功能交互测试**:参照**功能交互测试清单**执行测试
- 定位页面中的查询按钮(通常包含"查询"、"搜索"等关键词或放大镜图标)
- 执行点击操作触发查询功能
- **查询后等待**:等待查询相关的网络请求完成(通过Network面板确认无pending请求),或等待2-5秒(根据页面复杂度调整),确保查询结果加载完成
- **页面验证**:参照**页面验证标准流程**进行验证
- **报告生成**:为每个页面生成独立的测试报告,报告模板参考**页面测试报告规范**规范
- **立即生成测试报告**:在每个页面测试完成后立即生成测试报告,确保每个页面的测试结果及时记录
## 4.3功能交互测试清单
- **查询/搜索功能**:如页面存在查询按钮或搜索框,必须执行查询操作并验证结果
- **数据列表加载**:验证页面数据是否正常加载和显示
- **分页功能**(如适用):点击分页控件,验证分页切换是否正常
- **排序功能**(如适用):如列表支持排序,验证排序功能是否正常
- **筛选功能**(如适用):如页面包含筛选条件,验证筛选功能是否正常
## 4.4页面验证标准流程
### 4.4.1内容验证标准流程
- **页面完整性检查**:确认页面内容是否完整加载,无空白页面,无内容缺失
- **网络请求验证**:检查页面是否触发了预期的网络请求,确保无缺失或异常请求
- **错误信息检测**:检查页面是否显示系统错误提示或异常信息(如"加载失败"、"网络错误"等提示)
- **布局验证**:确认页面布局是否正常(无错位、重叠、溢出等问题)
### 4.4.2网络请求监控
- **错误请求捕获**:过滤并记录所有HTTP状态码≥400的请求,重点关注404、500、503、504等严重错误
- **响应超时记录**:监控并记录所有响应时间超过3秒的网络请求,标记为性能优化关注点
- **资源大小评估**:监控单个资源的大小,对超过1MB的资源进行详细分析和标记,标记为资源优化关注点。
- **重点错误标记**:特别记录404(资源未找到)、500(服务器错误)等严重错误的请求URL和响应内容
- **请求详情记录**:记录异常请求的方法、关键请求头和简要请求体信息
- **无CORS错误**:跨域请求正常,无跨域资源共享错误
- **HTTPS安全**:无混合内容警告(HTTP资源在HTTPS页面中)
### 4.4.3控制台错误分析
- **日志分类捕获**:仅捕获并记录控制台警告(Warn)和错误(Error)日志,其他日志类型(如信息(Info)、调试(Debug)等)不记录
- **异常重点标记**:重点记录JavaScript未处理异常、资源加载失败等关键错误
- **日志留存**:仅留存控制台警告(Warn)和错误(Error)日志,其他日志类型不留存
### 4.4.4性能指标评估
- **加载时间记录**:使用Performance API记录准确的页面加载时间(从点击到DOMContentLoaded完成)
- **性能阈值标记**:对加载时间超过3秒的页面标记为性能优化关注点
- **资源大小监控**:记录页面关键资源大小,对超过1MB的资源进行详细分析和标记
- **性能瓶颈识别**:识别导致性能问题的具体资源(慢资源、大资源)
### 4.4.5 页面截图
- **页面截图**:使用Chrome DevTools的截图功能,对当前页面进行完整截图,确保包含页面的所有可视内容
- **截图命名**:截图文件命名为`[菜单名称.png]`,确保文件名清晰且易于识别
- **截图路径**:使用相对路径 `/report/screenshots/[菜单名称.png]`(工作目录为项目根目录)
- **截图存档**:将截图保存至项目目录下的`/report/screenshots`文件夹中,确保路径正确且文件可访问
- **截图验证**:截图后必须验证文件是否成功保存,如果失败则使用绝对路径重试,确保每个测试条目都有对应的截图文件
# 5.页面测试报告规范
- **报告命名格式**:`/report/[测试报告_菜单名称].md`
- **测试时间**:必须填写实际测试时间,格式为YYYY-MM-DD HH:MM:SS,不要使用模板字符串
- **表格格式**:网络请求分析和控制台日志分析部分必须严格使用表格格式
- **无数据处理**:如果某个部分没有数据,请按照模板中提供的方式填写"无",不要留空
- **内容完整性**:确保所有必填字段都已填写,不要遗漏任何章节或段落
- **截图存档**:确保页面截图已保存并提供正确的相对文件路径
## 5.1 测试报告一致性
严格遵循**测试报告模板**进行结构化输出,**禁止添加任何模板外的自定义内容**。所有章节标题、编号、表格格式、截图及占位符的使用方式均须与模板保持完全一致。
1. 严格按照模板中的7个章节结构输出,章节标题必须为:
- `## 1. 基本信息`
- `## 2. 测试结果概览`
- `## 3. 网络请求分析`
- `## 4. 控制台日志分析`
- `## 5. 页面性能分析`
- `## 6. 页面内容与布局验证`
- `## 7. 测试结论与优化建议`
2. 所有表格格式必须与模板完全一致,包括列标题、分隔符等
3. 对于无数据的情况,严格按**测试报告模板**示例的"无 | 无 | 无 | 无 | 无 | 无"等格式填写
4. **禁止添加任何模板外的自定义内容**
5. 所有占位符(如测试时间、URL、数值等)必须替换为实际测试数据
## 5.2测试报告模板
```markdown
# 测试报告:[页面名称]
## 1. 基本信息
- **测试执行时间**:[YYYY-MM-DD HH:MM:SS]
- **页面访问路径**:[菜单名称]
- **目标页面URL**:[完整访问链接]
- **测试环境配置**:Chrome [版本号] / Windows 10 专业版 / 1920×1080分辨率
- **测试耗时**:[X]秒
## 2. 测试结果概览
- **总体状态**:通过 / 不通过
- **页面加载性能**:[X]秒(正常≤3秒 / 超时>3秒)
- **核心功能验证**:
- 查询功能执行[成功/失败](若适用)
- 数据加载[成功/失败](若适用)
- 其他功能验证结果[成功/失败](若适用)
## 3. 网络请求分析
- **请求统计**:总请求[X]个 | 成功[X]个 | 失败[X]个
- **错误请求详情**:
| HTTP状态码 | 请求方法 | 完整URL | 请求时间 | 错误原因描述 | 影响范围 |
|------------|----------|---------|----------|--------------|----------|
| [HTTP状态码] | [请求方法] | [完整URL] | [YYYY-MM-DD HH:MM:SS] | [错误原因描述] | [数据加载/功能模块等] |
| 404 | GET | https://example.com/api/data | 2023-10-26 14:30:22 | 资源路径不存在 | 人员列表数据加载 |
| 无 | 无 | 无 | 无 | 无 | 无 |
- **超时请求详情**:
| 瓶颈类型 | 请求URL | 请求方法 | 耗时(秒) | 超时阈值 | 影响范围 |
|----------|---------|----------|----------|----------|----------|
| 慢请求 | [完整URL] | [GET/POST等] | [X] | 3秒 | [数据加载/表格渲染等] |
| 无 | 无 | 无 | 0 | 3秒 | 无超时请求 |
- **资源太大响应详情**:
| 瓶颈类型 | 资源类型 | 资源URL | 大小(MB) | 阈值(MB) | 影响范围 |
|----------|----------|---------|----------|----------|----------|
| 大资源 | [资源类型] | [完整URL] | [X] | 1 | [数据加载/表格渲染等] |
| 无 | 无 | 无 | 0 | 1 | 无大资源请求 |
## 4. 控制台日志分析
- **错误日志**:共[X]条(严重[X]条 | 一般[X]条)
| 错误类型 | 错误内容摘要 | 影响范围 | 建议处理优先级 |
|----------|--------------|----------|----------------|
| [错误类型] | [具体错误文本摘要] | [相关功能模块/页面功能] | [高/中/低] |
| 无 | 无 | 无 | 无 |
- **警告日志**:共[X]条
| 警告类型 | 警告内容摘要 | 影响范围 | 建议处理优先级 |
|----------|--------------|----------|----------------|
| [警告类型] | [具体警告文本摘要] | [相关功能模块/性能指标] | [高/中/低] |
| 无 | 无 | 无 | 无 |
## 5. 页面性能分析
- **页面加载时间**:[X]秒(正常≤3秒 / 超时>3秒)
- **性能评估结果**:正常 / 需优化(超过3秒阈值)
- **关键性能指标**:
| 性能指标 | 数值 | 阈值 | 评估结果 | 说明 |
|----------|------|------|----------|------|
| DOMContentLoaded | [X]秒 | ≤3秒 | [正常/超时] | 页面DOM加载完成时间 |
| 首次内容绘制(FCP) | [X]秒 | ≤1.8秒 | [正常/超时] | 首次内容渲染时间 |
| 最大内容绘制(LCP) | [X]秒 | ≤2.5秒 | [正常/超时] | 最大内容元素渲染时间 |
- **性能瓶颈分析**:
| 瓶颈类型 | 资源URL | 资源类型 | 大小(MB) | 加载时间(秒) | 影响范围 |
|----------|---------|----------|----------|--------------|----------|
| [慢资源/大资源] | [完整URL] | [资源类型] | [X] | [X] | [页面渲染/交互响应等] |
| 无 | 无 | 无 | 0 | 0 | 无性能瓶颈|
## 6. 页面内容与布局验证
- **内容完整性**:完整加载 / 部分缺失(缺失元素:[列表]) / 完全空白
- **布局显示**:正常 / 异常(异常描述:[元素错位/重叠/溢出等具体现象])
- **功能交互验证**:
- 查询功能:[成功/失败/不适用](失败原因:[如有])
- 数据加载:[成功/失败/不适用](失败原因:[如有])
- 其他功能:[测试结果](若适用)
- **页面截图**:

截图存档路径:screenshots/[菜单名称].png
## 7. 测试结论与优化建议
- **结论摘要**:[通过/不通过原因简述,如"页面加载超时且存在404资源错误"]
- **修复建议**:
1. [优先级高] [具体问题]:[技术解决方案]
2. [优先级中] [性能问题]:[优化方向建议]
3. [优先级低] [其他问题]:[优化建议](若适用)
- **风险提示**:[如"该页面错误可能导致用户无法查看关键数据"]
- **测试异常说明**:[如有测试中断、重试等情况,需在此说明]
```
# 6.测试质量保证
- **测试完整性**:确保每个页面都执行了完整的测试流程,不遗漏任何验证项
- **报告准确性**:确保测试报告中的数据准确反映实际测试结果
- **问题可追溯性**:确保所有发现的问题都有详细的记录,包括错误信息、影响范围等
- **测试一致性**:确保所有页面的测试标准和报告格式保持一致
使用自然语言与mcp对话
提前生成菜单列表提示词(如果直接要AI分析菜单,会出现会话上下文爆炸)
获取用户输入的树形菜单数据结构文件,生成一个结构化测试进度表格。
树形菜单数据结构文件包含多级菜单:
- 如果菜单项的 url 为空字符串或存在 children 数组(表示有子菜单),则为菜单目录,无需生成测试行
- 如果菜单项的 url 不为空且 children 为空数组,则为可访问的页面,需要生成测试行
请按照以下要求生成表格:
1. 菜单名称 :按层级结构拼接,格式为 [一级菜单]-[二级菜单]-[三级菜单]-[...]-[页面名称]
2. URL :使用基础地址 https://smart.saas.vppark.cn/ 与菜单项的 url 字段组装完整可访问地址,需特别处理:
- 如果菜单项的 url 以 / 开头,则直接拼接(避免重复)
- 如果菜单项的 url 不以 / 开头,则添加 / 后再拼接
- 最终 URL 应符合 Vue 项目 hash 模式的访问格式
3. 测试状态 :[进行中/已完成],默认为: --
4. 开始时间 :yyyy-MM-dd HH:mm:ss,默认值为:--
5. 完成时间 :yyyy-MM-dd HH:mm:ss,默认值为:--
6. 测试结果 :[通过/未通过],默认值为:--
请确保表格覆盖文件中所有符合条件的页面菜单项,不要遗漏任何层级。
生成菜单列表
根据树形结构@全局测试/nav.json ,按照@全局测试/生成菜单列表.md 要求,生成测试进度.md
编写开始测试提示词
严格按照 `global.md` 文件中规定的测试规范、操作流程,对 `系统菜单测试进度.md` 文档中的每个条目执行以下操作:
## 测试范围
- 仅测试"测试状态"字段为 `--` 的条目(跳过已完成的条目)
- 如果所有条目都需要重新测试,则测试所有条目
## 测试执行流程
1. **逐项执行完整测试流程**,包括:
- 测试环境准备(打开浏览器、登录等)
- 测试用例执行(页面访问、功能交互、验证等)
- 结果记录和问题跟踪
2. **测试报告生成**:
- 每完成单个条目的测试后,立即按`global.md`中的`页面测试报告规范`生成结构化测试报告
- 报告格式必须严格遵循`global.md`中的测试报告模板,包含7个章节
3. **测试结果回写**:
将测试结果实时回写到 `./系统菜单测试进度.md` 文件中对应条目的指定字段,确保:
- **测试状态字段**:更新为"进行中"(测试开始时)/ "已完成"(测试完成时)
- **开始时间字段**:填写测试开始执行的时间戳(格式:YYYY-MM-DD HH:mm:ss)
- **完成时间字段**:填写测试完成执行的时间戳(格式:YYYY-MM-DD HH:mm:ss)
- **测试结果字段**:填写测试执行结果,格式为:
- 通过:`✅ [简要描述,如"页面正常加载,查询功能正常"]`
- 失败:`❌ [失败原因描述]`
- 阻塞:`⛔ [阻塞原因描述]`
- 保持原始文档的Markdown表格结构完整,仅修改指定字段内容
- 每次更新后立即保存文档变更,确保进度文件始终反映最新测试状态
4. **测试异常处理**:
- 如遇到页面无法访问、登录失败等情况,将测试状态标记为"阻塞",并在测试结果中说明原因
- 如测试过程中出现网络超时(超过30秒),记录为失败,继续执行后续测试
- 所有异常情况都应在测试报告中详细记录
5. **测试规范一致性**:
- 每次开始新条目测试前(包括多轮测试场景),必须重新核对`global.md`中的测试规范、操作流程及报告模板要求
- 确保每轮测试使用的报告格式与最新规范完全一致
- 严格按照`global.md`中的功能交互测试清单执行测试
开始测试
`开始测试输入语句.md` 根据要求对 `巡检任务管理` 进行测试
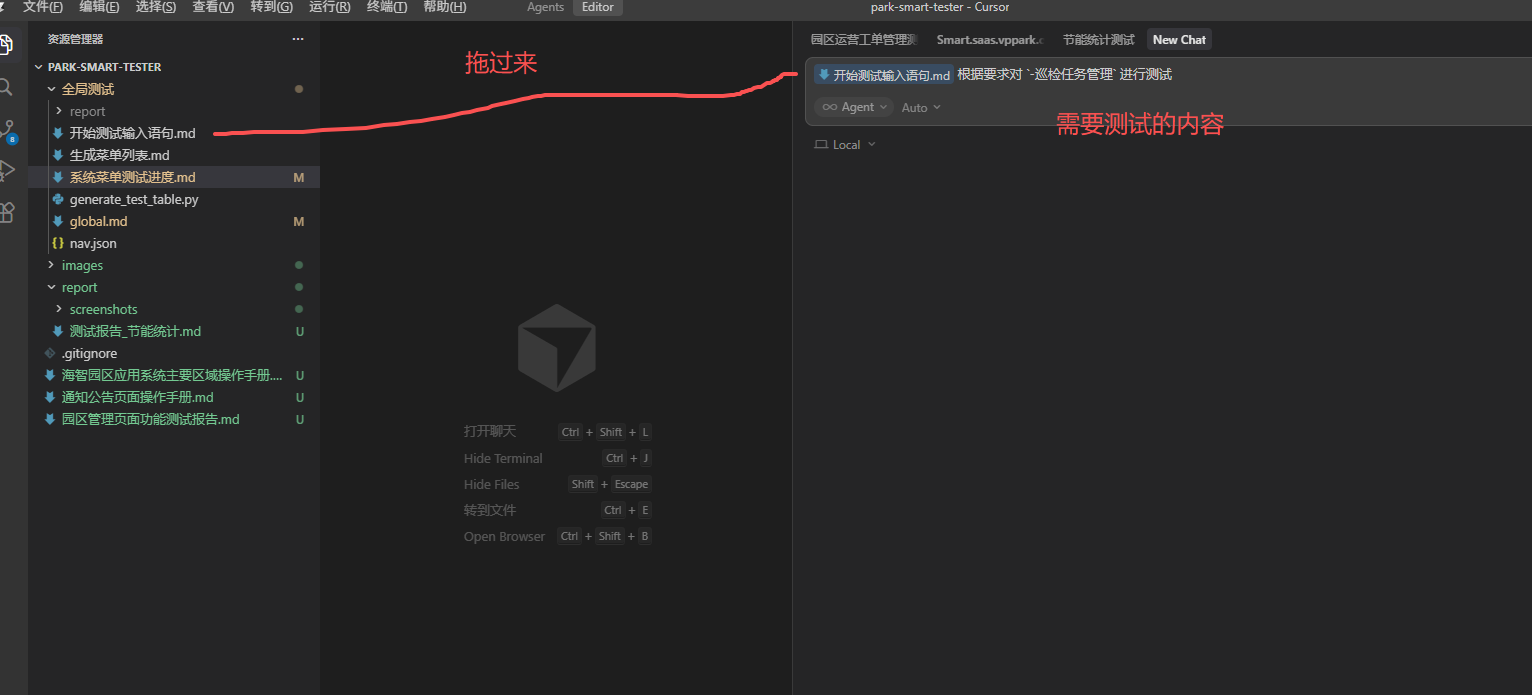
测试报告样例
使用chrome devtools mcp一键将所有页面都点击一次
- 下载和安装cursor
- 设置chrome devtools mcp
- 编写提示词
小坑
要保证正确掉起chrome devtools mcp ,得保证ide上安装的插件已经正常加载了
生成菜单列表
获取用户输入的树形菜单数据结构文件,生成一个结构化测试进度表格。
树形菜单数据结构文件包含多级菜单:
- 如果菜单项的 url 为空字符串或存在 children 数组(表示有子菜单),则为菜单目录,无需生成测试行
- 如果菜单项的 url 不为空且 children 为空数组,则为可访问的页面,需要生成测试行
请按照以下要求生成表格:
1. 菜单名称 :按层级结构拼接,格式为 [一级菜单]-[二级菜单]-[三级菜单]-[...]-[页面名称]
2. URL :使用基础地址 https://smart.saas.vppark.cn/ 与菜单项的 url 字段组装完整可访问地址,需特别处理:
- 如果菜单项的 url 以 / 开头,则直接拼接(避免重复)
- 如果菜单项的 url 不以 / 开头,则添加 / 后再拼接
- 最终 URL 应符合 Vue 项目 hash 模式的访问格式
3. 测试状态 :[进行中/已完成],默认为: --
4. 开始时间 :yyyy-MM-dd HH:mm:ss,默认值为:--
5. 完成时间 :yyyy-MM-dd HH:mm:ss,默认值为:--
6. 测试结果 :[通过/未通过],默认值为:--
请确保表格覆盖文件中所有符合条件的页面菜单项,不要遗漏任何层级。
规则文件
https://iovhm.com/book/attachments/19
开始测试语句
严格按照 `global.md` 文件中规定的测试规范、操作流程,对 `系统菜单测试进度.md` 文档中的每个条目执行以下操作:
## 测试范围
- 仅测试"测试状态"字段为 `--` 的条目(跳过已完成的条目)
- 如果所有条目都需要重新测试,则测试所有条目
## 测试执行流程
1. **逐项执行完整测试流程**,包括:
- 测试环境准备(打开浏览器、登录等)
- 测试用例执行(页面访问、功能交互、验证等)
- 结果记录和问题跟踪
2. **测试报告生成**:
- 每完成单个条目的测试后,立即按`global.md`中的`页面测试报告规范`生成结构化测试报告
- 报告格式必须严格遵循`global.md`中的测试报告模板,包含7个章节
3. **测试结果回写**:
将测试结果实时回写到 `./系统菜单测试进度.md` 文件中对应条目的指定字段,确保:
- **测试状态字段**:更新为"进行中"(测试开始时)/ "已完成"(测试完成时)
- **开始时间字段**:填写测试开始执行的时间戳(格式:YYYY-MM-DD HH:mm:ss)
- **完成时间字段**:填写测试完成执行的时间戳(格式:YYYY-MM-DD HH:mm:ss)
- **测试结果字段**:填写测试执行结果,格式为:
- 通过:`✅ [简要描述,如"页面正常加载,查询功能正常"]`
- 失败:`❌ [失败原因描述]`
- 阻塞:`⛔ [阻塞原因描述]`
- 保持原始文档的Markdown表格结构完整,仅修改指定字段内容
- 每次更新后立即保存文档变更,确保进度文件始终反映最新测试状态
4. **测试异常处理**:
- 如遇到页面无法访问、登录失败等情况,将测试状态标记为"阻塞",并在测试结果中说明原因
- 如测试过程中出现网络超时(超过30秒),记录为失败,继续执行后续测试
- 所有异常情况都应在测试报告中详细记录
5. **测试规范一致性**:
- 每次开始新条目测试前(包括多轮测试场景),必须重新核对`global.md`中的测试规范、操作流程及报告模板要求
- 确保每轮测试使用的报告格式与最新规范完全一致
- 严格按照`global.md`中的功能交互测试清单执行测试
vscode开发java的必要设置
安装插件
如果trae和cursor中没有你要的插件,可以去vscode市场看看。
为cursor和trae安装vscode插件: https://iovhm.com/book/books/bbcbf/page/traecursorvscode
- 快捷键映射:IntelliJ IDEA Keybindings,https://marketplace.visualstudio.com/items?itemName=k--kato.intellij-idea-keybindings
- xml格式化:XML,https://marketplace.visualstudio.com/items?itemName=redhat.vscode-xml
- Spring Boot Extension Pack:https://marketplace.visualstudio.com/items?itemName=vmware.vscode-boot-dev-pack
消除警告
// 警告:Result is a raw type. References to generic type Result<T> should be parameterizedJava(16777788)
// vi .vscode\settings.json
// 需要重启IDE
{
"java.compile.args": "-Xlint:-rawtypes"
}
vscode常用插件
- 快捷键映射:IntelliJ IDEA Keybindings,https://marketplace.visualstudio.com/items?itemName=k--kato.intellij-idea-keybindings
- 简易http服务器,Live Server,https://marketplace.visualstudio.com/items?itemName=ritwickdey.LiveServer
- xml格式化:XML,https://marketplace.visualstudio.com/items?itemName=redhat.vscode-xml
- shell-format,https://marketplace.visualstudio.com/items?itemName=foxundermoon.shell-format
java开发支持
- Extension Pack for Java,https://marketplace.visualstudio.com/items?itemName=vscjava.vscode-java-pack
- Spring Boot Extension Pack:https://marketplace.visualstudio.com/items?itemName=vmware.vscode-boot-dev-pack
vue开发支持
AI辅助编程
索引
- AI启程
- AI之初体验(java),持续更新中
- AI之初体验(前端),持续更新中
step1 先决条件,科学上网,插件选择
经过试用,阿里的通义灵码和github copilot 是当前效果比较好的两个插件。阿里的通义灵码不需要科学上网,copilot需要科学上网。
科学上网请参考,https://iovhm.com/book/books/cee63/page/9872e。
step2 安装插件
idea(java方向)
截止至2024年2月28日,github Copilot 暂时不支持idea 内联聊天,但是可以支持代码生成。需要idea2023版本以上。
要获得github Copilot的体验权限,请向直属项目经理申请
不建议同时安装通义灵码和Copilot,可能产生冲突
- 安装插件
依次点击 file -> settings - > plugins 搜索 tongyi 和 github copilot 进行安装
- github copilot 插件安装
- 通义灵码插件安装
- 登录账号(github copilot)
需要用到您的个人github账号,请自行至github注册,请使用企业邮箱注册,并将用户名设置为姓名拼音,如果用户名被占用,可以加上后缀vp ,例如 youname-vp,要开通github copilot使用权限,请向直属项目经理申请
- 登录账号(通义灵码)
需要用到您的个人阿里云账号,请自行至阿里云注册
- idea科学设置(非必须)
github 可能时不时抽风,需要对IDEA进行设置。依次点击 file > settings > Appearance & Behavior > System settings > HTTP Proxy ,填入你的科学上网设置
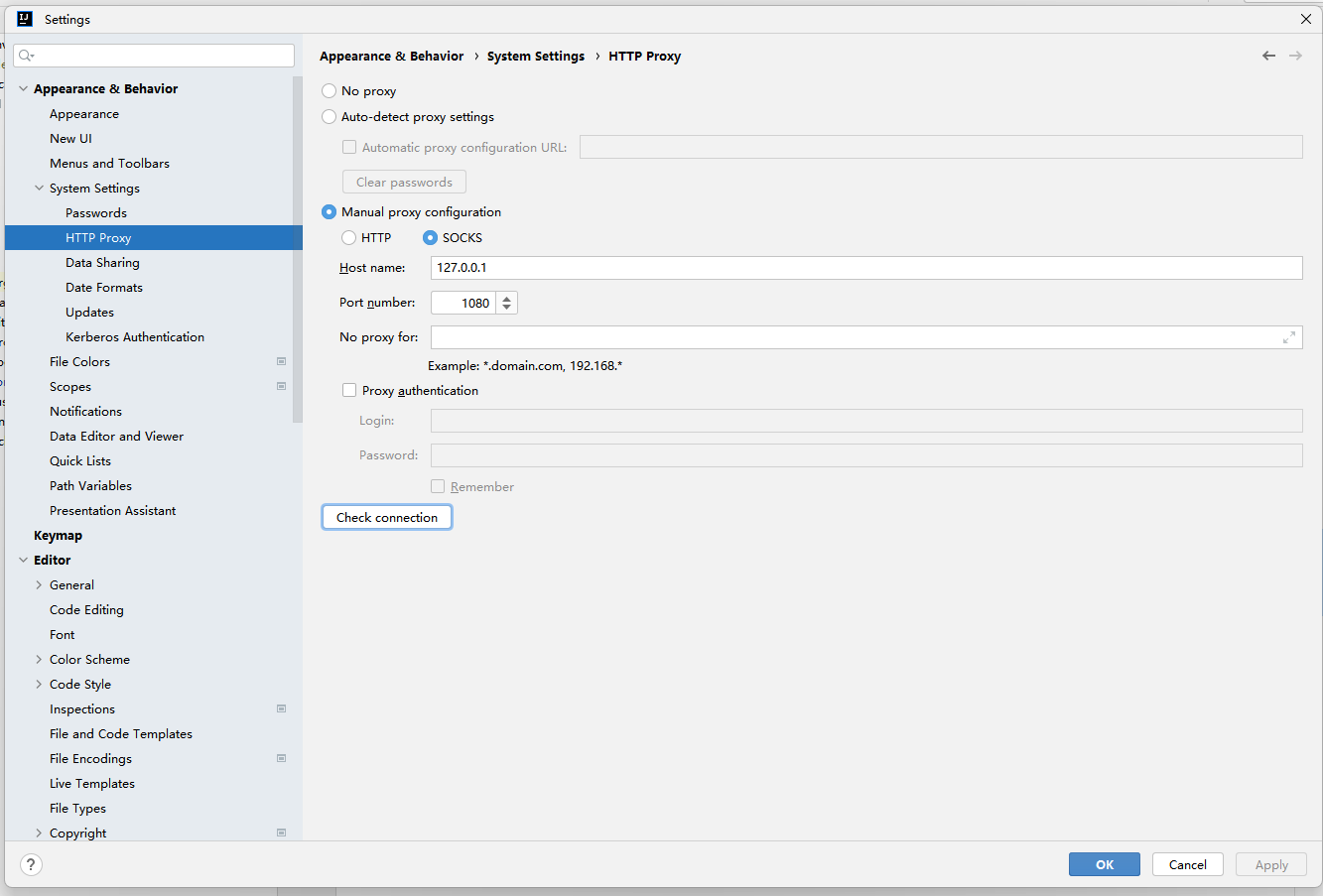
- 再次确认插件是否生效
对插件进行设置和开启/关闭一些功能
vscode(前端方向)
点击左侧扩展图标,搜索tongyi和 github copilot
- github copilot 插件安装
- 通义灵码插件安装
- 登录账号(github copilot)
插件安装完成后,会在左侧多出对应的图标,点击相关图标既可使用对应的功能。
- 登录账号(通义灵码)
插件安装完成后,会在左侧多出对应的图标,点击相关图标既可使用对应的功能。
直接使用网页版chatgpt
网址:https://chat.openai.com/,需要魔法科学上网,openai需要登录,请自行注册。请使用gmail,hotmail邮箱注册,尽量不要使用国内的邮箱,以免被封
cline&&AI编程插件
vscode 插件安装
使用千问
插件面板搜索cline,可以看到有英文版和中文版
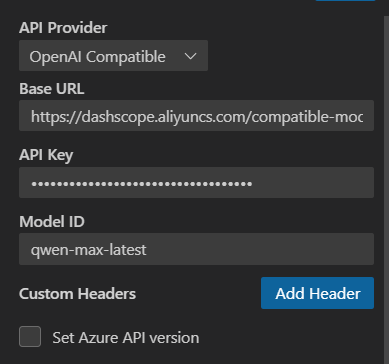
https://dashscope.aliyuncs.com/compatible-mode/v1
- qwen3-coder-plus
- deepseek-r1
- deepseek-v3.2
- qwen3-vl-plus
使用kimi
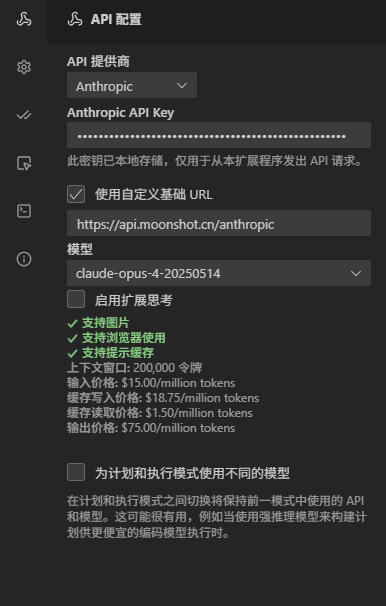
- API Provider:Anthropic
- https://api.moonshot.cn/anthropic
- claude-opus-4-20250514
dify 1.13.2 安装部署 && vplark
架构示意图
安装
下载最新版:https://github.com/langgenius/dify/releases
修改docker-compose.yaml被墙的镜像地址
- init_permissions
- api
- worker
- worker_beat
- web
- db_postgres (非必须,取决于你使用什么数据库)
- db_mysql (非必须,取决于你使用什么数据库)
- redis
- sandbox
- plugin_daemon
- ssrf_proxy
- nginx
- weaviate (非必须,取决于你使用什么向量库)
- opensearch (非必须,取决于你使用什么向量库)
- opensearch-dashboards (非必须,取决于你使用什么向量库)
如果使用opensearch但是没有修改其他配置、想使用一键启动
修改 opensearch 、 opensearch-dashboards
networks:
- opensearch-net
- default # if you want to access opensearch from other services, you need to add it to the default network.
启动命令
# 使用mysql和opensearch
docker-compose --profile mysql --profile opensearch up -d
# 默认
docker-compose --profile postgresql --profile weaviate up -d
# 2026年4月14日,修改了.env配置文件,可以一键启动
编写配置文件
.env
CONSOLE_API_URL=
CONSOLE_WEB_URL=
SERVICE_API_URL=
APP_API_URL=
APP_WEB_URL=
FILES_URL=
# 对外公布的服务端口
EXPOSE_NGINX_PORT=80
EXPOSE_NGINX_SSL_PORT=443
# 是否开启检查版本策略,若设置为 false,则不调用 https://updates.dify.ai 进行版本检查。
# 由于目前国内无法直接访问基于 CloudFlare Worker 的版本接口,
# 设置该变量为空,可以屏蔽该接口调用
CHECK_UPDATE_URL=
# Python pip 镜像源地址,用于加速 Python 包下载
PIP_MIRROR_URL=https://pypi.tuna.tsinghua.edu.cn/simple
# 主数据库,dify自己也需要一个数据库
# Database type, supported values are `postgresql`, `mysql`, `oceanbase`, `seekdb`
DB_TYPE=mysql
# For MySQL, only `root` user is supported for now
DB_USERNAME=root
DB_PASSWORD=difyai123456
DB_HOST=db_mysql
DB_PORT=3306
DB_DATABASE=dify
# 向量数据库配置,可选值有:weaviate 、 opensearch
# VECTOR_STORE=weaviate
VECTOR_STORE=opensearch
# Weaviate 端点地址,如:http://weaviate:8080
# WEAVIATE_ENDPOINT=http://weaviate:8080
# 连接 Weaviate 使用的 api-key 凭据
# WEAVIATE_API_KEY=WVF5YThaHlkYwhGUSmCRgsX3tD5ngdN8pkih
OPENSEARCH_HOST=opensearch
OPENSEARCH_PORT=9200
OPENSEARCH_SECURE=true
OPENSEARCH_VERIFY_CERTS=true
OPENSEARCH_AUTH_METHOD=basic
OPENSEARCH_USER=admin
OPENSEARCH_PASSWORD=admin
# Docker Compose profiles - 自动根据 VECTOR_STORE 和 DB_TYPE 启动对应服务
# 22026年4月14日,修改了.env配置文件,可以一键启动对应的向量数据库和主数据库服务,无需再手动指定profile参数。
COMPOSE_PROFILES=${VECTOR_STORE},${DB_TYPE}
openclaw&&个人AI助理
版本提示(最新版本并不一定是最稳定版)
npm view openclaw versions
# 验证过的稳定版
- 2026.4.24
- 2026.4.15
- 2026.4.2
- 2026.3.28
- 2026.3.13
高级用法
# 增加一个agent
# openclaw 类似提供了一个工作场所,agent就是一个一个数字员工,独立的agent可以不干涉记忆
# 名称不支持中文
openclaw agents add park-qianshitong-cool --workspace "D:\招投标项目\千视通-冷链物流园园区"
# agent 列表
openclaw agents
# 删除一个agent
openclaw agents delete work
# 切换智能体
/agent main
# 切换到某个会话(记忆)继续
/session
基础安装
需要先安装nodejs和git
- https://nodejs.org/en/download
- https://git-scm.com/install/windows
- https://www.python.org/downloads/
一键安装常用python包
openclaw在处理文档的时候经常需要一些包,提前安装可以加快处理速度。
pip install requests pyyaml json5 python-dotenv click rich tqdm openpyxl pandas xlrd xlwt numpy matplotlib seaborn python-docx PyPDF2 pdfplumber beautifulsoup4 lxml chardet charset-normalizer docx2txt xlsxwriter pdf2image pikepdf pymupdf markdown Pillow markitdown[all] -i https://pypi.tuna.tsinghua.edu.cn/simple
安装openclaw
# 安装
npm install -g openclaw@2026.4.2 --registry https://registry.npmmirror.com
# 更新
# 直接重新安装
# 运行安装向导
openclaw onboard
# https://dashscope.aliyuncs.com/compatible-mode/v1
# glm-5.1 (推荐)
# deepseek-v4-pro
# qwen3.6-plus (推荐)
# kimi-k2.6 (推荐)
# MiniMax-M2.5
# deepseek-v3.2
# qwen3-coder-plus
# qwen3-vl-plus
# deepseek-r1
# 运行网关程序(前台)
openclaw gateway run
# 运行网关程序(后台)
# 打开web聊天窗口(不推荐)
openclaw dashboard
# 打开控制台聊天窗口(推荐)
openclaw tui
# 卸载
openclaw uninstall
修改配置
~/.openclaw/openclaw.json
# glm-5.1
"contextWindow": 202000
"maxTokens": 128000
# glm-5
"contextWindow": 198000
"maxTokens": 16000
# deepseek-v4-pro
"contextWindow": 1000000
"maxTokens": 384000
# kimi-k2.6
"contextWindow": 256000
"maxTokens": 16000
# kimi-k2.5
"contextWindow": 256000
"maxTokens": 16000
# qwen3.6-plus
"contextWindow": 1000000
"maxTokens": 64000
# qwen3.5-plus
"contextWindow": 1000000
"maxTokens": 64000
# MiniMax-M2.5
"contextWindow": 200000
"maxTokens": 128000
# qwen3-vl-plus
"contextWindow": 256000
"maxTokens": 32000
# qwen3-coder-plus
"contextWindow": 1000000
"maxTokens": 64000
# deepseek-v3.2
"contextWindow": 128000
"maxTokens": 64000
# deepseek-r1
"contextWindow": 128000
"maxTokens": 16000
开始使用
- 测试配置是否正确
你是谁。
我是谁。
工作空间主要文件说明
AGENTS.md - 工作空间指南
SOUL.md - 我的身份定义
USER.md - 用户信息
TOOLS.md - 工具配置
MEMORY.md - 长期记忆
IDENTITY.md - 身份定义
HEARTBEAT.md - 心跳配置
WORKFLOW_AUTO.md - 工作流程协议
- 定义身份(或者直接修改IDENTITY.md、USER.md)
你是谁?你是"董列涛的个人助理",姓名是"董列涛的个人助理",你将以简体中文与与用户交流。你擅长将粗糙、不完整、描述模糊的企业信息化系统功能清单(设计说明书)转化为完整、闭环、可验证的开发规格文档,并输出工时和成本评估
我是谁?我是"董列涛",你称呼我为"董列涛"。
- 重置工作空间(或者直接删除工作空间目录的所有文件但是保留之前的8个初始化文件)
将工作空间清理到初始状态,删除所有历史文件
高级用法
# 显示技能里列表,便于使用的时候直接使用技能
openclaw skills list
现在正在使用的技能
# 开始新会话
/new
# 指定技能
/skill name
使用mcp
# 显示mcp
openclaw mcp list
手工修改 ~/.openclaw/openclaw.json
"mcp": {
"servers": {
"chrome-devtools": {
"command": "npx",
"args": [
"-y",
"chrome-devtools-mcp@latest"
]
}
}
}
连接到QQ
访问https://q.qq.com,创建聊天机器人
openclaw plugins install @tencent-connect/openclaw-qqbot@latest
开启openclaw 开启 http 端点
OpenClaw 的网关可以服务当作一个OpenAI兼容网关,调用其中的agent来提供服务
开启gateway http
"gateway": {
"http": {
"endpoints": {
"chatCompletions": {
"enabled": true
}
}
}
}
可用端点
/v1/chat/completions │ POST │ 聊天补全(兼容 OpenAI)
/v1/models │ GET │ 列出可用模型(这个在后面需要用到)
/v1/models/{id} │ GET │ 获取特定模型信息
/v1/embeddings │ POST │ 文本嵌入
/v1/responses │ POST │ OpenClaw 原生响应 API
调用openclaw的agent
获取模型列表
curl --request GET \
--url http://127.0.0.1:18789/v1/models \
--header 'Authorization: Bearer *********************' \
--header 'Content-Type: application/json' \
记住下面ID "id": "openclaw/fly-go", 后面会用到
{
"object": "list",
"data": [
{
"id": "openclaw/main",
"object": "model",
"created": 0,
"owned_by": "openclaw",
"permission": []
},
{
"id": "openclaw/fly-go",
"object": "model",
"created": 0,
"owned_by": "openclaw",
"permission": []
}
]
}
调用聊天补全接口
注意其中的:"user": "user-abc",这是连续会话和记忆的关键
curl --request POST \
--url http://127.0.0.1:18789/v1/chat/completions \
--header 'Authorization: Bearer ****************************' \
--header 'Content-Type: application/json' \
--data '{
"model": "openclaw/custom-skills",
"stream": false,
"user": "user-abc",
"messages": [
{
"role": "user",
"stream":true
"content": "你是谁"
}
]
}'
hermes-agent 智能体
官网 : https://github.com/NousResearch/hermes-agent
安装
windows操作系统需要先安装wsl,mac操作系统可以直接安装
# 显示可用的linux镜像
wsl --list --online
# 安装linux镜像,默认是ubuntu
wsl --install
# 仅下载
wsl --install --web-download
# 进入系统
wsl
# 以root身份进入
wsl -u root
需要python和nodejs
非必须,是网速很慢才这么做
wget https://nodejs.org/dist/v22.22.2/node-v22.22.2-linux-x64.tar.xz
# 可以先下载完成后解压到 /root/.hermes/node
安装和配置
# 安装
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash
# 刷新配置
source ~/.bashrc
# 配置
hermes setup
# 切换模型
hermes model
# 开始对话
hermes
# 开始对话(新版界面)
hermes --tui
# 卸载
hermes uninstall
通过config直接配置
hermes config set model.default deepseek-v4-pro
hermes config set model.provider custom
hermes config set model.base_url https://dashscope.aliyuncs.com/compatible-mode/v1
hermes config set model.api_key sk-xxxxxxxxxxxxxxxxxxxxxxx
# 使用环境变量
# hermes config set model.api_key ${MY_ALI_KEY}
无端抽筋提示上下文太长
model:
default: glm-5.1
max_tokens: 128000 # 最大输出长度
context_length: 202000 # 上下文长度
auxiliary:
compression:
provider: auto
model: ''
context_length: 202000 # 主要是增加这里,应该和模型保持一致
# kimi-k2.6
# max_tokens:16000 ,
# context_length:256000
# glm-5.1
# max_tokens:128000 ,
# context_length:202000
高级应用(独立工作空间)
# 显示工作空间列表
hermes profile list
# 创建一个新的工作空间
# 强烈建议一个新任务创建一个新的工作空间,这样才能隔离和不串记忆
hermes profile create park-smart
# 创建一个新的工作空间 , 从默认配置文件clone配置(推荐,不用反复配置)
hermes profile create park-smart --clone
# 使用某个工作空间
hermes profile use park-smart
# 使用某个工作空间
hermes -p park-smart
# 删除某个工作空间(注意,是真的删除了,不是openclaw那样假删除)
hermes profile delete park-smart
# 回复到某个会话下,在下一个屏幕出现的列表里面用方向键选择一个会话,然后可以回复到该对话下
hermes sessions browse
# 显示会话列表
hermes sessions list
# 删除某个会话
hermes sessions delete 20260421_131633_501fe8
使用技能
# 显示技能列表
hermes skills list
# 安装技能
# hermes的技能可以和openclaw互通,目录在 ~/.hermes/profiles/<workspaces>/skills
# 需要将技能复制到这里
# 对于需要填写配置文件的,(~)目录对应于~/.hermes/profiles/<workspaces>/home
# 使用技能
使用技能 software-pre-design 对 xxx工作清单.xlsx 进行分析
如果需要在windows资源管理器直接访问agent生成的文件
一句话概括就是使用软连接将profiles目录链接到本机磁盘上
# 创建文件夹(wsl的本机磁盘被映射到/mnt目录下)
mkdir -p /mnt/d/hermes-data
# 把工作目录中的文件移走,并删除 /root/.hermes/profiles/ 。注意最终目录文件夹结构
mv /root/.hermes/profiles/ /mnt/d/hermes-data/
# 创建一个软连接,这一步其实可以提前做,先创建软连接,然后再安装或者创建工作空间
ln -s /mnt/d/hermes-data/profiles/ /root/.hermes/profiles
hermes-agent开启http端点
官方帮助:https://hermes-agent.nousresearch.com/docs/user-guide/features/api-server#environment-variables
约束
- 每个profile需要独立开启
修改某个profile项目下的.env文件
GATEWAY_ALLOW_ALL_USERS=true
API_SERVER_ENABLED=true
API_SERVER_PORT=8642
API_SERVER_HOST=0.0.0.0
API_SERVER_KEY=sk-2Pxm5CO1lPxMWrW2ay2UQ8Cihg+VEbMzZIOYmWHJ1ao
# 自定义模型名称
# API_SERVER_MODEL_NAME=vppark/park-smart
或者使用命令行
hermes -p park-smart config set API_SERVER_ENABLED true
hermes -p park-smart config set API_SERVER_PORT 8642
hermes -p park-smart config set API_SERVER_KEY sk-2Pxm5CO1lPxMWrW2ay2UQ8Cihg+VEbMzZIOYmWHJ1ao
hermes -p park-smart config set GATEWAY_ALLOW_ALL_USERS true
hermes -p park-smart gateway run
端点列表
- /v1/chat/completions
- /v1/models
人人框架微服务版开发环境和安装部署
renren微服务框架需要jdk 17 ,nodejs 18+ 请注意版本选择
安装mysql数据库
先安mysql装数据库,并创建两个database,一个用于nacos,一个用于项目,初始化nacos数据结构和数据。
nacos-server-2.2.3 数据库初始化脚本:nacos-2.2.3-mysql-schema.sql
安装部署nacos
官方网址:https://nacos.io/zh-cn/docs/what-is-nacos.html
github地址:https://github.com/alibaba/nacos
github数据库初始化脚本:https://github.com/alibaba/nacos/blob/master/distribution/conf/mysql-schema.sql
# 镜像
# 根据需要,开放8848和9848端口
nacos/nacos-server:v2.2.3
# 设置环境变量
# 系统(集群)启动方式 ,cluster:集群,standalone:单机
MODE: standalone
# 数据库名称
MYSQL_SERVICE_DB_NAME = renren_cloud_nacos
# 数据地址
MYSQL_SERVICE_HOST = 192.168.0.10
# 数据库密码
MYSQL_SERVICE_PASSWORD = <your password>
# 数据库端口
MYSQL_SERVICE_PORT: 33306
# 数据用用户名
MYSQL_SERVICE_USER: root
# 主机模式,ip:ip地址,host:主机名
PREFER_HOST_MODE: ip
# 数据库类型
SPRING_DATASOURCE_PLATFORM: mysql
安装部署redis
version: "3"
services:
redis:
image: redis:6.2.6
restart: always # 自动重启
ports:
- 56301:6379
command: redis-server --appendonly yes --requirepass <your password>
编写Dockerfile
- java项目,包括:renren-admin-server,renren-gateway
FROM openjdk:17
EXPOSE 8080
# VOLUME /tmp
ADD target/renren-admin-server.jar /app.jar
CMD ["java","-jar","/app.jar"]
-
VUE前端项目,包括web-admin
-
nginx.conf
server {
listen 80;
#listen 443 ssl;
server_name localhost;
#charset koi8-r;
#access_log /var/log/nginx/log/host.access.log main;
#ssl_certificate /home/ssl/server.crt;
#ssl_certificate_key /home/ssl/server.key;
root /usr/share/nginx/html;
index index.html;
location / {
# 不缓存首页,解决VUE单页面发版后不生效
add_header Cache-Control "no-cache no-store must-revalidate proxy-revalidate,max-age=0";
add_header Last-Modified $date_gmt;
# 这个有顺序,需要加在后面
etag off;
}
}
- Dockerfile
FROM nginx:latest
EXPOSE 80
COPY ./dist /usr/share/nginx/html
COPY ./nginx/default.conf /etc/nginx/conf.d/default.conf
-
解决浏览器版本缓存不刷新
-
编写push.sh文件
#!/bin/bash
# 登录
docker login -u <your name> -p <your password> swr.cn-south-1.myhuaweicloud.com
# 打包
docker build -t swr.cn-south-1.myhuaweicloud.com/vp-park/park-baseline/<your image name>:v1.0 ./
# 推送
docker push swr.cn-south-1.myhuaweicloud.com/vp-park/park-baseline//<your image name>:v1.0
编写统一配置文件
在k8s新建ConfigMap,然后再java服务中引用配置:增加环境变量,选ConfigMap,选择需要的configMap名称
# 服务地址
nacos_host = nacos-server
# 名字空间
nacos_namespace = public
# 端口
nacos_port = 8848
进一操作请参考rancher使用手册
上传nacos配置文件
打开nacos管理界⾯(http://localhost:8848/nacos) ,初始⽤户名nacos,密码nacos,登录之后,如下所示:
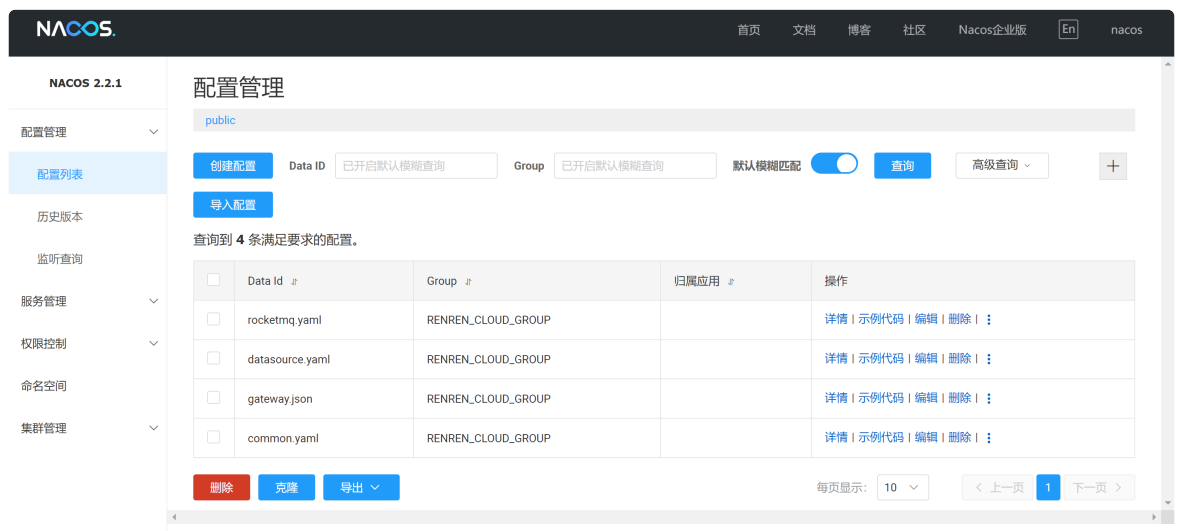
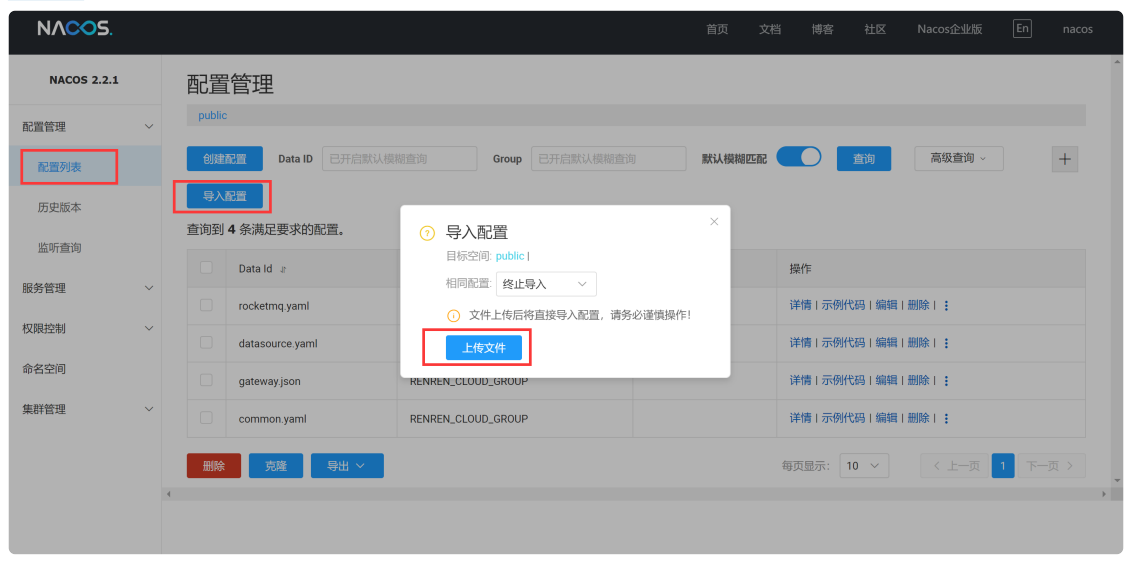
导⼊nacos配置⽂件,配置⽂件在项⽬⾥,⽂件名为:【~/doc/nacos/nacos_config.zip】,如下所示:
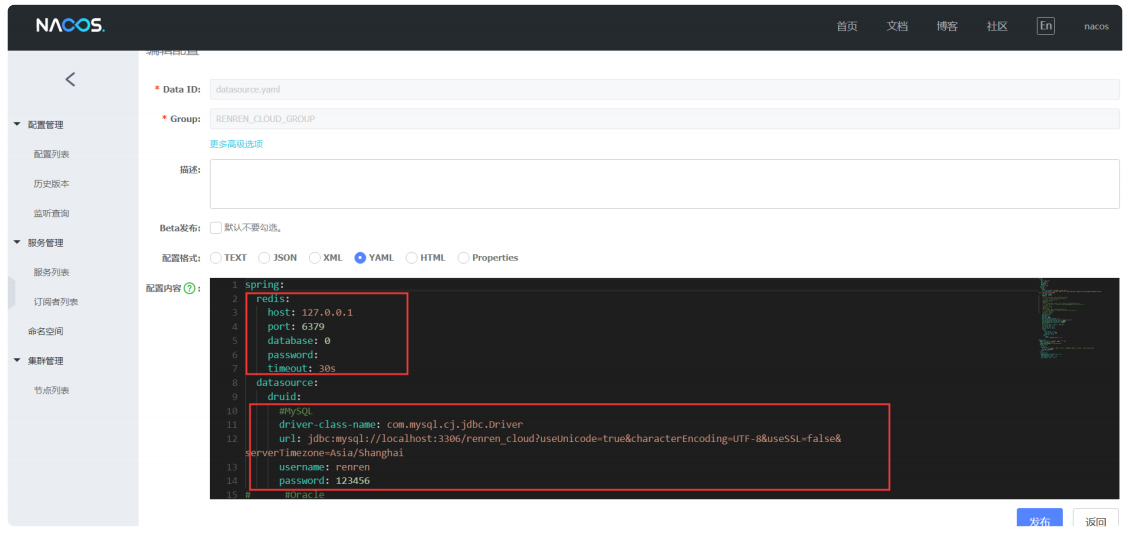
在nacos⾥,还需要修改datasource.yaml,如:redis、MySQL信息,如下所示:
安装部署代码生成器
安装部署代码生成器:人人框架代码生成器安装部署
java后台开发规范
一、循环引用问题
项目中不能出现循环引用,如果确实需要相互引用,必须抽取公共方法
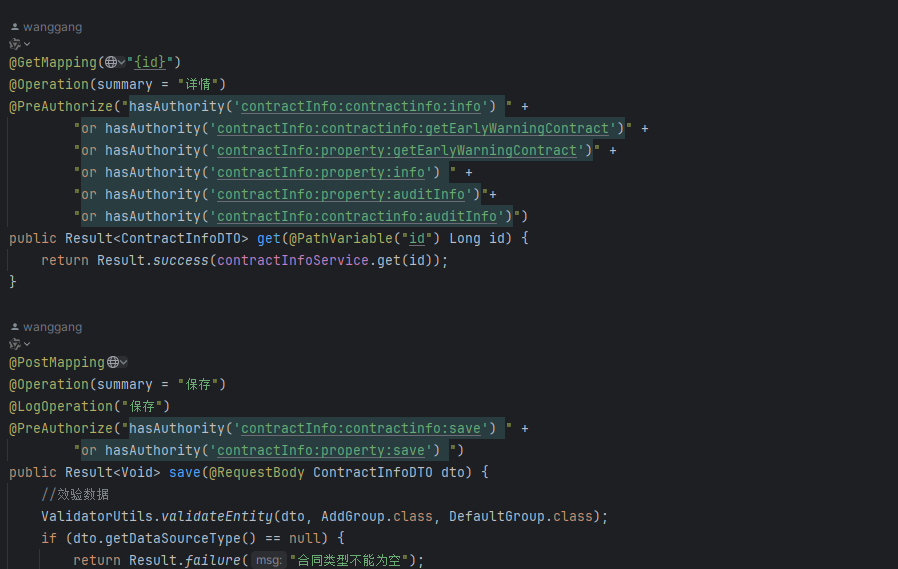
二、授权标识问题
授权标识必须一个按钮,一个授权标识,一个接口被多个按钮使用,授权标识必须分开,当页的列表查询放到当前页面上,如图:
高并发性能优化设置&&tomcat设置
tomcat设置
server:
tomcat:
max-connections: 10000 # 最大连接数,默认值为8192,一般情况下可以不用修改
threads:
max: 1000 # 处理请求最大线程数,默认值是200,既tomcat的默认并发是200
min-spare: 100 # 处理请求的最小空闲线程,即使没有请求需要处理,也保留,以便于快速响应连接请求
accept-count: 100 # 额外的阻塞的处理请求数,当所有线程都在使用,还可以额外接受的请求,并放入请求队列,待有可用线程后立刻处理,一般不超过最大线程数的10%
-
max-connections: 10000:这个参数设置了Tomcat服务器允许的最大连接数。这意味着Tomcat在同一时间最多可以处理10000个客户端连接。这个值应该根据服务器的硬件资源(如CPU、内存)和网络带宽来调整,以确保服务器能够高效稳定地运行。
-
threads: 用于处理请求的线程池的参数。
- max: 1000:线程池中的最大线程数。意味着Tomcat可以同时启动最多1000个线程来处理客户端请求。线程数数量需要考虑服务器的硬件资源。
- min-spare: 100:线程池中保持空闲的最小线程数。即使当前没有那么多请求需要处理,Tomcat也会保持至少100个线程处于空闲状态,以便快速响应突然增加的请求量。
accept-count: 100:当所有可用的处理线程都在使用时,Tomcat能够接受的额外请求的数量,并将这些请求放入队列中等待处理。意味着如果所有的处理线程都在忙,Tomcat还可以接受额外的100个请求,但这些请求需要等待直到有线程变得可用。
连接数与线程数,根据TCP原理,是先建立连接,再处理请求,如果在连接超时后还没有处理请求,则断开连接,例如常见的timeout,socket closed
nginx设置
主要是开启gzip压缩,减少流量
# 开启gzip压缩
gzip on;
# 压缩哪些文件类型
gzip_types text/plain text/css application/json text/javascript application/javascript;
# 最小压缩大小,小于这个大小不压缩,单位是字节
gzip_min_length 1000;
# 压缩率,1-9,数字越大压缩的越好,但是也越消耗CPU
gzip_comp_level 6;
# 是否在http header中添加Vary: Accept-Encoding,建议开启
gzip_vary on;
# 禁止IE6使用gzip,因为这些浏览器不支持gzip压缩
gzip_disable "MSIE [1-6]\.";
# 在特定条件下对代理服务器的响应进行压缩
gzip_proxied expired no-cache no-store private auth;
# 缓冲区数量和大小,设置了16个8KB的缓冲区
gzip_buffers 16 8k;
# 最小http版本,低于这个版本不压缩
gzip_http_version 1.1;
Springboot程序内优化
- 按需返回,返回过多的数据占用内存和带宽
- 嵌套的对象和数组,反序列化的时候嵌套对象占用开销
- 独立的中间件主机:主机资源端口有限,如果全部在一台主机,会占用主机端口和文件描述
jmeter自身优化
- 从jmeter.bat打开软件,而不是直接打开jar
- 修改jmeter.bat增加应用程序堆栈
修改HEAP大小,一般为主机内存的一半
if not defined HEAP (
rem See the unix startup file for the rationale of the following parameters,
rem including some tuning recommendations
set HEAP=-Xms1g -Xmx8g -XX:MaxMetaspaceSize=512m
)
从bat启动时为英文修改

jvm优化
https://iovhm.com/book/books/cee63/page/jvm
代码规范插件
- 进入idea设置
- 查找代码规范插件alibaba java coding guidelines的最近版本,并安装
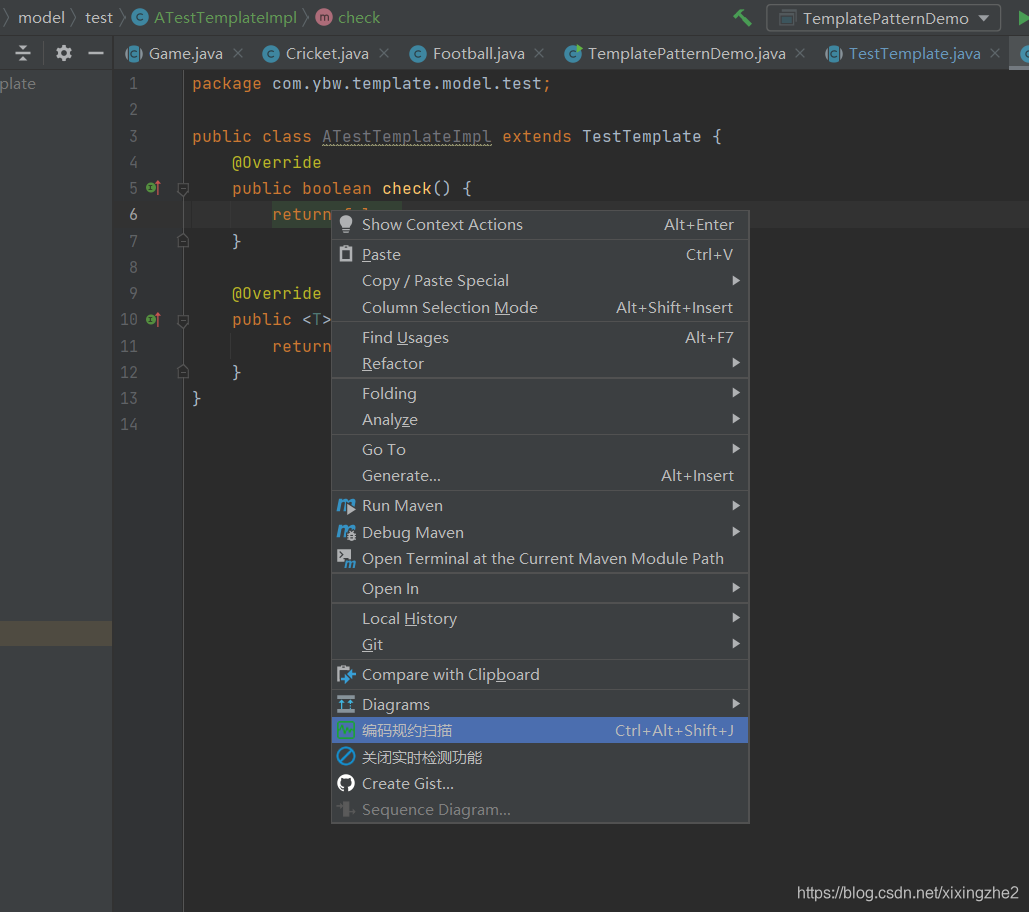
使用参考
- 1 触发扫描,可以通过右键菜单、Toolbar按钮、快捷键三种方式手动触发代码检测。同时结果面板中可以对部分实现了QuickFix功能的规则进行快速修复。
- 2扫描范围,在左侧的Project目录树种点击右键,可以触发对整个工程或者选择的某个目录、文件进行检测。
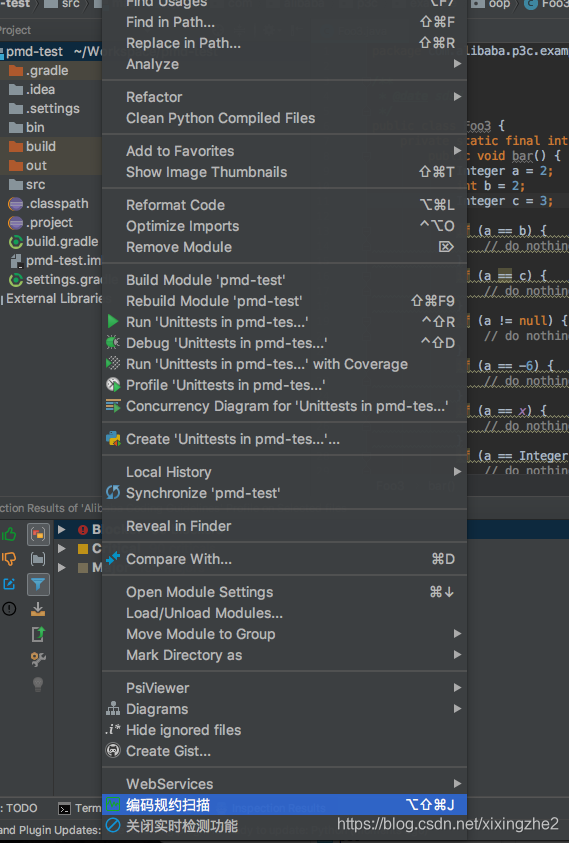
- 3扫描结果 检测结果直接使用IDEA Run Inspection By Name功能的结果界面,插件的检测结果分级为Blocker、Critical、Major。默认按等级分组,方便统计每个级别错误的数量
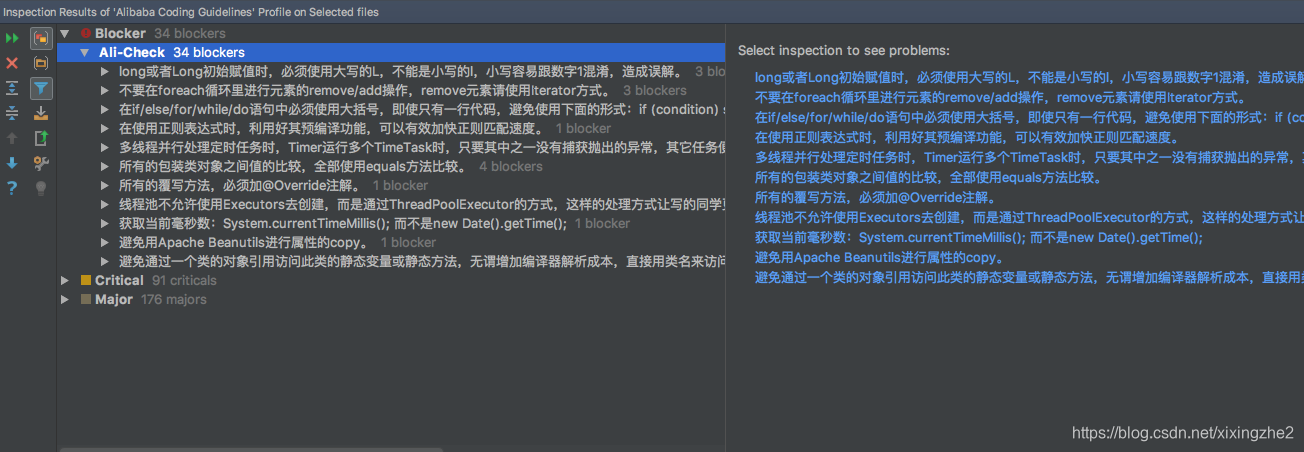
默认情况我们在结果面板需要双击具体违规项才能打开对应的源文件,开启Autoscroll To Source选项,单击面板中的文件名、或者是具体的违规项的时候IDEA会自动打开对应的源文件。
必须处理bug Blocker:阻断块。最严重的错误类型; Critical:严重的错误类型; Major:重要的错误类型; 前两级别是必须要处理掉的。
微服务开发中的一些小工具&&小技巧
稍等,我把配置改成生产上的地址
在微服务开发中,通常涉及多个服务、多个团队、异地团队一起合作开发。又因为频繁迭代,频繁发布版本,为了保证版本、代码、环境的一致性,通常使用容器化,既生产上的运行环境、配置信息应该与测试环境的保持完全一致。但是我们更多的时候会出现测试通过后,还要说:“稍等,我把配置改成生产上的地址”,一个新的的客户部署一套版本,也要“稍等,我把配置改成生产上的地址”,完全丧失了容器化的优势。
穷人的微服务开发环境
如果我们有钞能力,这个问题很好解决,每个研发人员都配置一台服务器,专门用于联调,全部使用标准端口,标准服务名称,每个项目组都配置三套环境。
在没有钞能力的情况下,只能借助不同的端口来区分服务,也正因为如此,团队协作、异地开发、新老项目同时维护,都就会出现配置文件、服务名、IP地址不一致的情况,例如生产上要求的是mysql:3306,redis:6379,测试和开发环境要求的是x.x.x.x:33306,x.x.x.x:63379,地区A的同事用的是内网地址,地区B的同事用的是映射后的地址,就导致反复修改配置文件、互相覆盖配置文件。发生产还要修改配置文件,破坏了测试结果的准确性。
在此背景下,强烈推荐使用服务发现,统一配置中心、环境变量,减少和降低测试通过后的版本还需要修改代码和配置文件的频率。
将端口转发为与生产一致的端口号
经常修改的配置文件主要集中在数据库、redis等方面,因为要区分端口,很多同事就把IP端口写死在配置文件,当要部署到生产,一个新的项目要部署时候,就需要回来改代码,这很显然是不够科学的。为了应对这一问题,应该将三个环境都用服务发现,在开发的时候,借助一些小工具和小技巧,将开发、测试、生产环境使用的服务名、端口统一起来。
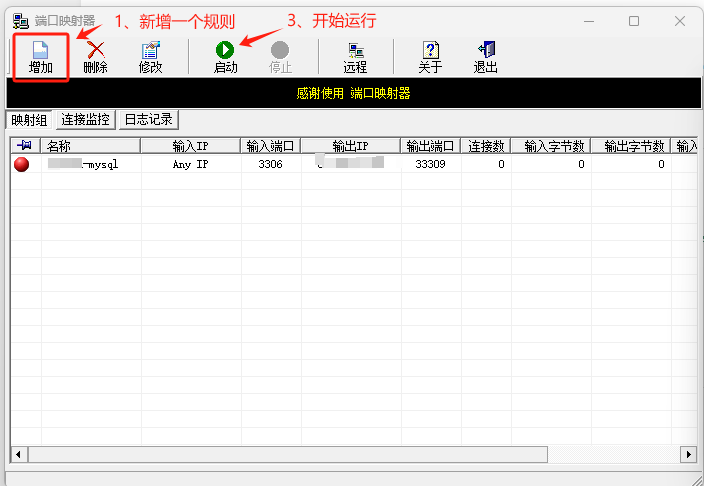
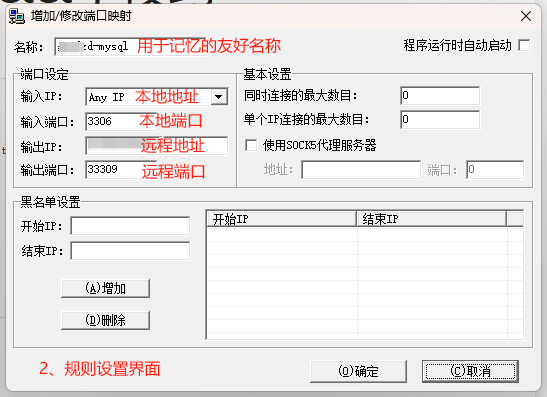
- 使用有界面的端口转发PORTMAP小工具
小工具下载 https://iovhm.com/uploads/software/tools/portmap-1.6.zip
- 使用命令行(仅windows)
# 仅windows可用
# 增加一个端口转发
# netsh interface portproxy add v4tov4 listenport=<监听端口> listenaddress=<监听地址> connectport=<目标端口> connectaddress=<目标地址>
netsh interface portproxy add v4tov4 listenport=3306 listenaddress=0.0.0.0 connectport=33309 connectaddress=8.x.y.z
# 删除一个端口转发
# netsh interface portproxy delete v4tov4 listenport=<监听端口> listenaddress=<监听地址>
netsh interface portproxy delete v4tov4 listenport=3306 listenaddress=0.0.0.0
# 查看所有的端口转发规则
netsh interface portproxy show all
如上设置和命令,将原本需要修改配置文件的jdbc:mysql://mysql:33306/xxxxx,统一为使用环境变量的 jdbc:mysql://${mysql}:3306/xxxxx,保证了配置文件的一致性。
在IDEA中使用统一的环境变量设置
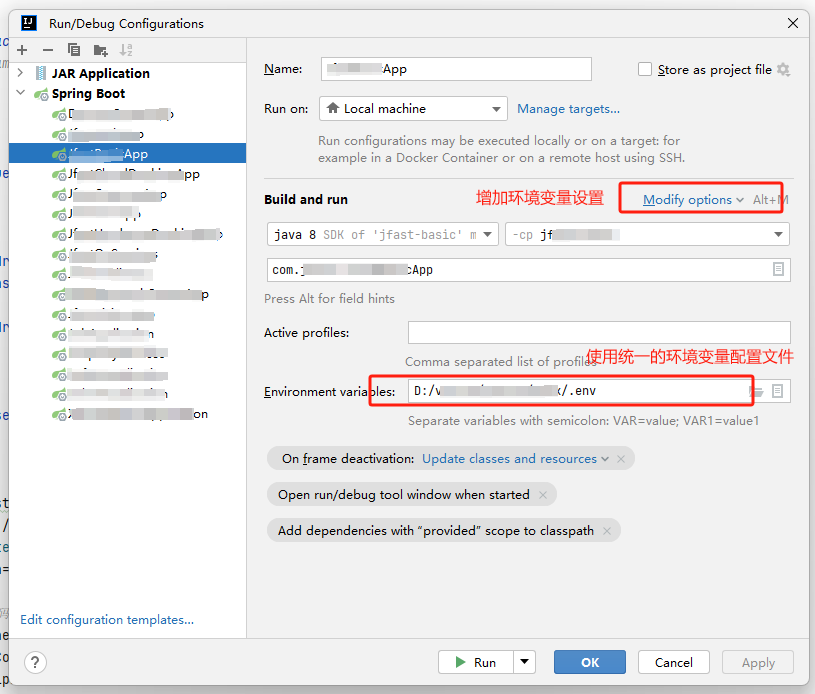
env文件可以迁入到代码仓库大家共享,idea设置本身并不会迁入到代码仓库,不会发生冲突
# .env文件
nacos_host=
nacos_port=
mysql=127.0.0.1
redis=127.0.0.1
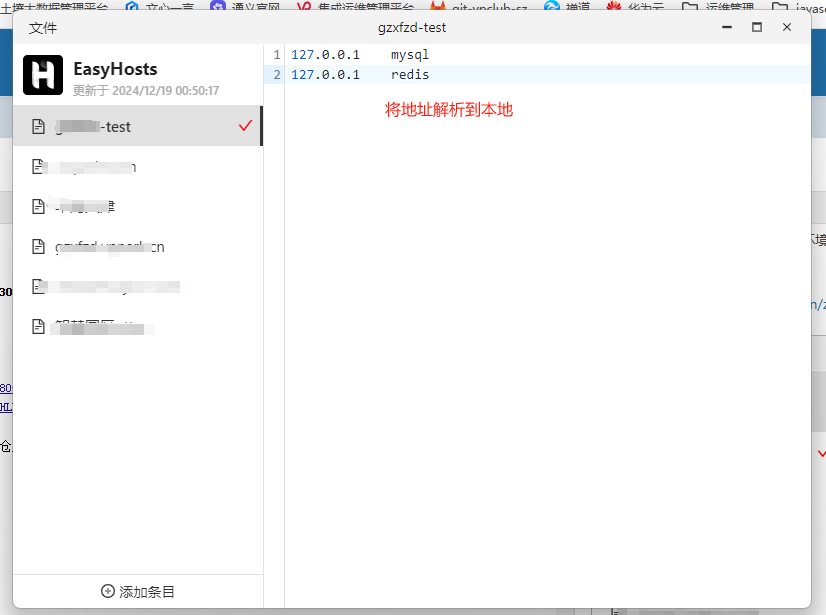
hosts修改小工具
如果非常不凑巧,配置文件并没有使用环境变量占位符,可以修改hosts表来进行设置,但频繁的修改hosts文件,也挺麻烦,这里有个小工具,可以方便的管理hosts文件。当然了,如果你不嫌麻烦,也可以手工修改host文件
下载地址:https://www.easyhosts.cn/zh/

人人框架代码生成器安装部署
代码生成器能生成基础的单表、实体、列表、CURD,减少毫无意义的工作,还能保证基础代码的一致性,强制需要使用。
代码生成器生成的代码路径存放运本机磁盘,需要在本机同时运行基础项目、代码生成器项目、前端项目;后端开发人员不会运行前端项目,前端开发人员不会运行java项目。会造成一定的麻烦。
比较好的做法是将代码生成器部署到服务器给大家共享,再用web版本的vscode浏览、将代码复制回来粘贴到项目中。
安装部署代码生成器
源代码位置:/renren-module/renren-devtools
- 编写dockerfile
# vi Dockerfile
FROM openjdk:17
EXPOSE 8080
# VOLUME /tmp
ADD target/renren-devtools.jar /app.jar
CMD ["java","-jar","/app.jar"]
- 编写push.sh
#!/bin/bash
# 登录
docker login -u <your name> -p <your password> swr.cn-south-1.myhuaweicloud.com
# 打包
docker build -t swr.cn-south-1.myhuaweicloud.com/vp-park/park-weihai/renren-devtools-server:v1.0 ./
# 推送
docker push swr.cn-south-1.myhuaweicloud.com/vp-park/park-weihai/renren-devtools-server:v1.0
- 导入代码生成器初始化数据库脚本
源代码位置:/renren-module/renren-devtools/db/mysql.sql
设置代码生成器生
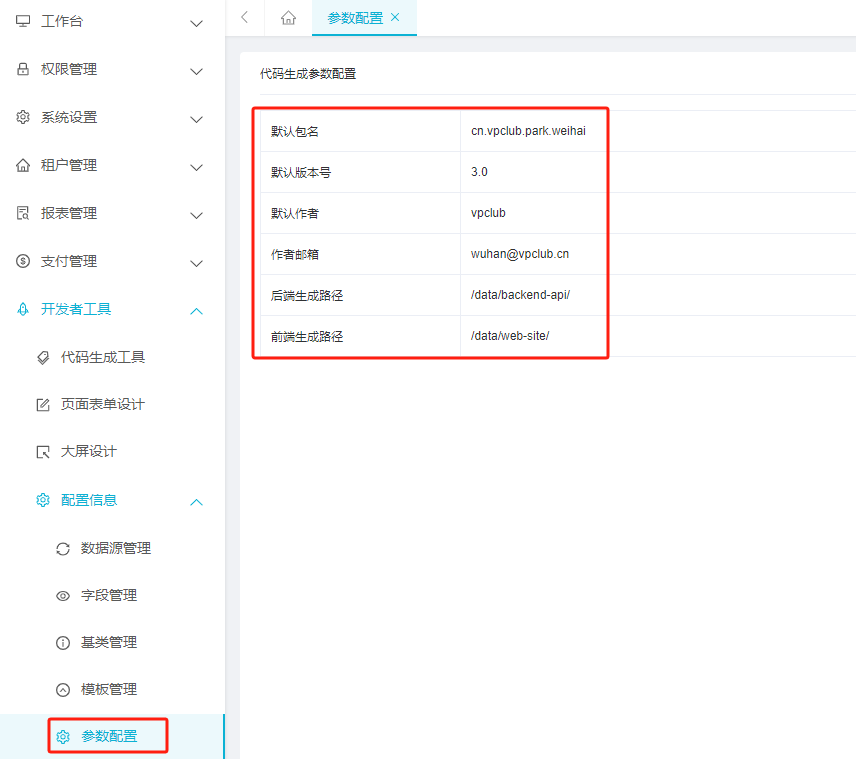
注意代码生成路径 ,如果是容器运行,请将 /data 目录挂载到磁盘或者NFS
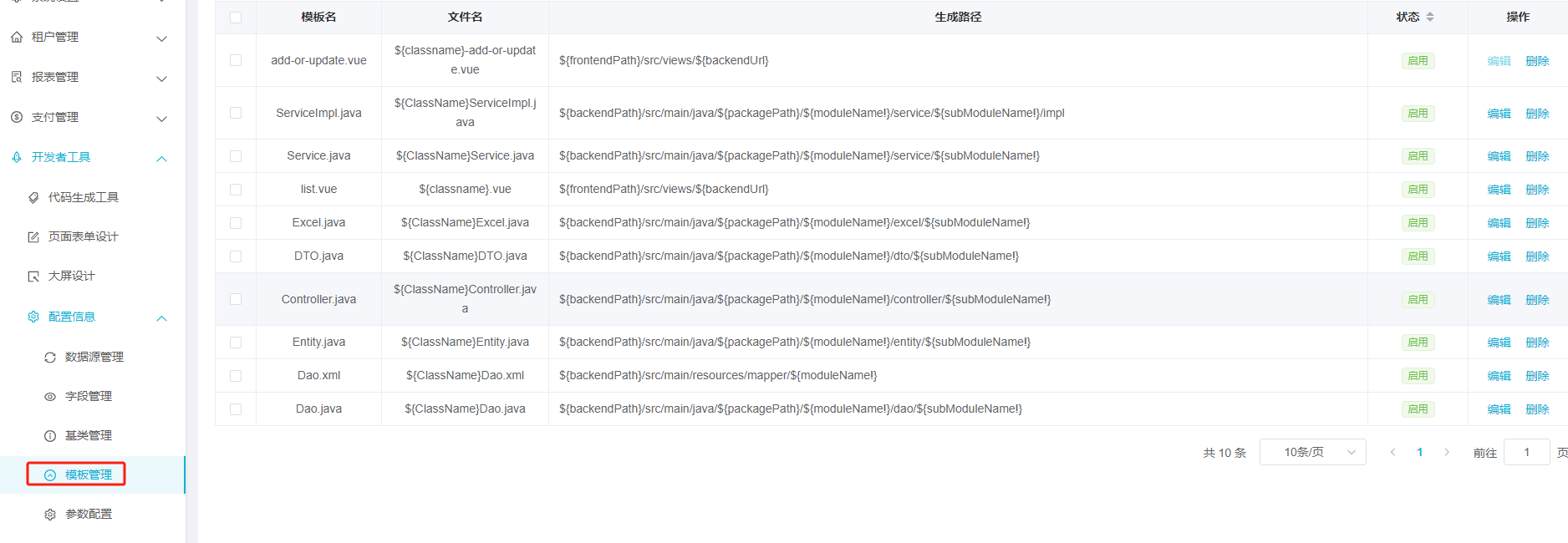
- 导入模板
模板位置:/renren-module/renren-devtools/db/template 将模板粘贴到对应项
- 生成代码
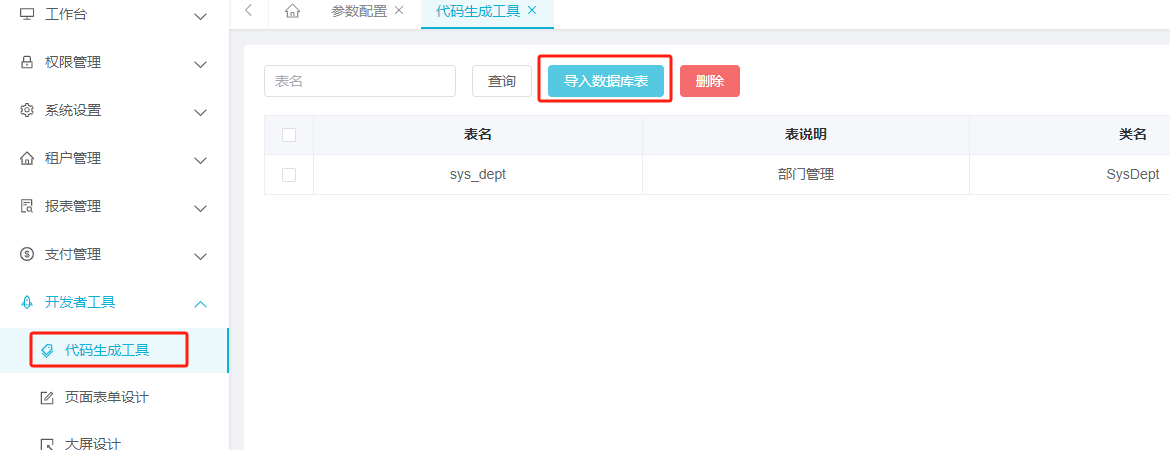
- 设置代码包相关信息
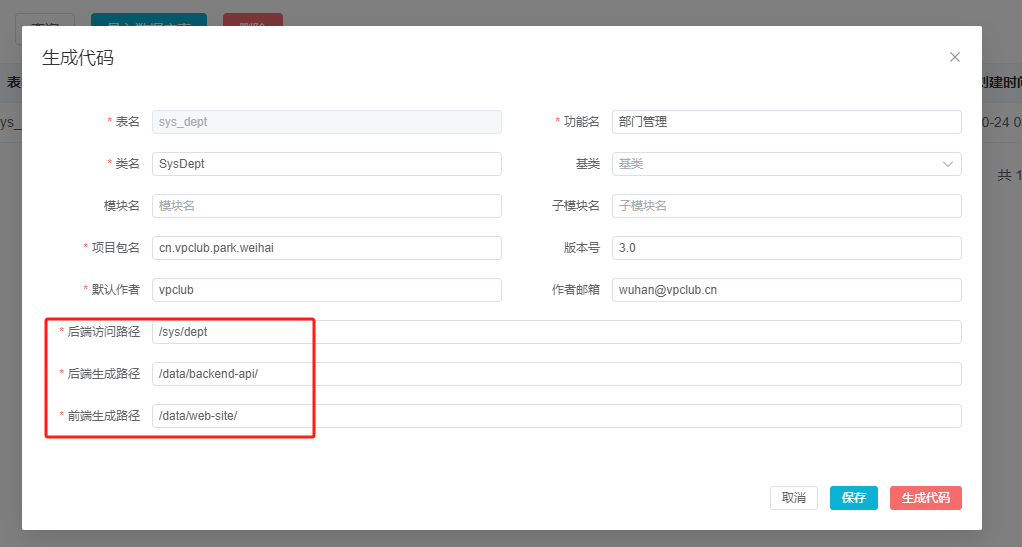
注意代码生成路径 ,如果是容器运行,请将 /data 目录挂载到磁盘或者NFS
运行code-server
code-server具有极高的权限,开发完成后应该删除相关部署、设置复杂密码
version: "2.1"
services:
code-server:
image: swr.cn-south-1.myhuaweicloud.com/vp-whdev/all-in-devops/vscode-server:latest
container_name: code-server
environment:
- PUID=1000
- PGID=1000
- TZ=Etc/UTC
- PASSWORD=password # web gui password
- DEFAULT_WORKSPACE=/data # 打开 web gui 时默认打开文件夹
volumes:
- /path/to/appdata/config:/data # 将前面设置的代码生成器映射到 code-server
ports:
- 8443:8443
restart: unless-stopped
# 设置兖州后需要登录,登录页位于网站根目录,需要为 code-server 单独设置一个域名
浏览code-server将代码复制到项目
软件增加license管理
需要增加2个文件,建议目录放置在config目录
FilterConfig.java
全局过滤器配置 ,对需要拦截的路径进行配置
package cn.vppark.whdev.license_test.config;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* Filter配置
*
* @author Mark sunlightcs@gmail.com
*/
@Configuration
public class FilterConfig {
@Value("${app.license:}")
private String license;
@Bean
public FilterRegistrationBean licenseFilterRegistration() {
FilterRegistrationBean registration = new FilterRegistrationBean();
registration.setFilter(new LicenseFilter(license));
registration.addUrlPatterns("/*");
registration.setName("licenseFilter");
registration.setOrder(Integer.MAX_VALUE);
return registration;
}
}
LicenseFilter.java
package cn.vppark.whdev.license_test.config;
import com.alibaba.fastjson.JSONObject;
import org.apache.commons.io.IOUtils;
import org.springframework.beans.factory.annotation.Value;
import javax.crypto.BadPaddingException;
import javax.crypto.Cipher;
import javax.crypto.IllegalBlockSizeException;
import javax.crypto.NoSuchPaddingException;
import javax.servlet.*;
import javax.servlet.http.HttpServletResponse;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.net.URL;
import java.nio.charset.StandardCharsets;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.security.InvalidKeyException;
import java.security.KeyFactory;
import java.security.NoSuchAlgorithmException;
import java.security.spec.InvalidKeySpecException;
import java.security.spec.X509EncodedKeySpec;
import java.util.Base64;
import java.util.Date;
/**
* @Description: 证书校验
* @date: 2024年4月9日 下午12:39:48
* @Copyright:
*/
public class LicenseFilter implements Filter {
private String license;
/**
* 公钥
*/
private final String publicKey = "your public key";
public LicenseFilter(String license) {
this.license = license;
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
//设置返回参数
HttpServletResponse httpServletResponse = (HttpServletResponse) response;
httpServletResponse.setStatus(HttpServletResponse.SC_BAD_REQUEST);
httpServletResponse.setCharacterEncoding("UTF-8");
httpServletResponse.setContentType("text/html; charset=UTF-8");
try {
if (this.license == null || license.isEmpty()) {
// 优先使用配置文件的证书,因为调试运行的时候,会清空target目录,导致证书文件丢失
this.license = IOUtils.toString(new FileInputStream(getLicensePath()), StandardCharsets.UTF_8);
}
//解密证书
String licenseContent = verifyLicense(this.license);
JSONObject json = JSONObject.parseObject(licenseContent);
//获取过期时间
Date expire = json.getDate("expire");
httpServletResponse.setHeader("license-expire", expire.toString());
//判断证书是否过期
if (expire.getTime() < System.currentTimeMillis()) {
httpServletResponse.getWriter().write("软件授权过期!");
return;
}
httpServletResponse.setStatus(HttpServletResponse.SC_OK);
} catch (FileNotFoundException e) {
httpServletResponse.getWriter().write("证书文件丢失,请联系管理员!");
e.printStackTrace();
return;
} catch (Exception e) {
httpServletResponse.getWriter().write("证书文件已损坏,请联系管理员!");
e.printStackTrace();
return;
}
chain.doFilter(request, response);
}
/**
* @throws
* @Description: 根据公钥解密字符串
* @param: licenseContent 证书内容
*/
public String verifyLicense(String licenseContent) throws NoSuchAlgorithmException, InvalidKeySpecException, InvalidKeyException, NoSuchPaddingException, IllegalBlockSizeException, BadPaddingException {
Cipher cipher = Cipher.getInstance("RSA");
cipher.init(Cipher.DECRYPT_MODE, KeyFactory.getInstance("RSA").generatePublic(new X509EncodedKeySpec(Base64.getDecoder().decode(publicKey))));
byte[] decryptedBytes = cipher.doFinal(Base64.getDecoder().decode(licenseContent));
String decryptedString = new String(decryptedBytes);
// 打印解密后的证书内容
System.out.println("licenseContent: " + decryptedString);
return decryptedString;
}
/**
* @throws
* @Description: 获取license完整路径
*/
private String getLicensePath() throws URISyntaxException {
URL classUrl = this.getClass().getProtectionDomain().getCodeSource().getLocation();
URI uri = classUrl.toURI();
Path path;
if (uri.getScheme().equals("jar")) {
// 如果是一个JAR URL,我们需要找到JAR文件本身
String jarPath = uri.getSchemeSpecificPart();
jarPath = jarPath.substring(0, jarPath.indexOf('!'));
path = Paths.get(new URI(jarPath)).getParent();
} else {
// 如果不是JAR URL,则可能是直接从文件系统加载的类
path = Paths.get(uri);
}
String licensePath = path.resolve("license/license").toString();
// 打印证书路径
System.out.println("licensePath: " + licensePath);
return licensePath;
}
}
各应用平台注册地址
信息系统安全定级说明
一、确定安全保护等级
依据《信息安全等级保护管理办法》(公通字 [2007] 43 号)《关于开展全国重要信息系统安全等级保护定级工作的通知》 (公信安[2007]861 号)、《信息安全技术网络安全等级保护定级指南》(GB/T22240-2020) 等文件规定和国家政务外网的统一要求,所建设的需要信息系统的安全保护等级。
二、安全等级保护等级确定流程
确定信息系统安全保护等级的一般流程如下:
- 第一、确定作为定级对象的信息系统;
- 第二、确定业务信息安全受到破坏时所侵害的客体;
- 第三、根据不同的受侵害客体,从多个方面综合评定业务信息安全被破坏对客体的侵害程度;
- 第四、得到业务信息安全保护等级;
- 第五、确定系统服务安全受到破坏时所侵害的客体;
- 第六、根据不同的受侵害客体,从多个方面综合评定系统服务安全被破坏对客体的侵害程度;
- 第七、得到系统服务安全保护等级;
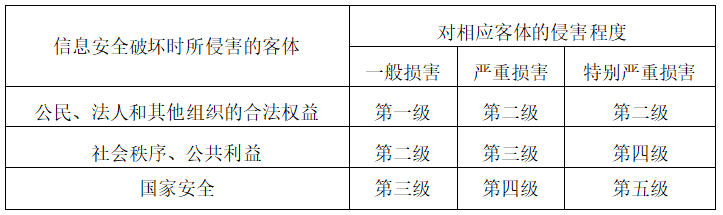
- 第八、将业务信息安全保护等级和系统服务安全保护等级的较高者确定为定级对象的安全保护等级。
信息安全保护等级矩阵表如下所示:
三、定级对象受侵害客体
定级对象受到破坏时所侵害的客体包括国家安全、社会秩序、公众利益以及公民、法人和其他组织的合法权益。
-
1、受侵害的客体及对客体的侵害程度
- (1) 侵害国家安全主要是指影响国家政权稳固和国防实力、民族团结和社会安定、重要的安全保卫工作、经济竞争力和科技实力等。
- (2) 侵害社会秩序主要是指影响国家机关社会管理和公共服务的工作秩序、各种类型的经济活动秩序等。
- (3) 影响公共利益主要是指影响公共设施、公开信息资源、公共服务等方面。
- (4) 影响公民、法人和其他组织的合法权益是指由法律确认的并受法律保护的公民、法人和其他组织所享有的一定的社会权利和利。
-
2、不同危害后果的三种危害程度
- (1)一般损害:工作职能受到局部影响,业务能力有所降低但不影响主要功能的执行,出现较轻的法律问题,较低的财产损失,有限的社会不良影响,对其他组织和个人造成较低损害。
- (2) 严重损害:工作职能受到严重影响,业务能力显著下降目严重影响主要功能执行,出现较严重的法律问题,较高的财产损失,较大范围的社会不良影响,对其他组织和个人造成较严重损害。
- (3) 特别严重损害: 工作职能受到特别严重影响或丧失行使能力,业务能力严重下降且或功能无法执行,出现极其严重的法律问题.极高的财产损失,大范围的社会不良影响,对其他组织和个人造成非常严重损害。
create-springboot-project
创建项目目录结构
springboot 官方脚手架:https://start.spring.io/
# 创建项目结构
mkdir -p src/main/java
mkdir -p src/main/resources
mkdir -p src/test/java
mkdir -p src/test/resources
# 创建第一个包
mkdir -p src/main/java/com/iovhm/hello
# 创建4个环境的配置文件
touch src/main/resources/application.yml
touch src/main/resources/application-dev.yml
touch src/main/resources/application-tet.yml
touch src/main/resources/application-prod.yml
pom.xml
touch ./pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!--如果项目没有层级关系,请删除下面的节点-->
<!--<parent>-->
<!--<groupId>cn.vpclub</groupId>-->
<!--<artifactId>spring-boot-starters</artifactId>-->
<!--<version>1.4.15</version>-->
<!--</parent>-->
<!--如果项目没有层级关系,请删除上面的节点-->
<!---项目组,必须-->
<groupId>com.iovhm</groupId>
<!--项目唯一ID,必须-->
<artifactId>hello-springboot</artifactId>
<!--项目版本,必须-->
<version>1.0.0</version>
<!--生成类型,必须,可选参数pom,jar,一般情况下使用jar-->
<packaging>jar</packaging>
<!---属性设置,项目属性不是必须的,但是建议写上便于精确控制-->
<properties>
<java.version>17</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.test.skip>true</maven.test.skip>
<spring-boot.version>3.4.1</spring-boot.version>
</properties>
<!-- 统一spring boot 版本 -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!--spring boot 依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>${spring-boot.version}</version>
</dependency>
<!--mybatis支持-->
<!--如果使用 mybatis plus 请将 mybatis 支持 去掉, mybatis plus 会自动处理依赖-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>3.0.4</version>
</dependency>
<!-- mybatils plus 支持-->
<!--如果使用 mybatis plus 请将 mybatis 支持 去掉, mybatis plus 会自动处理依赖-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3.2</version>
</dependency>
<!--lombok支持-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.36</version>
</dependency>
<!--redis支持-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>${spring-boot.version}</version>
</dependency>
<!-- hu-tool工具 -->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.24</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring-boot.version}</version>
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
创建Application.java
touch src/main/java/com/iovhm/Application.java
package com.iovhm;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class);
}
}
创建HelloController.java
touch src/main/java/com/iovhm/hello/HelloController.java
package com.iovhm.hello;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
// 全局访问路径
@RequestMapping("/")
// 标记为本类为Controller类
@RestController
public class HomeController {
// 在全局访问路径的基础上,成员方法的访问路径
@RequestMapping("/")
public String hello() {
return "hello,world";
}
}
如果没有配置数据库,可能导致程序无法运行,可以先禁用数据库自动装配
# application.yml
spring:
autoconfigure:
# 阻止Spring Boot自动配置数据源
exclude: org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration
下一章
springboot 集成mybatis-plus https://iovhm.com/book/books/bbcbf/page/springboot-mybatis-plus
springboot 集成 mybatis
创建项目
create-springboot-project: https://iovhm.com/book/books/bbcbf/page/create-springboot-project
更多的时候我们使用mybatis-plus,本章可以直接跳过
springboot 集成mybatis-plus https://iovhm.com/book/books/bbcbf/page/springboot-mybatis-plus
集成数据库
注意:如果你是按create-springboot-project创建的项目,需要删除配置
# application.yml
spring:
autoconfigure:
# 阻止Spring Boot自动配置数据源
exclude: org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration
约定与名词解释
- entity(实体),与数据表,代表一张真实的数据表
- DAO(数据访问对象),访问数据库的接口或实例,在spring-boot中,有时候有喜欢取名为Mapper
- DTO(数据传输对象),含业务领域的数据(既DTO包含entity的字段,但是应该多于entity),不包含业务逻辑,负责在系统与系统之间、分层与分层之间传递数据。
确定项目结构
好的结构易于项目维护
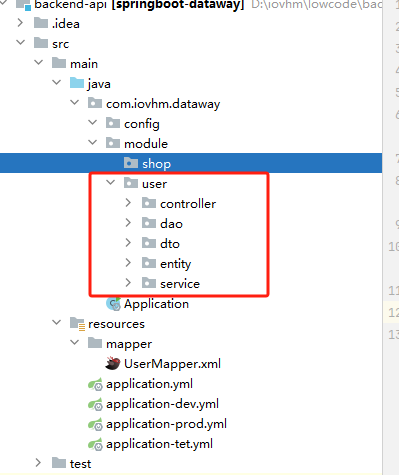
增加pom依赖
<!--mysql支持-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.30</version>
</dependency>
<!--mybatis支持-->
<!--如果使用 mybatis plus 请将 mybatis 支持 去掉, mybatis plus 会自动处理依赖-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>3.0.3</version>
</dependency>
增加数据库连接配置
spring:
datasource:
url: jdbc:mysql://127.0.0.1:33306/dataway?charset=utf8mb4&serverTimezone=Asia/Shanghai
username: <root>
password: <password>
driver-class-name: com.mysql.cj.jdbc.Driver
创建数据库
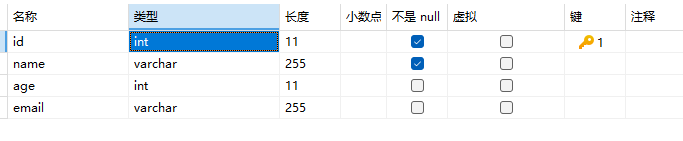
创建Entity(实体)与数据库结构保持一致
在实体上增加注解 @Data
@Data
public class UserEntity {
private Integer id;
private String name;
private Integer age;
private String email;
}
创建DTO
由于DTO主要负责业务数据传输,DTO可以先直接继承于Entity,再根据业务需要增加字段,注意 @Data 注解
@Data
public class UserDTO extends UserEntity {
}
创建Dao或者Mapper
注意 @Mapper 注解,Mapper是用来操作数据库的,使用的数据结构应该是Entity,虽然用DTO也可以使用,但还是应该遵守编程规范
@Mapper
public interface UserMapper {
@Select("SELECT * FROM user")
List<UserEntity> selectList();
}
编写Controller
// 全局访问路径
@RequestMapping("/")
// 标记为本类为Controller类
@RestController
@Slf4j
public class HomeController {
private final UserMapper userMapper;
public HomeController(UserMapper userMapper) {
this.userMapper = userMapper;
}
@RequestMapping("/")
public Object hello() {
List list =userMapper.selectList();
return list;
}
}
修改Application
注意 @MapperScan("com.iovhm.dataway.**.dao")
@SpringBootApplication
@MapperScan("com.iovhm.dataway.**.dao")
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class);
}
}
springboot 集成mybatis-plus
创建项目
create-springboot-project: https://iovhm.com/book/books/bbcbf/page/create-springboot-project
集成数据库
注意:如果你是按create-springboot-project创建的项目,需要删除配置
# application.yml
spring:
autoconfigure:
# 阻止Spring Boot自动配置数据源
exclude: org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration
约定与名词解释
- entity(实体),与数据表,代表一张真实的数据表
- DAO(数据访问对象),访问数据库的接口或实例,在spring-boot中,有时候有喜欢取名为Mapper
- DTO(数据传输对象),含业务领域的数据(既DTO包含entity的字段,但是应该多于entity),不包含业务逻辑,负责在系统与系统之间、分层与分层之间传递数据。
确定项目结构
增加pom依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-bom</artifactId>
<version>3.5.10</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<!--mysql支持-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.30</version>
</dependency>
<!--mybatis支持-->
<!--如果使用 mybatis plus 请将 mybatis 支持 去掉, mybatis plus 会自动处理依赖-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>3.0.3</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-spring-boot3-starter</artifactId>
<version>3.5.10</version>
</dependency>
增加数据库连接配置
spring:
datasource:
url: jdbc:mysql://127.0.0.1:33306/dataway?charset=utf8mb4&serverTimezone=Asia/Shanghai
username: <root>
password: <password>
driver-class-name: com.mysql.cj.jdbc.Driver
创建数据库
创建Entity(实体)与数据库结构保持一致
注意 @Data 和 @TableName("user") 注解
@Data
@TableName("user")
public class UserEntity {
private Integer id;
private String name;
private Integer age;
private String email;
}
创建DTO
由于DTO主要负责业务数据传输,DTO可以先直接继承于Entity,再根据业务需要增加字段,注意 @Data 注解
@Data
public class UserDTO extends UserEntity {
}
创建DAO
注意继承于Mybatis-plus的BaseMapper,以及Mapper里面的Entity。DAO是用来操作数据库的类,使用的数据结构应该是Entity,虽然继承于EEntity的DTO也可以使用,但还是应该遵守编程规范
@Mapper
public interface UserDao extends BaseMapper<UserEntity> {
}
创建Service
public interface UserService {
List<UserDTO> selectList();
List<UserDTO> selectList2();
}
@Service
public class UserServiceImpl implements UserService {
private final UserMapper userMapper;
private final UserDao userDao;
public UserServiceImpl(UserMapper userMapper, UserDao userDao) {
this.userMapper = userMapper;
this.userDao = userDao;
}
@Override
public List<UserDTO> selectList() {
List list = userDao.selectList(null);
return list;
}
@Override
public List<UserDTO> selectList2() {
return userMapper.selectList();
}
}
创建Controller
// 全局访问路径
@RequestMapping("/")
// 标记为本类为Controller类
@RestController
@Slf4j
public class HomeController {
private UserService userService;
public HomeController(UserService userService) {
this.userService = userService;
}
@RequestMapping("/")
public Object hello() {
List list = userService.selectList();
List list2 = userService.selectList2();
return Map.of("list", list, "list2", list2);
}
}
修改Application
注意 @MapperScan("com.iovhm.dataway.**.dao")
@SpringBootApplication
@MapperScan("com.iovhm.dataway.**.dao")
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class);
}
}
springboot 集成mybatis-plus通用CRUD
CRUD
mybatis-plust提供了通用CRUD类 IService ,可以直接继承改接口并实现ServiceImpl既可以实现通用CURD
实现自定义的CURD基础类
根据研发规范,IService返回的数据结构是Entity类型,与规范要求的业务代码应该返回DTO不符,可以实现自定义基类来解决
创建并实现自定义基类
/*
* @Description:自定义CRUD基类
* @Author: donglietao@163.com
* @ENT: 实体类
* @DTO: DTO类
*/
public interface CrudService<ENT, DTO> {
List<DTO> list(@Param("ew") Wrapper<ENT> queryWrapper);
}
主要是用到了BaseMap<ENT>类型
/*
* @description: CrudServiceImpl
* @author: donglietao@163.com
* */
@Service
@Slf4j
public class CrudServiceImpl<ENT, DTO> implements CrudService<ENT, DTO> {
// 主要是这个地方,可以使用泛型创建mapper
@Autowired
protected BaseMapper<ENT> baseMapper;
private Class<DTO> getDTOClass() {
return (Class<DTO>) ReflectionKit.getSuperClassGenericType(this.getClass(), CrudService.class, 1);
}
public List<DTO> list(@Param("ew") Wrapper<ENT> queryWrapper) {
List<ENT> list = baseMapper.selectList(queryWrapper);
if (list == null) {
return null;
}
// 此处可以简化,将方法抽离到工具类
List<DTO> listDTO = new ArrayList<>(list.size());
Class<DTO> dtoClass = getDTOClass();
for (ENT ent : list) {
try {
DTO dto = dtoClass.newInstance();
BeanUtils.copyProperties(ent, dto);
listDTO.add(dto);
} catch (Exception ex) {
log.error("CrudServiceImpl.list() error:", ex);
}
}
return listDTO;
}
}
在自定义服务类上实现通用CRUD基类
public interface UserService extends CrudService<UserEntity, UserDTO> {
}
@Service
public class UserServiceImpl extends CrudServiceImpl<UserEntity, UserDTO> implements UserService {
}
进一步简化代码
类型转换工具类
将转换类独立为工具类
@Slf4j
public class ConvertUtils {
public static <T> T sourceToTarget(Object source, Class<T> target) {
if (source == null) {
return null;
}
T targetObject = null;
try {
targetObject = target.newInstance();
BeanUtils.copyProperties(source, targetObject);
} catch (Exception e) {
log.error("convert error ", e);
}
return targetObject;
}
public static <T> List<T> sourceToTarget(Collection<?> sourceList, Class<T> target) {
if (sourceList == null) {
return null;
}
List targetList = new ArrayList<>(sourceList.size());
try {
for (Object source : sourceList) {
T targetObject = target.newInstance();
BeanUtils.copyProperties(source, targetObject);
targetList.add(targetObject);
}
} catch (Exception e) {
log.error("convert error ", e);
}
return targetList;
}
}
使用类型转换工具简化调用
@Service
@Slf4j
public class CrudServiceImpl<ENT, DTO> implements CrudService<ENT, DTO> {
@Autowired
protected BaseMapper<ENT> baseMapper;
private Class<DTO> getDTOClass() {
return (Class<DTO>) ReflectionKit.getSuperClassGenericType(this.getClass(), CrudService.class, 1);
}
public List<DTO> list(@Param("ew") Wrapper<ENT> queryWrapper) {
List<ENT> list = baseMapper.selectList(queryWrapper);
// 使用转换工具简化调用
List<DTO> listDTO = ConvertUtils.sourceToTarget(list, getDTOClass());
return listDTO;
}
}
create-vite-vue-project
官方帮助:https://cn.vitejs.dev/guide/
npm create vite@latest
# 其他选项
# o Project name:
# | enterprise-service-mall-app
# |
# o Select a framework:
# | Vue
# |
# o Select a variant:
# | TypeScript
# |
# o Use rolldown-vite (Experimental)?:
# | Yes
# |
# o Install with npm and start now?
# | Yes
# 安装yarn
npm install yarn --save-dev --registry https://registry.npmmirror.com
# 安装依赖
yarn install --registry https://registry.npmmirror.com
# 安装 vant、vuerouter、pinia、swiper、crypto-js
yarn add vant vue-router pinia swiper crypto-js --registry https://registry.npmmirror.com
# 启动运行
yarn run dev

npm和yarn
区别
-
npm(Node Package Manager)
是Node.js的默认包管理工具。它主要用于JavaScript和Node.js项目的包管理。npm的出现是为了方便开发者安装、更新、管理项目依赖的包(库)。它有一个庞大的包仓库,即npm仓库,里面包含了海量的开源包。 npm仓库是全球最大的软件包仓库之一,它为开发者提供了丰富的资源。比如,如果你想在项目中使用一个轻量级的HTTP客户端库,就可以通过npm安装axios库。npm仓库中的包通常是由开发者按照一定的规范上传的,这些包可以是库、工具、插件等各种类型的软件组件。
-
Yarn
是一个由Facebook开发的现代包管理工具,它也是用于JavaScript和Node.js项目的包管理。Yarn的出现主要是为了解决npm在某些场景下存在的性能问题和稳定性问题。 Yarn和npm在功能上有很大的相似性,比如都可以安装、更新、管理包。不过,Yarn在一些方面进行了优化。例如,Yarn在安装包时会并行下载多个包,这使得安装速度比npm更快。而且Yarn在处理包的依赖关系时,采用了更先进的算法,能够更高效地解决依赖冲突等问题。
安装方式
-
npm
npm是Node.js自带的包管理工具。当你安装Node.js时,npm会自动安装在你的系统中。你可以通过在终端或命令提示符中输入npm -v来查看npm的版本,确认它是否已经正确安装。
-
Yarn
Yarn的安装方式相对独立。你可以通过npm来安装Yarn,命令是npm install -g yarn。此外,Yarn也提供了其他安装方式,比如在macOS上可以通过Homebrew安装(brew install yarn),在Windows上可以通过Chocolatey安装(choco install yarn)等。安装完成后,你可以通过yarn -v来查看Yarn的版本。
使用方式
-
npm
# 根据package初始化项目
npm install --registry https://registry.npmmirror.com
# 安装包
npm install three --save --registry https://registry.npmmirror.com
# 运行脚本
npm run dev
-
yarn
# 先安装yarn
npm install yarn --save-dev --registry https://registry.npmmirror.com
# 根据package初始化项目
yarn install --registry https://registry.npmmirror.com
# 安装包
yarn add three --save --registry https://registry.npmmirror.com
# 运行脚本
yarn run dev
hbuilder项目转vue项目&&jenkins uniapp
使用vue cli工具、uni预设创建新的项目
官方参考:https://uniapp.dcloud.net.cn/quickstart-cli.html
VUE3项目
如果不知道当前项目用的是什么VUE版本,可以去manifest.json查看vueVersion字段
# VUE3 javascript 项目
npx degit dcloudio/uni-preset-vue#vite my-vue3-project
# VUE3 typescript项目
npx degit dcloudio/uni-preset-vue#vite-ts my-vue3-project
VUE2项目
# 需要全局安装 vue-cli
npm install --location=global @vue/cli@4 --registry=http://registry.npmmirror.com
# 使用预设创建项目
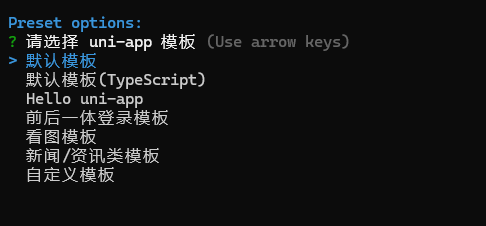
vue create -p dcloudio/uni-preset-vue my-project
根据项目类型选择预设模板(选择默认即可)
使用Vue3/Vite版不会提示,目前只支持创建默认模板
移植项目
# 先将项目运行起来
npm install --registry=http://registry.npmmirror.com
npm run dev
# 删除新项目中的src目录内文件
# 复制老项目文件到src目录
# .git package.json package-lock.json node_modules vue.config index.html 不需要复制
# .env 不需要要复制
#
#
#
#
# 如果你的package.json有内容,需要手动合并到项目外层的package.json
# 再次运行
npm run dev
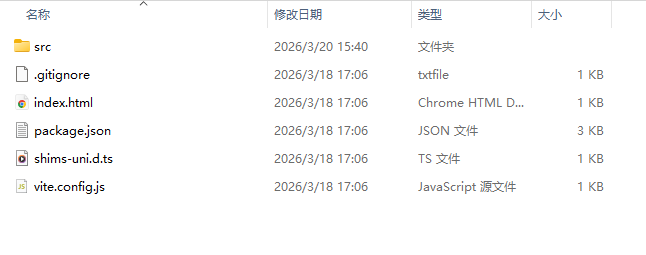
空项目的时候的文件夹内容
替换node-sass
如果运行时出现出现node-saas错误
"devDependencies": {
"less": "^4.3.0",
"sass": "^1.55.0",
}
打包APP提示:本应用使用 HBuilderX 4.66 或对应的cli版本编译,而手机端SDK版本是 3.96。不匹配的版本可能造成应用异常。

原因是HBuilder与cli的版本不一致
方法一:使用与cli版本一致的hbuilder
历史版本hbuilder下载地址:https://hx.dcloud.net.cn/Tutorial/HistoryVersion
方法二:在hbuilder里面仅加载项目的src目录进行打包(可以救急,但是不推荐)
方法三:将cli的版本升级与HBuilder保持一致
最简单的方法是使用npx @dcloudio/uvm@latest升级到最新版,然后下载最新的hbuilder
确定HBuilder的cli版本,打开hbuilder的关于界面,确定hbuild的版本
确定hbuilder的详细版本号
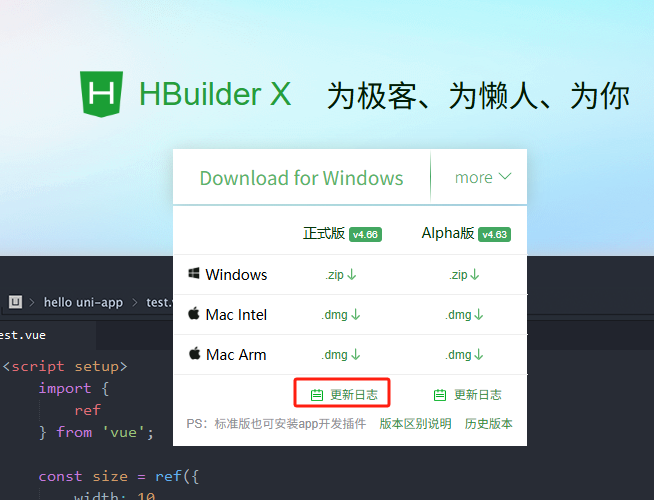
确定hbuilder的详细版本号
hbuilderx官网:https://www.dcloud.io/hbuilderx.html
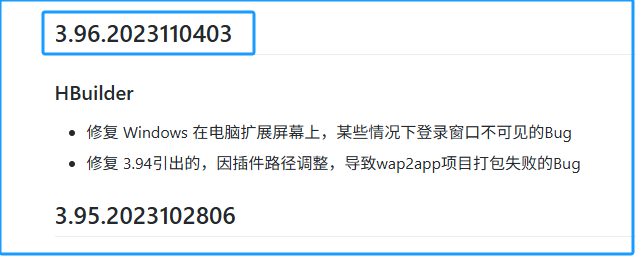
# 将cli的版本与hbuilder保持一致,此时可能报错,提示版本编号应该是x.y.z
# 需要到hbuilder官网找到真正的版本号
# 此时可能还会继续提示例如nodejs版本不匹配,请升级nodejs版本
# 依赖冲突等,例如vite和vue版本冲突,安装提示修改为匹配的版本既可
npx @dcloudio/uvm@latest 4.45.2025010502
npx @dcloudio/uvm@latest 3.96.2023110403
部分hbuilder和cli版本对照关系
| hbuilder版本 | cli版本 | 备注 |
|---|---|---|
| 4.45 | 4.45.2025010502 | --- |
| 3.96 | 3.96.2023110403 | --- |
CVE漏洞扫描插件
一、原理说明
有一帮用爱发电的人,对已知的组件的存在的安全漏洞做了一个共享数据库,这个插件可以对依赖的版本进行扫描,看你的组件有没有不合规的版本。
你如果高兴,可以配置mvn编译脚本先进行依赖检测,对于级别高于7的漏洞未修复不允许编译
二、使用CLI方式
CLI帮助:https://dependency-check.github.io/DependencyCheck/dependency-check-cli/index.html
CLI参数说明:https://dependency-check.github.io/DependencyCheck/dependency-check-cli/arguments.html
扫描之前需要先编译打包:mvn clean install
# 下载cli版本
https://github.com/dependency-check/DependencyCheck/releases/
# 更新漏洞库
dependency-check --updateonly --nvdDatafeed https://nvdcve.iovhm.com --retireJsUrl http://nvdcve.iovhm.com/jsrepository.json
# 扫描
dependency-check --noupdate --failOnCVSS 7 --scan "D:\vpclub\park-baiyun\baiyun-back\**\*.jar"
# 如果加入过环境变量,可以进入到项目文件夹执行
# --noupdate 不更新数据库
# --failOnCVSS 7 只扫描高位漏洞
# --format CSV ,默认输出为html,很卡,可以输出为csv
dependency-check --noupdate --failOnCVSS 7 --scan ./target/*.jar --format CSV
# 输出为csv格式时,主要查看 CVSSv3_BaseScore 列,筛选7和以上的优先修复。或者查看CVSSv3_BaseSeverity 列,优先修复高(HIGH)和严重(CRITICAL)
每次都需要进入到bin目录执行和要复制全路径太麻烦,可以将dependency-check加入到环境变量的path
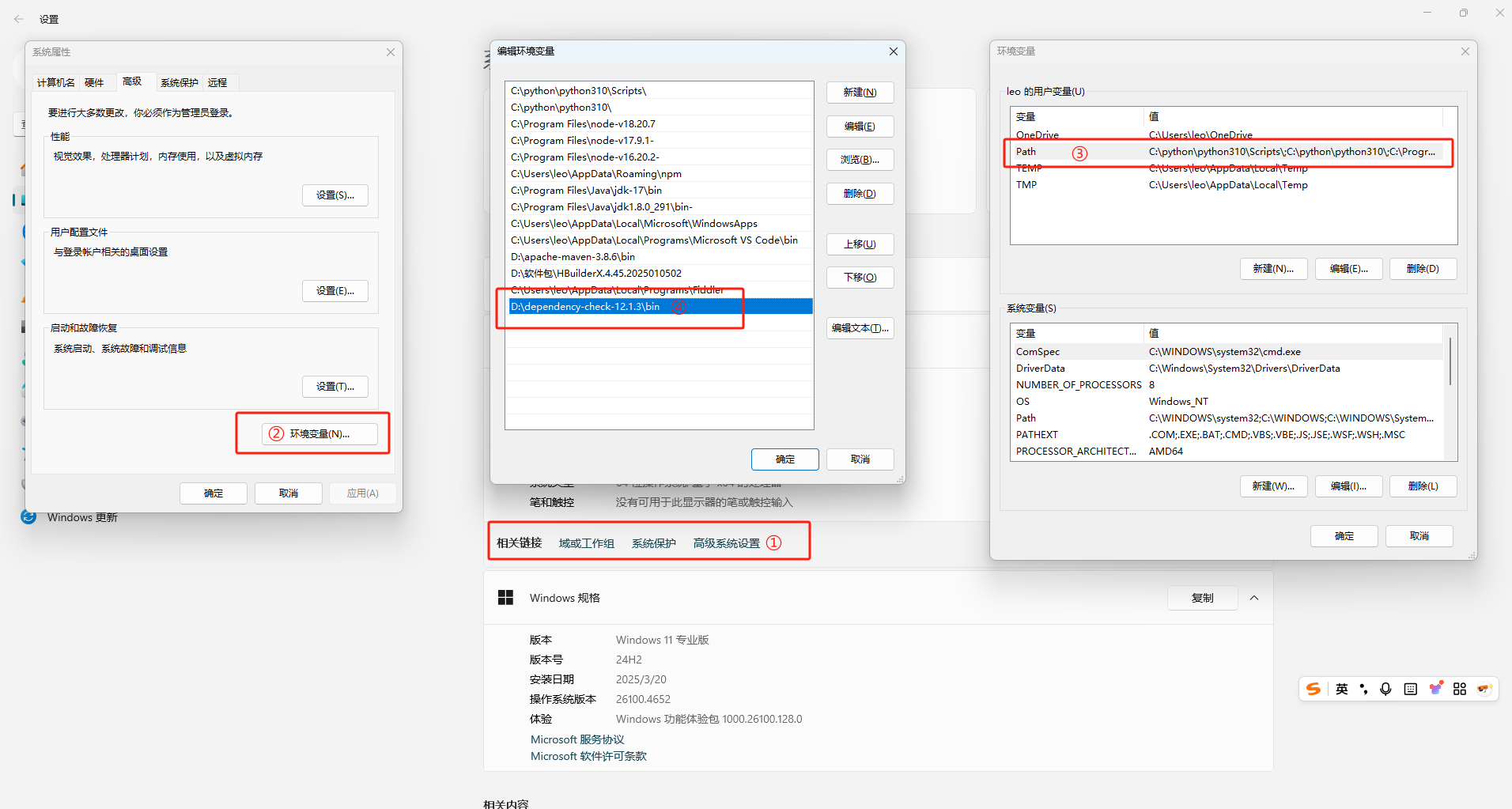
不支持JAVA 8
如果你的项目是java 8 或者当前默认环境设置为了java 8, 执行dependency-check提示版本不对 ,需要修改dependency-check.bat 里面使用的java版本
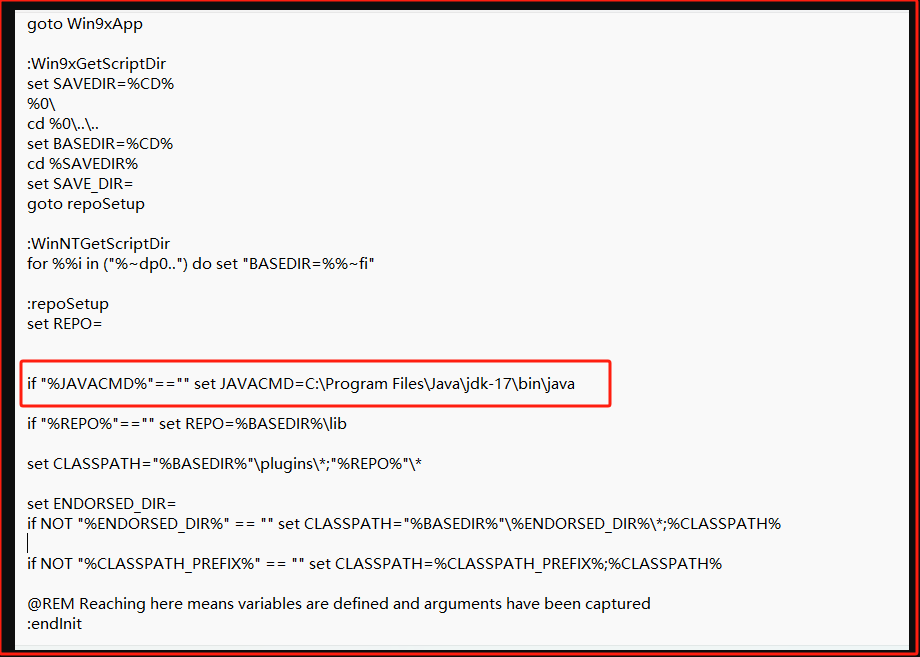
三、使用mvn插件方式
小技巧:设置了插件方式后不能编译了怎么办,可以把failBuildOnCVSS设置为11,可以编译,同时也生成报告
插件名称:dependency-check-maven
maven 中心仓库最新版本发布页:https://central.sonatype.com/artifact/org.owasp/dependency-check-maven
maven 插件方式帮助:https://dependency-check.github.io/DependencyCheck/dependency-check-maven/
maven 版本要求:3.8和以上
JDK 8 支持的最高版本为10.0.3,但是无法支持2023以后的漏洞数据库,直接报错。只能使用CLI方式
配置mvn项目
<build>
<plugins>
<plugin>
<groupId>org.owasp</groupId>
<artifactId>dependency-check-maven</artifactId>
<version>12.1.3</version>
<configuration>
<!-- 使用美国国家中心的数据库需要的秘钥,如果配置了镜像可以不需要-->
<nvdApiKey>your_key</nvdApiKey>
<!-- 手动更新漏洞数据库 -->
<autoUpdate>false</autoUpdate>
<!-- nvdcve 漏洞库镜像地址 -->
<nvdDatafeedUrl>https://nvdcve.iovhm.com</nvdDatafeedUrl>
<!-- retire.js 漏洞库镜像地址 -->
<retireJsUrl>http://nvdcve.iovhm.com/jsrepository.json</retireJsUrl>
<!-- 只扫描风险评分大于等于这个数值的,既高危漏洞 -->
<failBuildOnCVSS>7</failBuildOnCVSS>
</configuration>
<executions>
<execution>
<goals>
<goal>check</goal>
<goal>update-only</goal>
<goal>aggregate</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
执行依赖CVE检测
# 升级漏洞库
mvn dependency-check:update-only
# 对 整个多模块项目(含所有子模块) 执行聚合依赖扫描。递归扫描所有子模块的依赖,合并为一个统一报告。多模块项目,想一次性检查所有模块的依赖。
mvn dependency-check:aggregate
# 对 当前 Maven 模块 执行依赖漏洞扫描, 只扫描当前模块的依赖(不会递归子模块),单模块项目,或你只想检查某个模块
mvn dependency-check:check
也可以在可视化区域执行
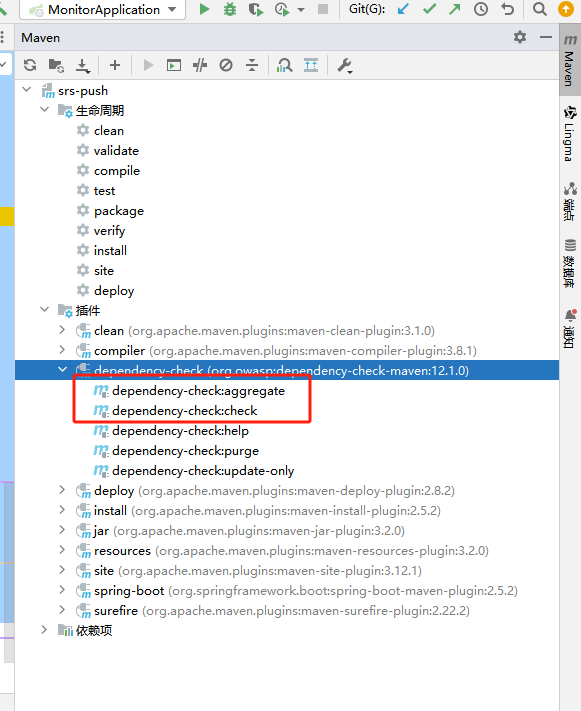
获取扫描报告
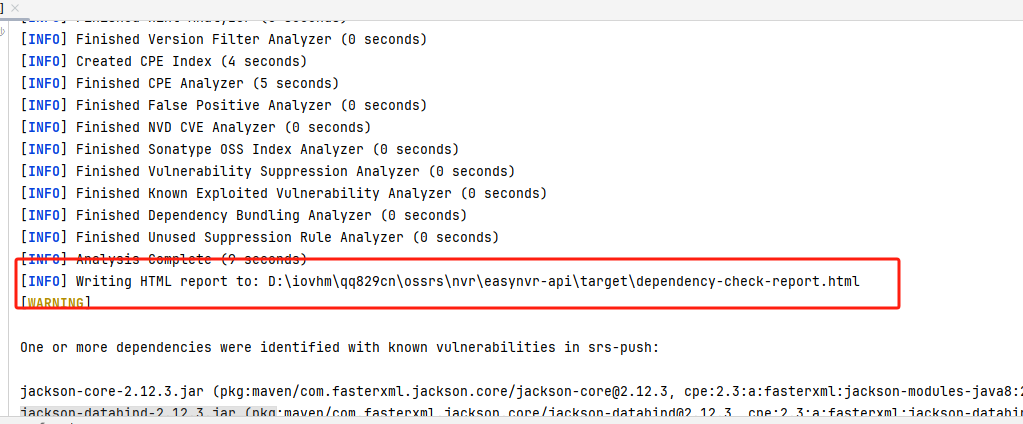
查看扫描报告
我这个项目啥也没有,就检查出这么多问题
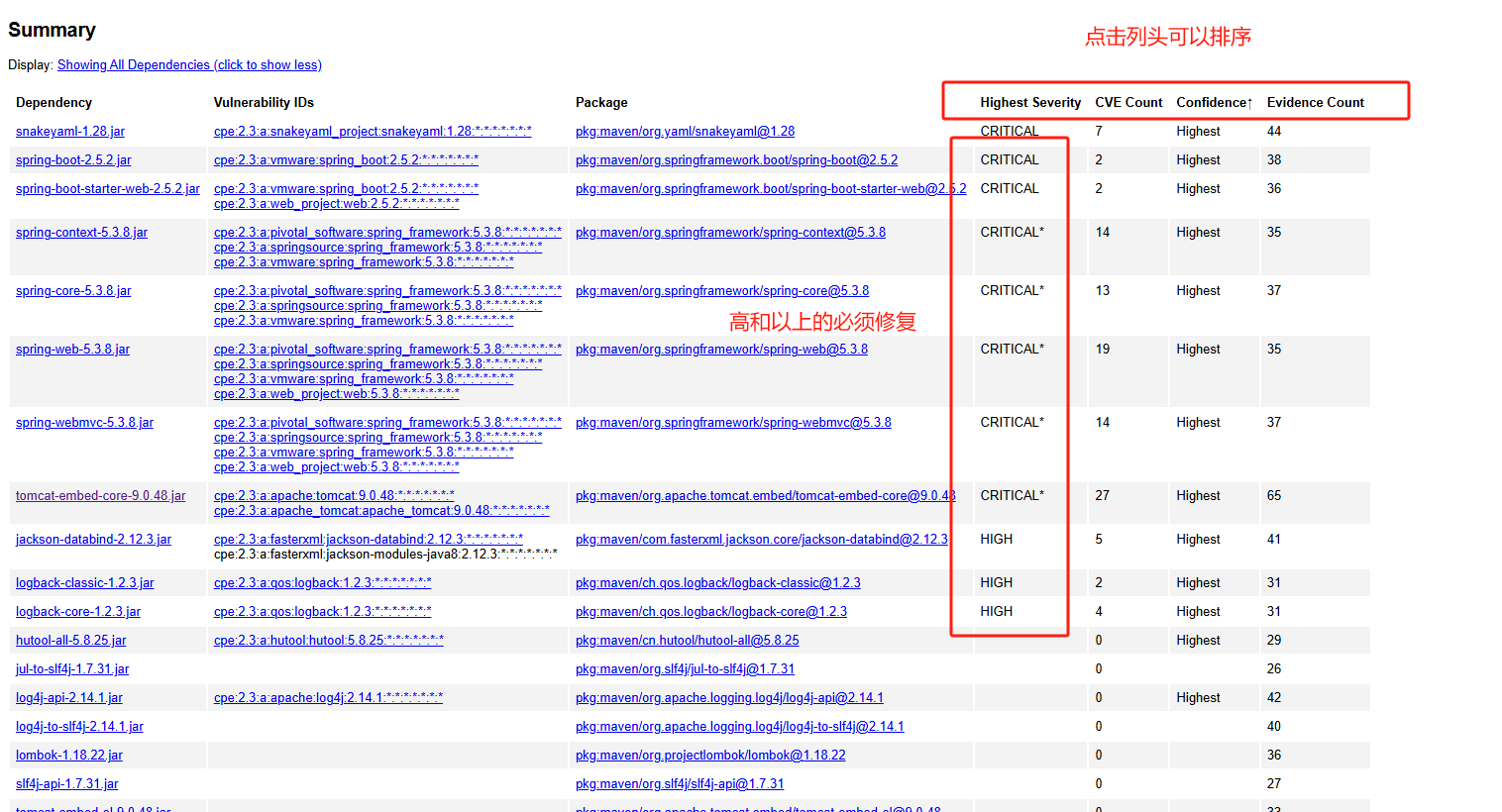
四、漏洞库代理
在没有修改配置的情况下,插件使用美国国家数据库,很慢、半个小时都搞不完,这个时候你需要一个漏洞数据库镜像。
如果你不具备自己搭建漏洞镜像数据库的条件,可以到美国国家数据库申请一个key,会稍微快点,但是还是很慢。
美国国家数据库API_KEY申请(这个KEY在搭建镜像数据库的时候也会用到,记得保存好):https://nvd.nist.gov/developers/request-an-api-key
帮助文档:https://dependency-check.github.io/DependencyCheck/data/mirrornvd.html
帮助文档:https://github.com/jeremylong/open-vulnerability-cli
version: "3"
services:
open-vulnerability-cli:
image: harbor.iovhm.com/hub/jeremylong/open-vulnerability-data-mirror:v9.0.0
container_name: open-vulnerability-cli
restart: always
privileged: true
ports:
- 8089:80
environment:
- TZ=Asia/Shanghai
- NVD_API_KEY=<your_key> # 使用美国国家中心的数据库需要的秘钥
volumes:
- ./cache:/usr/local/apache2/htdocs
# 进入到容器
# docker exec -it open-vulnerability-cli /bin/bash
# 对漏洞数据集进行镜像下载,建议每七天定期执行
# /mirror.sh
# 下载 jsrepository.json ,因为我懒得再去搭建一个服务,我直接在镜像的挂在目录./cache执行了
# wget https://raw.githubusercontent.com/Retirejs/retire.js/master/repository/jsrepository.json
配置mvn项目
<configuration>
<!-- 使用美国国家中心的数据库需要的秘钥,如果配置了镜像可以不需要-->
<nvdApiKey>your_key</nvdApiKey>
<!-- 手动更新漏洞数据库 -->
<autoUpdate>false</autoUpdate>
<!-- nvdcve 漏洞库镜像地址 -->
<nvdDatafeedUrl>https://nvdcve.iovhm.com</nvdDatafeedUrl>
<!-- retire.js 漏洞库镜像地址 -->
<retireJsUrl>http://nvdcve.iovhm.com/jsrepository.json</retireJsUrl>
<!-- 只扫描风险评分大于等于这个数值的,既高危漏洞 -->
<failBuildOnCVSS>7</failBuildOnCVSS>
</configuration>
六、更多工具
https://sonatype.github.io/ossindex-maven/maven-plugin/
mvn org.sonatype.ossindex.maven:ossindex-maven-plugin:audit -f pom.xml
mvn org.sonatype.ossindex.maven:ossindex-maven-plugin:audit-aggregate -f pom.xml
漏洞修复&&springboot&&springframework&&springcloud之间的对照关系
2025年7月17日无安全漏洞的springboot、springframework对照
| springframework | springboot | 发布时间 | 是否失效 |
|---|---|---|---|
| 6.2.9 | 3.5.1-3.5.3 | 2025-07-17 | -- |
| 6.2.8 | 3.4.7 | 2025-06-12 | -- |
| 6.1.21 | 3.3.13 | 2025-06-12 | -- |
漏洞修复顺序
- springframework
- springboot
- springcloud
- 引用频次最高的组件,例如hutool工具包
- 其他包,如果包没有无漏洞版,可以把代码抠出来或者更换组件
spring三大框架(组件)之间的关系
springcloud(微服务增强) -> springboot(web增强) -> springframework(java增强)
-
springframework版本发布页:https://spring.io/projects/spring-framework#learn
-
springboot版本发布页:https://spring.io/projects/spring-boot#learn
-
springcloud版本发布页:https://spring.io/projects/spring-cloud#learn
确定无安全漏洞的springframework版本
单纯的升级springboot、springcloud无法有效解决安全问题
根据 spring 三大框架(组件)之间的关系,出安全问题的通常是springframework的单个组件,例如最喜欢出漏洞的spring-web,或者根据安全扫描结果,优先挑出和springframework相关的。
到中心仓库查询springframework安全情况(需要登陆),也可以在这个网站查询其他包的安全情况:
- 中心仓库安全漏洞查询网站:https://ossindex.sonatype.org/
- 中心仓库spring-web安全漏洞查询: https://ossindex.sonatype.org/component/pkg:maven/org.springframework/spring-web
先确定当前项目的springframework的无漏洞版本、如果当前版本已经停止维护则需要看下一个版本或者更新的版本,正常情况下最新的版本没有安全问题、安全漏洞能得到最快的解决。
-
小版本升级:根据springboot绑定的springframework的大版本,查找小版本是否有无漏洞版本,然后升级到这个无漏洞小版本,如果本大版本下没有无漏洞小版本,则只能进行大版本升级。后面的章节介绍了如何查询springboot版本支持的最大springframework版本方法
-
大版本升级:根据无漏洞版本的springframework匹配springboot版本,升级到对应的版本。
-
直接升级到最新版本
保持版本持续更新、最新是解决安全问题的最有效的办法
springboot和springframework版本绑定关系
方法一:到spring.io网站查询
方法二:到中心仓库查询
-
查询spring-boot-dependencies版本信息:https://central.sonatype.com/artifact/org.springframework.boot/spring-boot-dependencies
-
某一个具体的版本(自行修改后面的版本号):https://central.sonatype.com/artifact/org.springframework.boot/spring-boot-dependencies/3.1.2
查询spring-framework.version字段,如果不凑巧这个版本没有安全版本,则只能继续查询更高版本直到找到springframework的安全版本
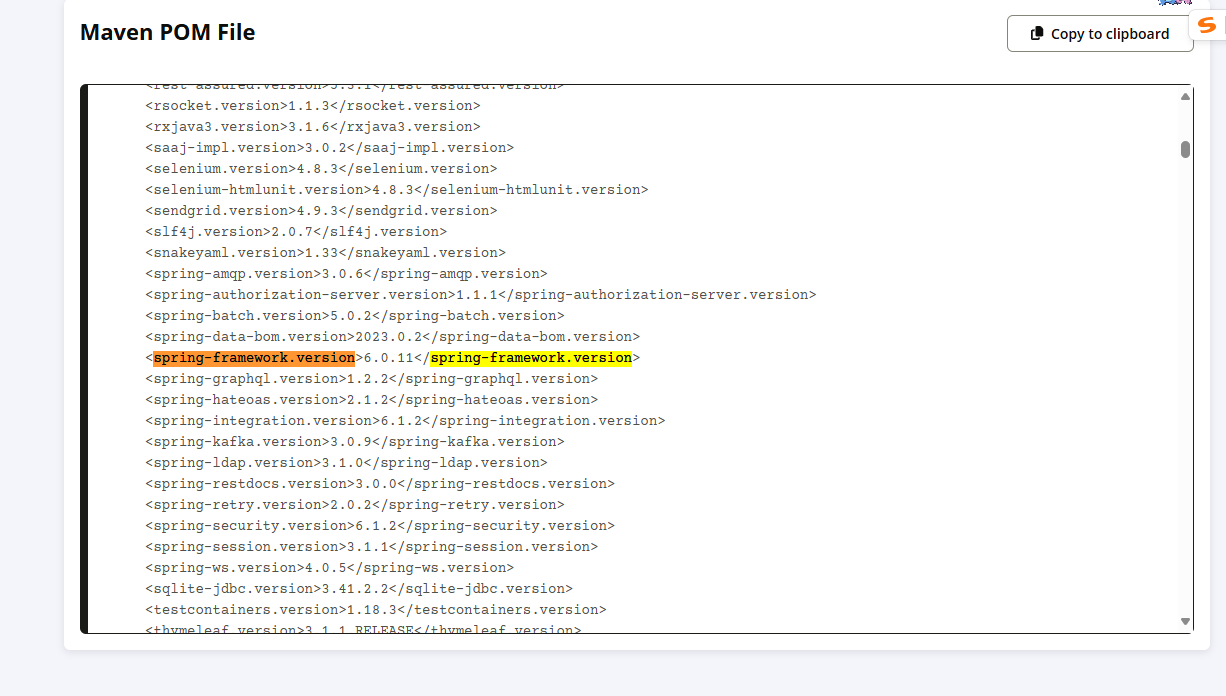
maven版本强行一致方法
父 POM 管版本,子 POM 管依赖
- 父 POM 只放 <dependencyManagement> 或 BOM,不声明实际依赖
<properties>
<spring-boot.version>2.2.6.RELEASE</spring-boot.version>
</properties>
<!-- 依赖声明 -->
<dependencyManagement>
<dependencies>
<!-- SpringBoot的依赖配置 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
<dependencyManagement>
- 子 pom.xml 只写 groupId + artifactId(甚至 scope/classifier),不写 version
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<!-- 版本由父 POM 决定 -->
</dependency>
</dependencies>
使用强依赖插件 maven-enforcer-plugin
插件发布地址:https://central.sonatype.com/artifact/org.apache.maven.plugins/maven-enforcer-plugin
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-enforcer-plugin</artifactId>
<version>3.6.1</version>
<executions>
<execution>
<id>convergence</id>
<goals><goal>enforce</goal></goals>
<configuration>
<rules>
<dependencyConvergence/>
</rules>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
执行验证和编译,此时会提示一堆错误,根据错误提示修复依赖冲突
# 执行验证
mvn validate
# 执行编译
mvn clean install -DskipTests
错误太多修复不过来
可以使用vscode打开项目,在cline窗口输入提示词,让AI帮忙修复
-
指令一(速度快,可能有错误):执行mvn clean validate ,并根据控制台的错误进行问题修复,依照父pom管版本,子pom管依赖原则修复。
-
指令二(执行慢,但是可靠):执行mvn clean install -DskipTests ,并根据控制台的错误进行问题修复,依照父pom管版本,子pom管依赖原则修复。
-
指令三:检查一下项目pom文件,按照 父 POM 管版本,子 POM 管依赖进行调整
建设数据中台、业务中台、物联中台,三中台的必要性
在过去的时间里,我们建设了大量的软件信息化系统、硬件基础设施。在设计和建设时,信息化系统按使用部门的要求建设,重点解决使用部门的痛点,软、硬件协作、独立完成一项工作,软硬件系统作为一个重要工具存在。
随着时间的推移,信息化系统由不同的厂家、在不通的时间、采用不同技术构建,系统和系统之间存在数据不通、技术障碍等因素不能协作;功能存在重复,相同的数据在各信息化系统存在不一致的版本。
信息化系统犹如一个个高大的烟囱,可以独立处理业务功能,却无法组合和发挥更大价值,大量数据闲置,未形成数据资产。信息化停留在工具层面,未能对顶层决策带来有效的支撑,信息化系统呈孤岛态势。
在此背景下,在新的信息化建设规划中,我们提出,在有条件的情况下,优先建设数据中台、业务中台、物联中台,夯实基础,避免过去遇到的问题。 数据中台:通过多种技术手段,直接读取数据库、API采集、导入等多种方式,将同构、异构的数据孤岛,重新汇聚入湖(数据湖);通过对数据的比对、清洗、转换、标准化提炼,形成新的有价值数据;使用数据目录共享和对外发布数据,让其他系统可复用;通过对数据标准和源头的确定,使各系统的数据同源(口径一致)。通过对数据标准的制定,让数据交换共享更便利、不受时间、技术的限制。
因为有了全貌、全量的数据,使信息化系统从工具层面,升华到可决策、可视化、可经营、可管理层面。让信息化系统发挥更大的价值。
业务中台:通过对业务系统的共性功能提取,形成可复用的能力;对共性业务能力集中管理;对共性业务能力目录盘点,识别出既有能力,缺失能力,对信息能力查漏补缺;检索共性业务目录,在新的信息化系统规划阶段,既能有效控制建设范围,避免重新建设,降低新建信息化系统的范围,提高新建信息化的速度,最终达到降本增效的目的。
物联中台:通过对多种设备的抽象、模板、接入、管理,将物联设备产生的数据,抽象到数据中台,将物联能力抽象到业务中台。物联设备不再是独立的存在,将设备数字化后使其拥有更多的能力;根据多种策略,进行联动、告警、控制,实时反映设备状况,使设备也能成为生产经营决策的重要组成部分。
关于xx实验室信息化系统建设的必要性
当前xxx实验室弱电与智能设备已经初步安装完成。实验室做为一个特殊的区域,在有效持续运营方面还存在信息化管理手段缺失。
- 实验室运营方: 实验室的主要资产为实验设备,主要使用单位为科研机构,主要工作内容课题研究,主要输出成果为科研成果。对科研设备的管理,提高设备的利用率,科研过程中的规范管理,安全生产,提高实验室的运作效率、保护科研设备。 实验室管理系统:包括项目管理、实验室预约,安全管理、危化品管理,耗材管理、实验器材共享平台。 科研孵化平台:拉通科研机构与社会力量,将科研结果转换为商用成果,是实验室运营方持续经营的必要手段。 服务共享平台:将实验室的多家科研机构成果共享、协作,共同完成科研任务。
- 主管部门 掌握辖区科研进度,成果转换情况,实验室运作情况。及时根据运营情况调整科研政策。需要相关的数据决策与支撑。 数据中台:通过多种技术手段,直接读取数据库、API采集、导入等多种方式,将同构、异构的数据,从多个专业信息化系统,重新汇聚入湖(数据湖);通过对数据的比对、清洗、转换、标准化提炼,形成新的有价值数据;使用数据目录共享和对外发布数据,让其他系统(单位)可复用;通过对数据标准和源头的确定,使各系统的数据同源(口径一致)。通过对数据标准的制定,让数据交换共享更便利、不受时间、技术的限制。 因为有了全貌、全量的数据,使信息化系统从工具层面,升华到可决策、可视化、可经营、可管理层面。 领导驾驶舱:通过对关键数据指标、关键运营指标、关键设备指标等,进行图形化展示,通过对数字孪生叠加,使整个实验室运营情况可视化,掌握整个实验室的整体运作情况。通过多维度的指标分析,使实验室运行情况可决策、可经营。
- 物业管理方 作为楼宇、设备的维护方,为实验室提供运行保障。需要对物业服务过程优化、协调等。帮助物业管理公司提高工作效率,降低运营成本,提升服务质量,增强客户满意度。让物业管理变得更加智能化、高效化、便捷化。 物业的日常管理包括:人员管理、车辆管理、设备管理、巡更巡检、访客管理、安防告警、房租水电合同管理、保洁任务。通过标准化的管理模型,建立自身知识库,积累和整合自身的经验和优势,提升自身的核心竞争力。 清晰的业务流程明确各岗位职责,规范的业务操作提高各个业务环节的工作效率——软件系统的实施能最大限度的减少管理漏洞,减少人为因素的干预,并提高企业运营和管理效率,支持企业商业目标的实现,从而从根本上提高企业的行业竞争性
运维支持考试题
运维知识考试题
- 1.如何打包docker镜像;
- 2.如何启动一组docker镜像;
- 3.如何查看docker容器的日志;
- 4.Docker默认会将容器镜像下载到/var/lib/docker目录,随着版本的发布、获取新版本镜像,会导致系统磁盘空间不足,如何有效避免这一必现的主机存储不足问题。
- 5.docker容器启动的时候,会自动创建一个docker桥接网络,根据每台主机的性能不同,docker桥接网络的数量可能超过主机限制而无法继续创建容器,在超过限制后如何继续创建docker容器;
- 6.使用docker后,每次重新启动docker容器,其内部数据会被重置,如何实现docker容器内应用数据的持久化放置业务数据丢失;
- 7.当前K8S集群有一台节点坏了,如何合理的退出节点和加入节点;
- 8.解释一下k8s中的deploy,pod,server,configmap,secrets;
- 9.K8s部署容器的时候,使用的镜像是私有镜像仓库、仓库有密码有认证时,如何正确拉取到镜像;
- 10.某些容器需要调用更多的系统能力,在K8S网络该如何设置;
- 11.某个应用因为管理要求,仅能在某个主机节点调度,请问在K8S网络如何调度;
- 12.K8s默认采用http访问后端,当前有一个后端必须要用https访问,请问能正确访问到后端,当前k8s集群使用nginx-ingress;
- 13.在K8S部署好的应用上传文件的时候,时提示文件太大,当前使用nginx-ingress;
- 14.如何统一设置k8s网络的https的证书,而不是在每个ingress单独设置https证书,当前使用nginx-ingress;
- 15.K8s集群内部各组件使用https证书通讯,k8s内置的https证书默认为一年,请问如何续期k8s集群组件的https证书
- 16.我们通常使用ping来确定主机是否在线,但是linux的ping会持续,主机监控系统因为ping没有返回,而无法确定主机是否在线,请问应该如何让监控系统正确得到ping的返回结果;
- 17.如何确定k8s集群是否正常;
- 18.如何批量查询、删除K8S集群中的不正常pod;
- 19.如何测试磁盘写入、读取速度;
- 20.在某些自建机房中,禁止了网络环路,而导致不能直接在内部使用服务公布的域名访问,而内部服务发现与调用又仅支持域名访问,请问要如何访问;
- 21.某个正常访问的服务,突然发生了外部网络不可达错误,请简要描述排查步骤;
- 22.当前有一个k8s 部署运行不起来,连pod都没有创建,请问如何排除容器运行不起来的原因;
- 23.如何对容器做jvm限制;
- 24.当前有一个Java开发的项目,根据前面的容器打包方式已经打包为docker镜像并部署到了k8s网络,研发人员告知,当前项目下需要使用prod配置文件,请问如何在不更改docker镜像的情况下指定当前应用程序的运行环境配置文件。
- 25.K8s内有两个项目,如何在这两个项目之间进行服务调用,而不是通过对外公布的服务又从外网接入损失流量和性能。
- 26.K8s容器网络ping不通;
- 27.Nginx的local或proxy_pass有带有 反斜杠(/)和不带反斜杠(/)二者之间有什么区别;
- 28.有一个后端服务,后端没有做身份认证,现找不到服务厂商维护、没有源代码,现在因为管理要求,需要对这个服务做身份认证,请问如何管理;
- 29.当前在linux排除问题,但是后端服务限制了近能使用域名访问,该如何排查;
- 30.linux常用的主机性能查看命令例如、磁盘、内存、CPU、网络等命令;
- 31.如何设置linux服务器密码过期策略(180天);
- 32.如何查看mysql的主要性能指标参数;
- 33.如何确定和使用mysql的慢日志;
- 34.如何确定和使用mysql的性能分析模式分析mysql优化项;
- 35.如何设置mysql的密码过期策略(180天);
- 36.如何备份和恢复mysql数据库,并只做一个定时任务来定期备份数据库;
- 37.解释一下华为云的elb的实例、监听器、转发器、后端组分别代表的什么意思;
jvm常见参数
四个重要参数 -Xms、-Xmx、GC算法、-XX:MaxMetaspaceSize
使用环境变量设置
JAVA_TOOL_OPTIONS="-Xms3g -Xmx3g -XX:MaxMetaspaceSize=2048m -XX:+UseG1GC"
# -Xms 初始化堆大小
# -Xmx 最大堆大小
# -Xss 每个线程的栈大小(可以不设置)
# -Xms和-Xmx应该设置为一样的值,如果没有设置,默认值为物理内存的1/4
# -XX:+UseG1GC GC算法,小于32G内存
# -XX:+UseZGC GC算法,大于32G内存
在java -jar 命令中设置
java -Xms3g -Xmx3g -XX:MaxMetaspaceSize=2048m -XX:+UseG1GC -jar app.jar
参数参考
计算可分配内存大小:
- 物理内存的75%
- 总的物理内存 减 操作系统需要的(8G),在除以实例数,就是每个实例可以分配的内存
Xms和Xmx应该设置成一样的,避免反复GC,如果没有设置,默认值为物理内存的1/4
-XX:MaxMetaspaceSize , 元数据空间存放的是类的结构信息、方法的字节码、常量池、注解、泛型信息等。意思是动态加载的反射、代理、AOP等都会缓存下来。他的作用是放置加载过多的类把内存用尽了。数值选择是-Xmx的10%。也可以直接使用最大值2G,元数据空间不可能大于2G
GC算法:
-XX:+UseG1GC // ≤32 g 堆
-XX:+UseZGC // >32 g 或低延迟场景
查看内存使用情况
ps -p 24053 -o pid,vsz,rss,comm
# <PID>:替换为你要查看的进程 ID。
# vsz:虚拟内存大小(单位:KB)。
# rss:实际占用的物理内存(单位:KB)。
# comm:进程名。
cat /proc/24053/status |grep -i vm
# VmSize:虚拟内存总量(KB)。
# VmRSS:实际使用的物理内存(KB)。
# VmData:数据段大小。
# VmStk:栈大小。
# VmExe:代码段大小。
axure私有分享配置方法
一、点击分享按钮
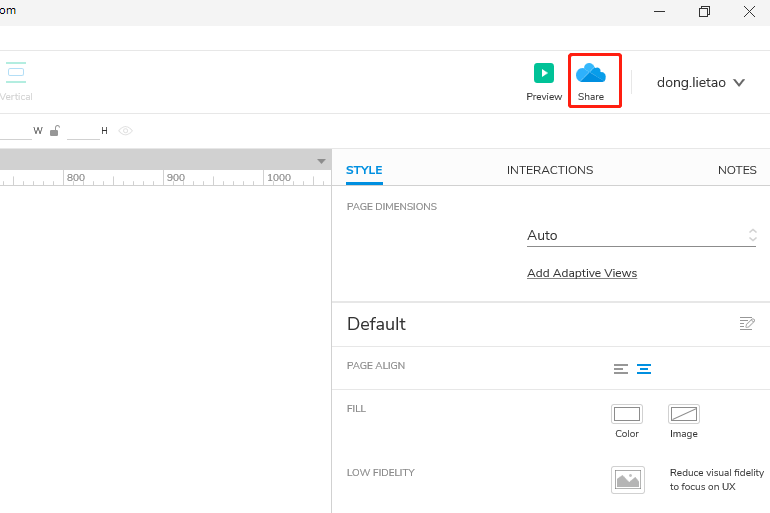
二、点击服务器管理按钮
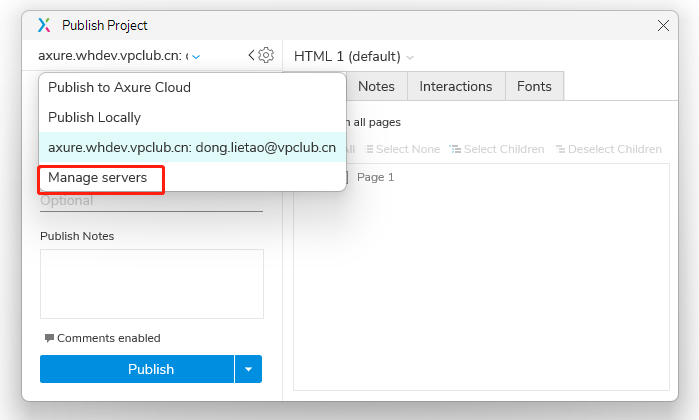
三、增加一个新的私有化存储
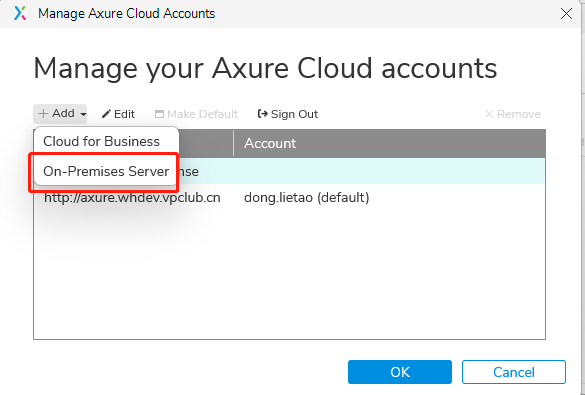
四、填入私有化配置

地址填入: http://axure.whdev.vpclub.cn
注意,要写正确,比如下面的写法都不行
axure.whdev.vpclub.cn
http://axure.whdev.vpclub.cn/
五、设置为默认发布通道
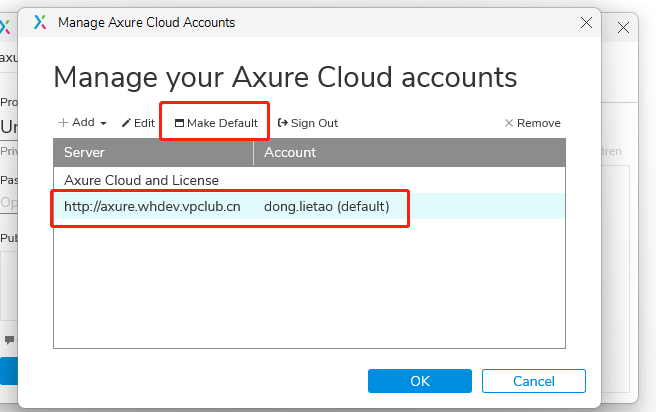
六、设置项目名称,选择存储位置,分享
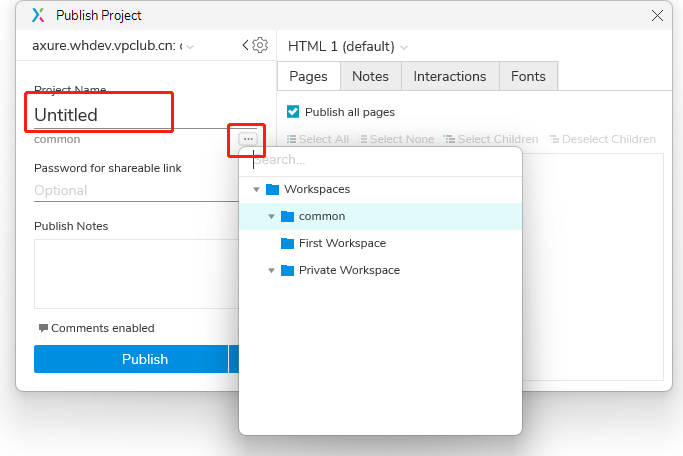
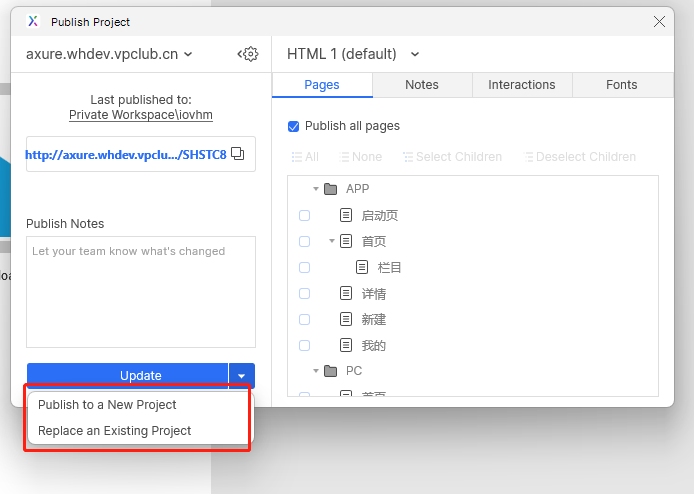
如果是已经发布过的项目,会自动更新,如果要换一个新的位置存储,可以选择publish to a new project 。 如果是要覆盖掉其他项目,可以选择replace an existing project 。
点击发布之后就可以得到共享路径。
markdown可视化编辑工具
可视化markdown编辑软件 typora
下载地址:https://iovhm.com/uploads/software/typora.zip
导出为word依赖
pandoc-3.8.3-windows-x86_64: https://iovhm.com/book/attachments/23
本网站下的所有qq829.cn的域名都被更换为iovhm.com
本网站下的所有qq829.cn的域名都被更换为iovhm.com
好用的项目管理软件分享
万兴脑图
https://edraw.wondershare.cn/mindmaster/

万兴项管(平替project)
https://edraw.wondershare.cn/edrawproject/
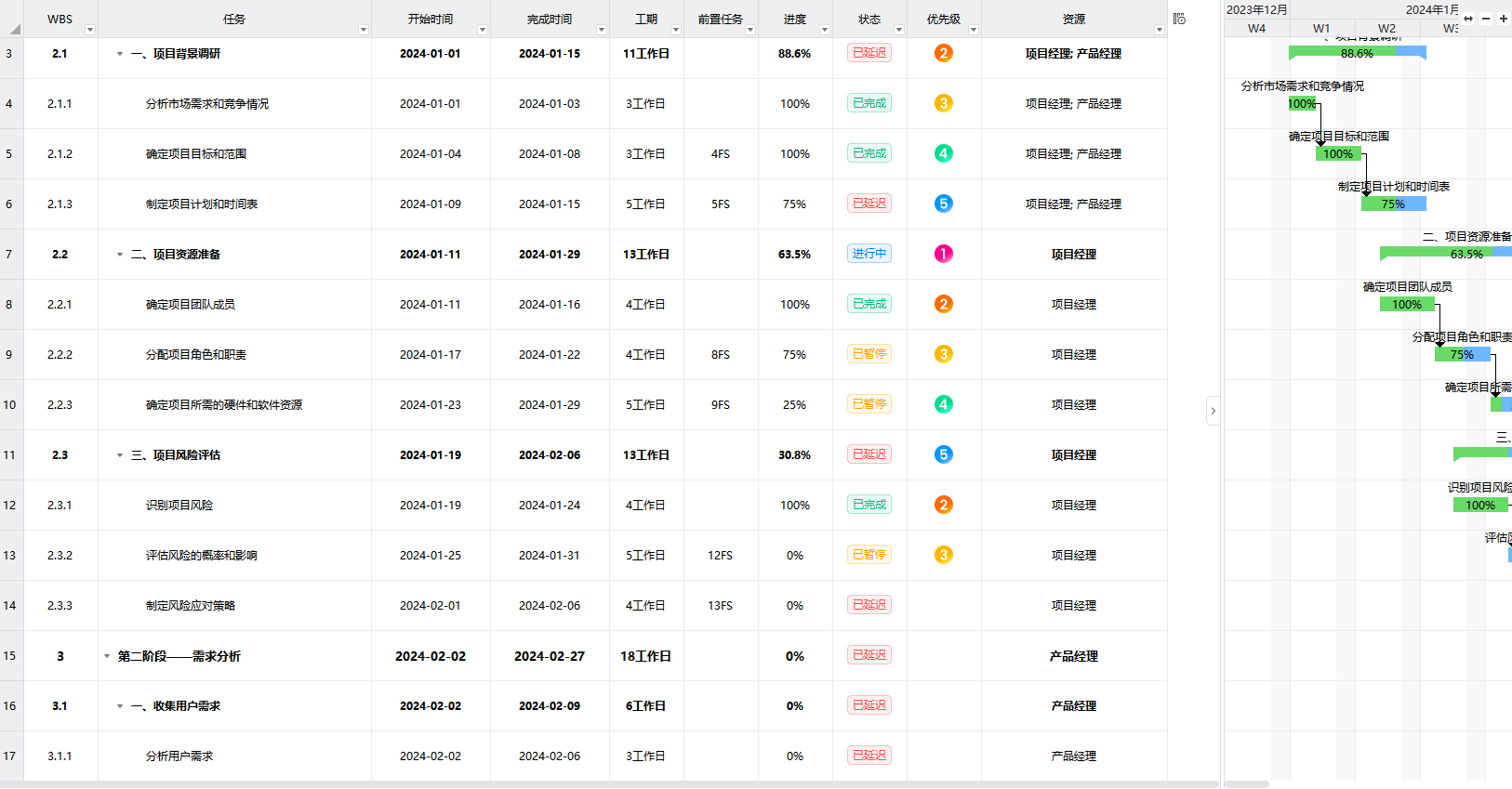
万兴画板
https://edraw.wondershare.cn/edrawboard/
万兴图示(平替viso)
https://edraw.wondershare.cn/edrawmax/
软件系统开发流程
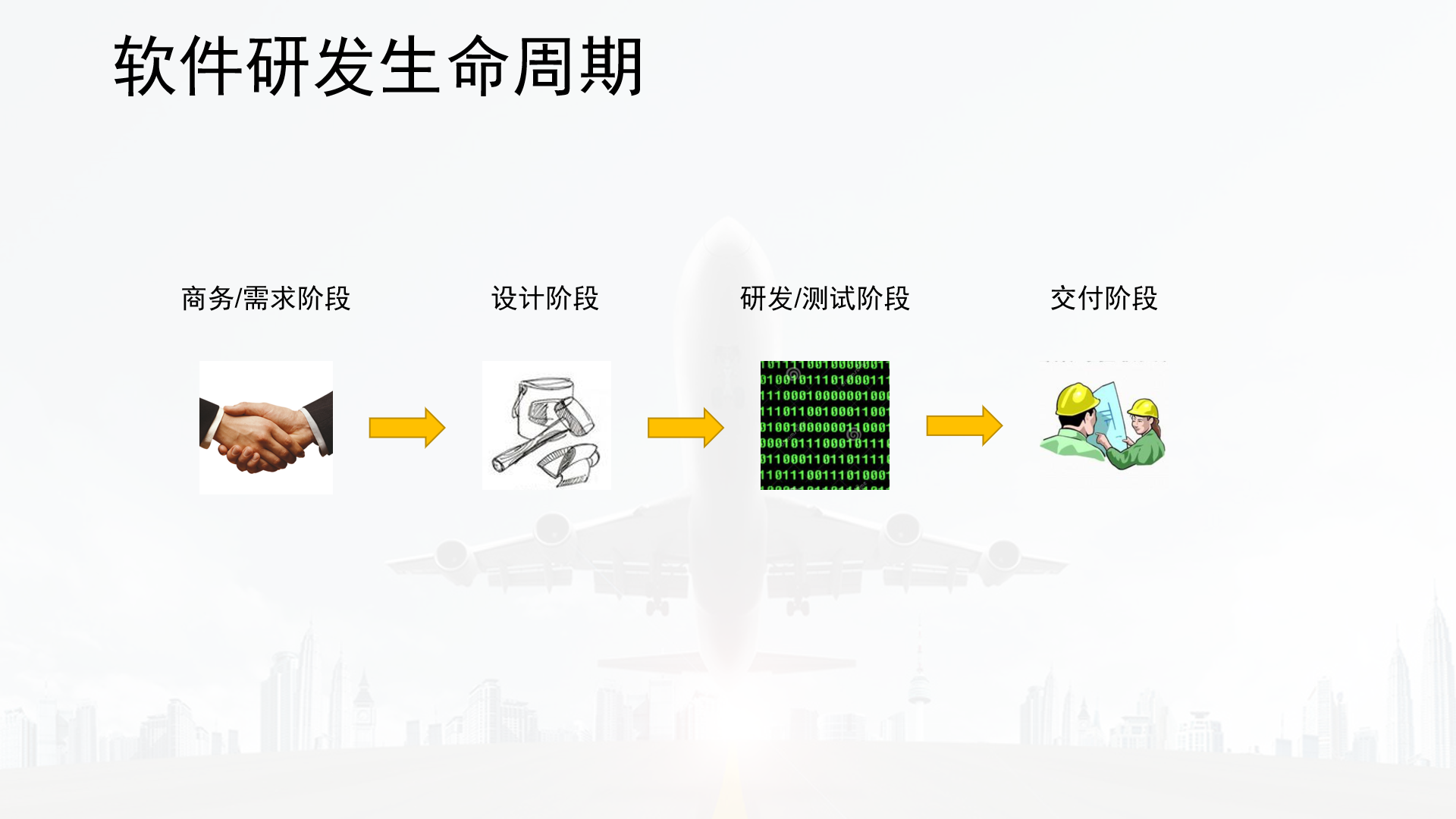
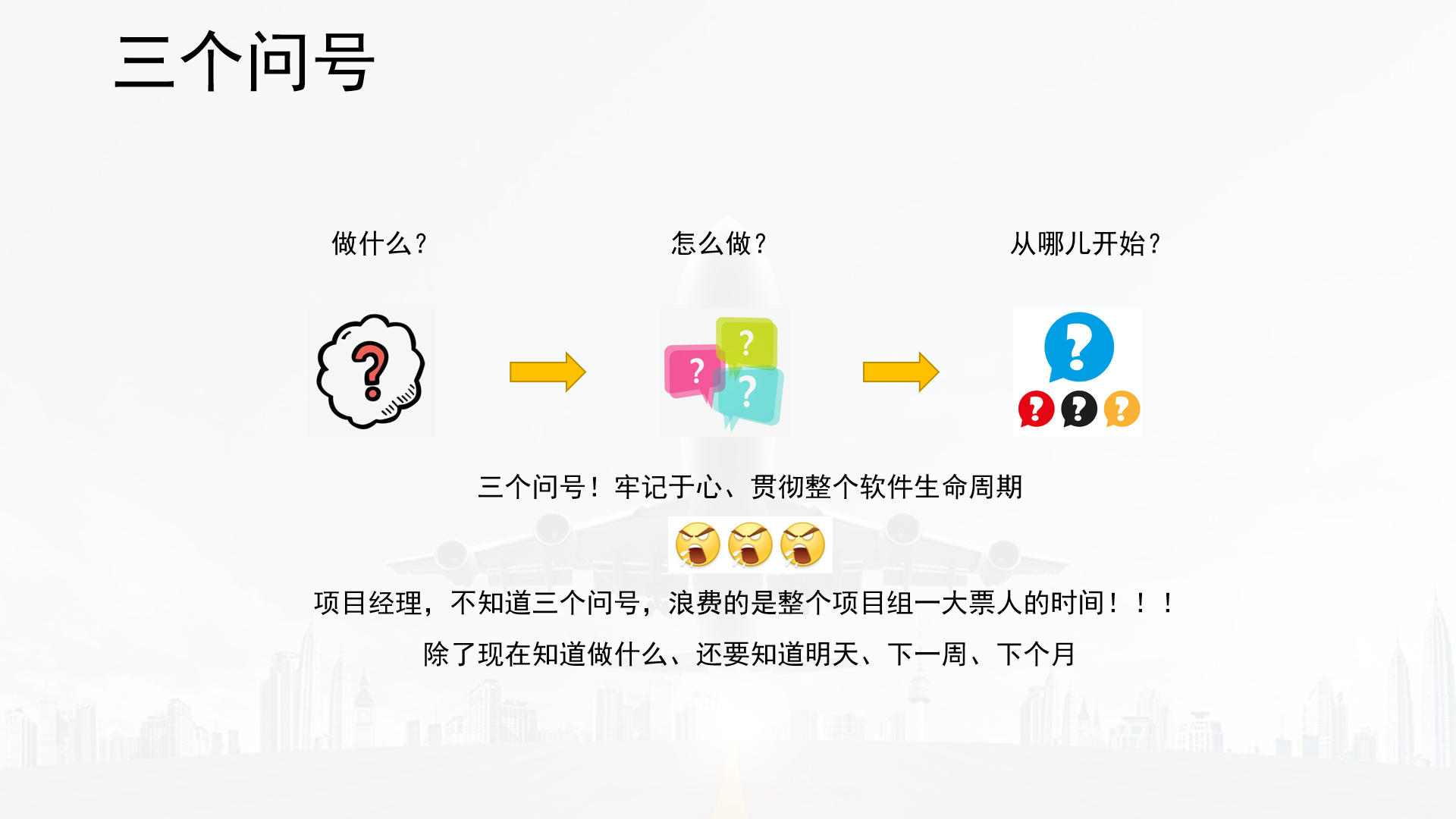




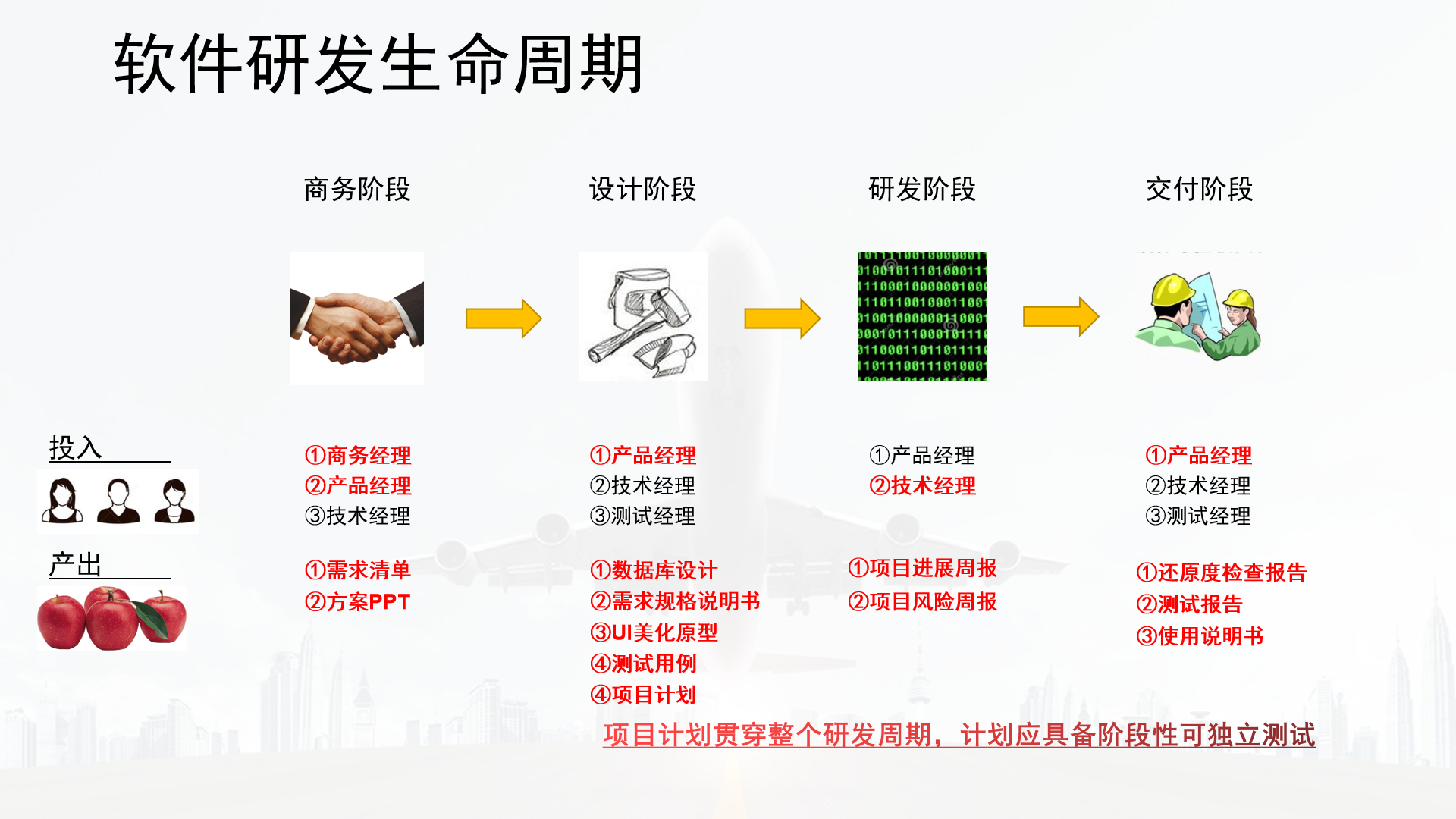
安装claude
准备工作
- 官方帮助: https://code.claude.com/docs/en/getting-started#native-install-recommended
- 科学上网: https://iovhm.com/book/books/cee63/page/0a09c
- 需要nodejs: https://nodejs.org/en/download
安装 claude code
windows操作系统
# windows
# 如果出现403,可以只打开浏览器下载install.cmd 然后再执行install.cmd
curl -fsSL https://claude.ai/install.cmd -o install.cmd && install.cmd && del install.cmd
# 使用winget安装
winget install Anthropic.ClaudeCode
macOS, Linux, WSL 操作系统
# macOS, Linux, WSL
# 如果出现403,可以只打开浏览器下载install.sh 然后再执行install.sh
curl -fsSL https://claude.ai/install.sh | bash
使用npm安装
# 2026年4月14日,claude 官方宣布不再支持使用npm安装,
# 请到官方网站查看安装方法 https://code.claude.com/docs/en/getting-started#native-install-recommended
npm install -g @anthropic-ai/claude-code
配置 claude code
配置 settings.json
创建配置文件文件夹,
使用命令创建
mkdir "%USERPROFILE%\.claude"
或者手工创建:
C:\Users\你的用户名\.claude\settings.json
{
"env": {
"ANTHROPIC_BASE_URL": "https://dashscope.aliyuncs.com/apps/anthropic",
"ANTHROPIC_AUTH_TOKEN": "sk-********************************************",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "qwen3.5-plus",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "MiniMax-M2.5",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-5"
}
}
# 下面这几行注释不要复制进去
# 其他可用的模型
# qwen3.5-plus
# qwen3-coder-plus
# deepseek-r1
# deepseek-v3.2
# qwen3-vl-plus
# kimi-k2.5
# glm-5
# MiniMax-M2.5
.claude.json(可以不需要,会自动创建,但是需要查看其中的参数)
C:\Users\您的用户名\.claude.json
{
"hasCompletedOnboarding": true
}
测试一下
# 打开命令行
claude
# 继续提问
你是谁,你现在用的什么模型
idea中使用claude code
需要最新版的idea
- https://www.jetbrains.com/zh-cn/idea/download/?section=windows
需要nodejs
- https://nodejs.org/en/download
方法一:使用终端(推荐,不局限于IDE)
打开终端运行claude
选择需要修改的代码进行提问
使用ctrl+alt+k引用代码文件,在复制代码片段
方法二:使用插件
安装idea插件
使用插件
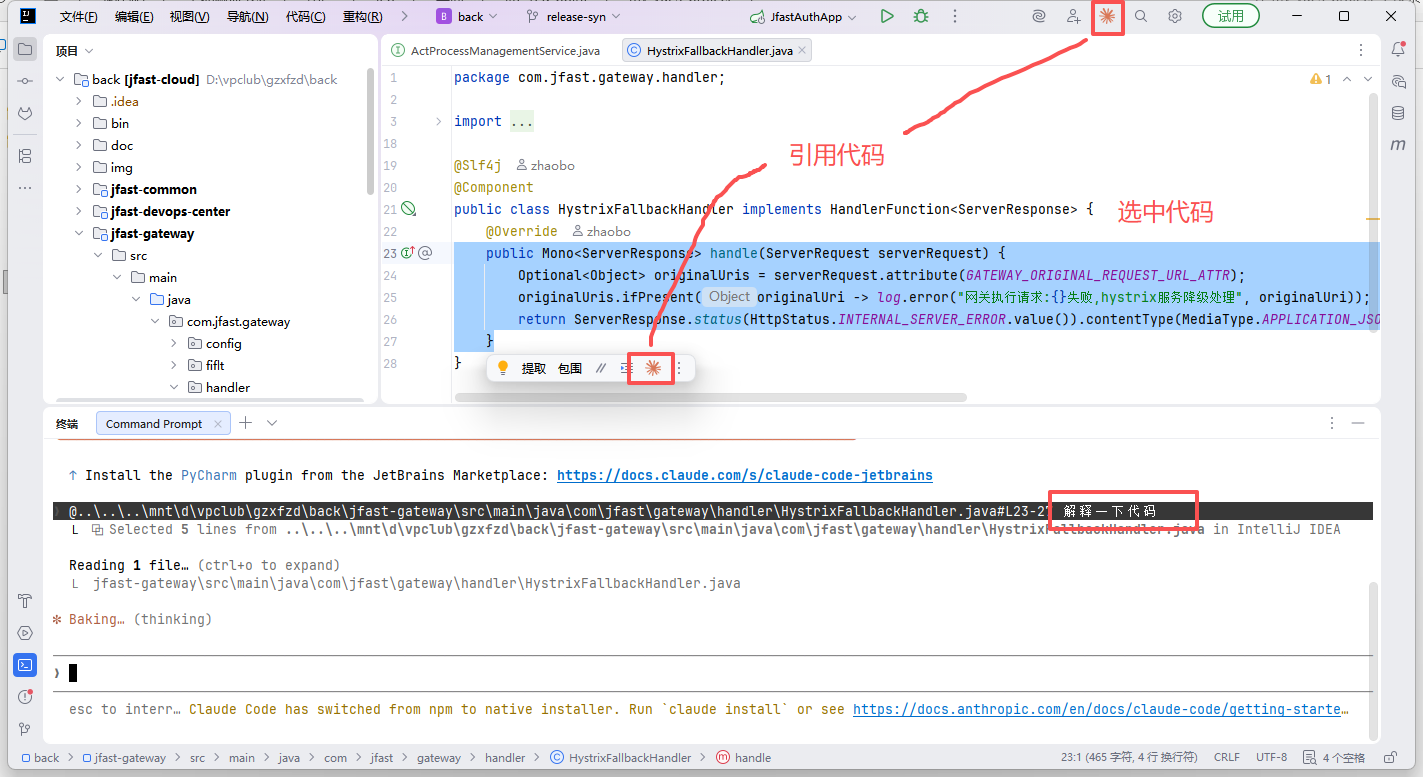
在vscode中使用claude code
安装和配置claude
https://iovhm.com/book/books/bbcbf/page/ideaclaude-code
方法一:使用终端(推荐,不局限于IDE)
打开终端,输入claude
选择需要修改的代码进行提问
将文件和代码拖入到终端女窗口
方法二:使用vscode插件
配置插件
填入你的模型提供商的模型ID
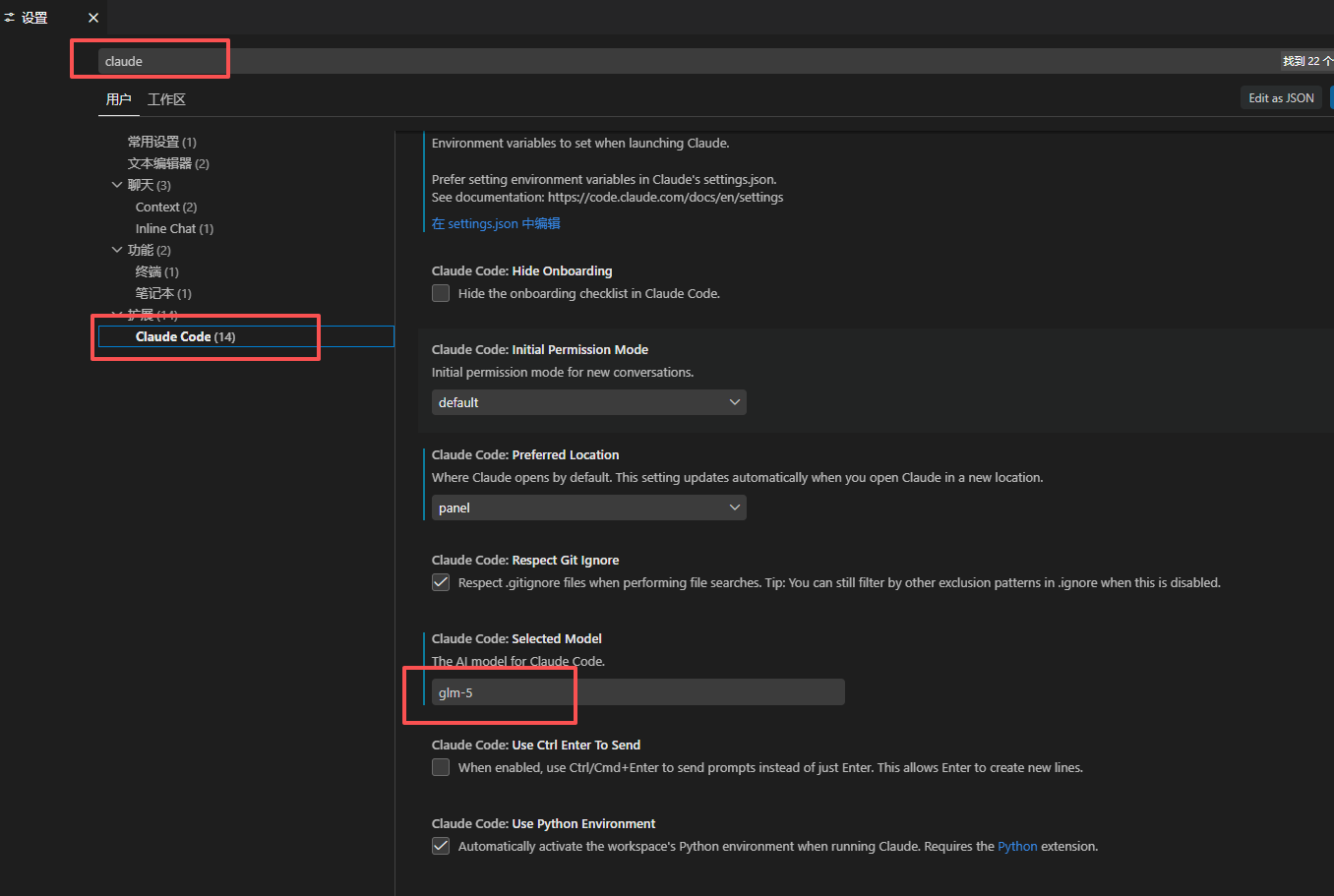
测试一下
AI生成成套文档
使用openclaw进行软件开发前中期系统设计分析
实现思考
- 将excel转换为md
- 软件架构重组,将软件存在关联关系、散落在不同地方的功能进行模块化拆解、领域建模和架构重构
- 根据原始功能清单 和 重组架构 细化功能清单
- 验证细化清单完整、闭环覆盖了原始功能清单
- 评估工时
为避免小助手串记忆,应该新建一个智能体
# 增加一个agent
# 可以想象为 openclaw 提供了一个工作场所,每一个 agent 就是一个数字员工,独立的 agent 不干涉记忆
# 名称不支持中文
openclaw agents add qianshitong-cool-park --workspace "D:\招投标项目\千视通-冷链物流园园区"
将原始文档转换为AI更友好的MD格式
如果有多个sheet,应该将每一个sheet单独保存为一个excel文件
将 D:\招投标项目\千视通-冷链物流园园区\智慧园区运营管理平台.xlsx 输出为md格式
重组软件架构
深度分析以下原始需求清单:
- D:\招投标项目\千视通-冷链物流园园区\智慧园区运营管理平台-原始功能清单.md
对上述功能清单进行领域建模与架构重构。请打破原有文档的线性列表结构,按照“高内聚、低耦合”的原则,将零散的功能点重新归纳、合并与拆解。构建清晰的 子系统 -> 模块 -> 组件 三级架构体系。
最终产出的架构方案需满足以下工程化标准:
- 独立开发:各模块边界清晰,接口定义明确。
- 独立测试:模块可隔离进行单元测试或集成测试。
- 独立部署:支持微服务化或组件化安装,可单独发布与升级。
细化功能清单
这是一份初步的功能清单(可能粗糙、不完整、描述模糊)
- D:\招投标项目\千视通-冷链物流园园区\智慧园区运营管理平台-原始功能清单.md
- D:\招投标项目\千视通-冷链物流园园区\智慧园区运营管理平台-领域架构设计.md
需要将粗糙的功能清单转化为细化的功能点清单,对每个原始条目进行拆解、分析、补齐。使功能清单完整、闭环、可验证。输出新的功能清单,并备注需求来源。
与原始需求对比
与原始功能清单对比,检查新的功能清单是否已经全覆盖、完整、闭环、可验证。
全成本评估
按照软件开发流程(调研、需求、设计、编码、测试、部署、上线、培训、验收、运维),按照一个三年工作经验的全栈工程师(springboot、vue、mysql、docker、k8s),评估交付工作量(按天),交付成本评估(1000元/人天)。
开发成本评估
直接开发成本评估,不包括首年运维费用、服务器硬件采购/租用,其他采购成本。
降本增效措施
匹配到原始报价清单
按原始功能清单格式,将人天进行进行匹配
使用openclaw进行软件开发前中期系统设计分析
实现思考
- 将excel转换为md
- 软件架构重组,将软件存在关联关系、散落在不同地方的功能进行模块化拆解、领域建模和架构重构
- 根据原始功能清单 和 重组架构 细化功能清单
- 验证细化清单完整、闭环覆盖了原始功能清单
- 评估工时
已经编写好的技能分享
software-pre-design.zip: https://iovhm.com/book/attachments/26
安装技能
将文件解压缩后放到。一个技能一个文件夹
- windows
C:\Users\你的用户名\.openclaw\skills
- mac
~/.openclaw/skills
ai生成各种软件架构图示
图示在cursor和openclaw中测试通过
工具
下载地址:https://github.com/jgraph/drawio-desktop/releases/
图的名称一定要说清楚,图的格式一定要说清楚:帮我生成xxxx图,使用draw.io格式,
逻辑流程图
绘制一个用户登录逻辑流程图,使用draw.io格式
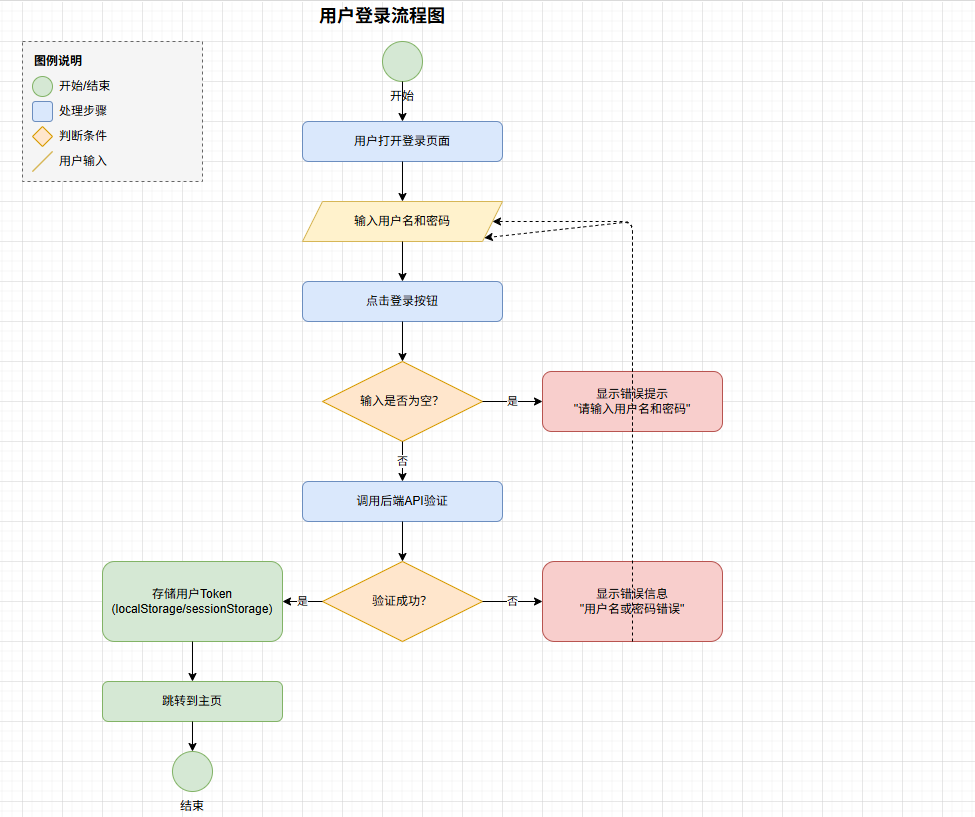
时序图
绘制一个用户登录时序图,使用draw.io格式
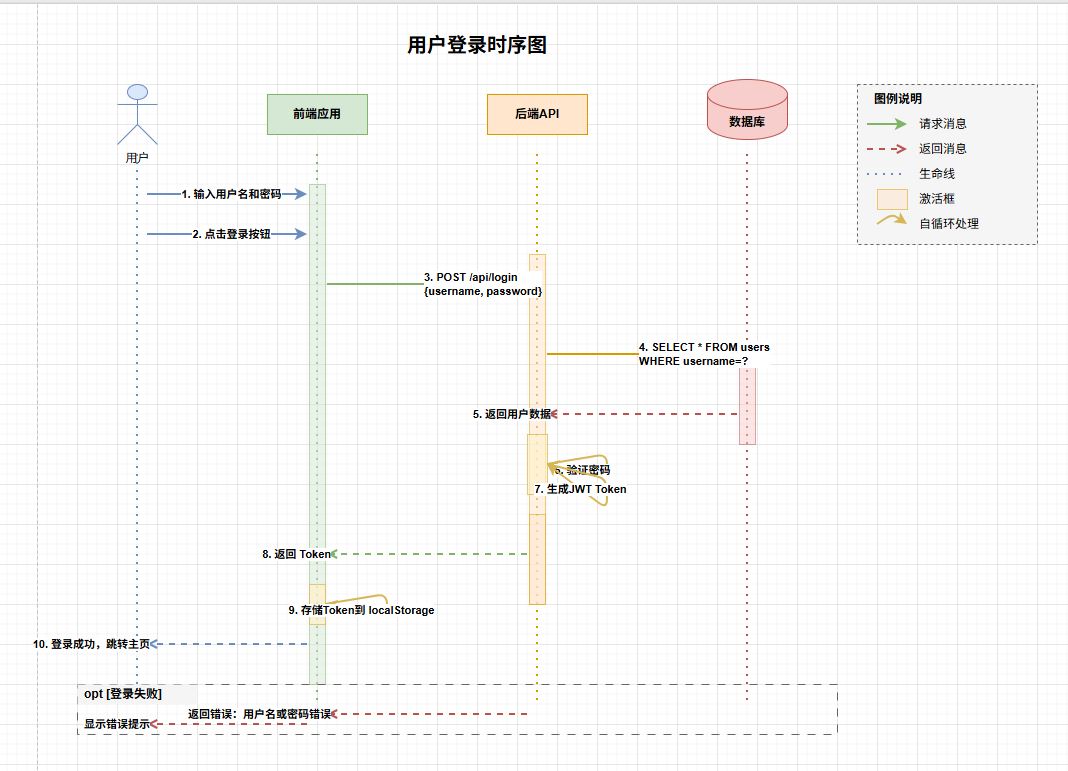
纵向泳道跨职能流程图
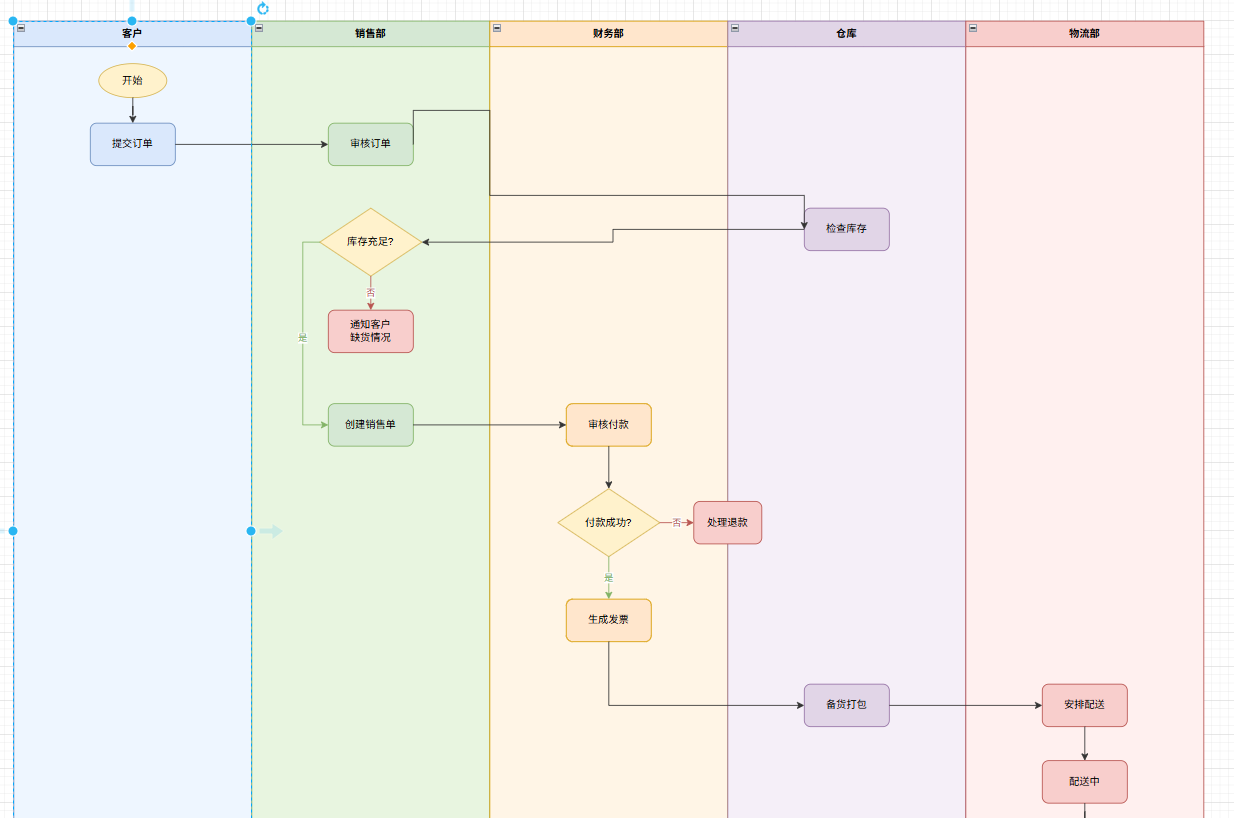
横向泳道跨职能流程图
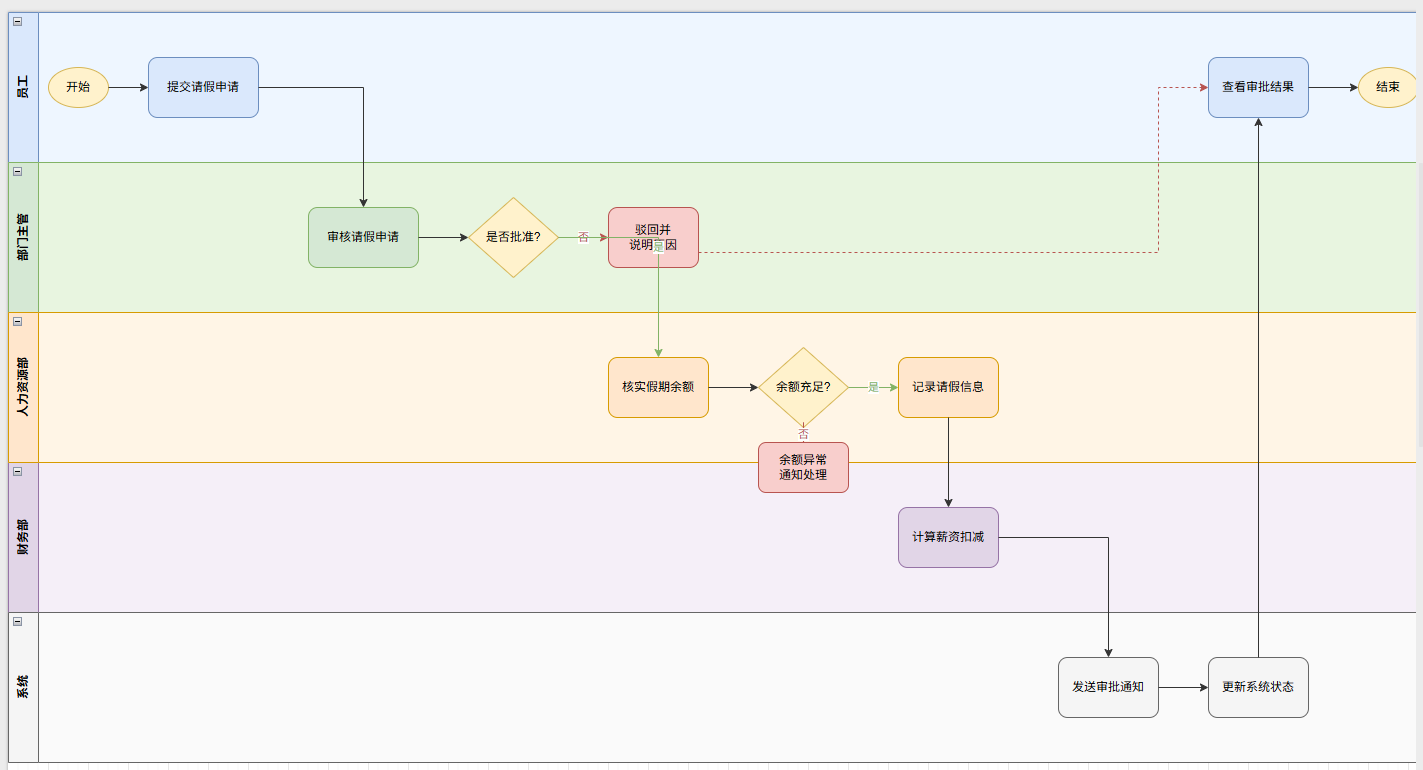
系统功能模块架构图
深度分析以下原始需求清单:
- D:\招投标项目\综合门户.xlsx
- D:\招投标项目\园区服务.xlsx
上述功能清单进行领域建模与架构重构。请打破原有文档的线性列表结构,按照“高内聚、低耦合”的原则,将零散的功能点重新归纳、合并与拆解。
构建清晰的 子系统 -> 模块 -> 组件 三级架构体系。
最终产出的架构方案需满足以下工程化标准:
独立开发:各模块边界清晰,接口定义明确。
独立测试:模块可隔离进行单元测试或集成测试。
独立部署:支持微服务化或组件化安装,可单独发布与升级。
AI生成成套文档-01-立项报告
# 立项报告
## 1. 文档信息
| 项目名称 | |
|---------|--|
| 文档版本 | v1.0 |
| 编写日期 | |
| 编写人员 | |
| 审核人员 | |
| 批准人员 | |
---
**文档修订历史**
| 版本号 | 修订日期 | 修订人员 | 修订内容 |
|--------|---------|---------|---------|
| v1.0 | | | 初始版本 |
## 2. 项目背景
### 2.1 业务背景
描述项目的业务背景,包括:
- 当前业务现状
- 存在的问题和痛点
- 业务发展需求
### 2.2 市场背景
- 市场环境分析
- 行业发展趋势
- 竞争对手分析
### 2.3 技术背景
- 现有技术架构
- 技术发展趋势
- 技术选型考虑
## 3. 项目目标
### 3.1 业务目标
- 目标1:描述具体的业务目标
- 目标2:描述具体的业务目标
- 目标3:描述具体的业务目标
### 3.2 技术目标
- 目标1:描述具体的技术目标
- 目标2:描述具体的技术目标
- 目标3:描述具体的技术目标
### 3.3 质量目标
- 性能指标
- 可用性指标
- 安全性指标
- 其他质量指标
### 3.4 成功标准
明确项目成功的衡量标准。
## 4. 项目范围
### 4.1 项目包含内容
- 功能范围
- 技术范围
- 业务范围
### 4.2 项目不包含内容
- 明确不在项目范围内的内容
- 后续版本考虑的内容
### 4.3 项目边界
- 与其他系统的边界
- 与现有系统的关系
## 5. 项目可行性分析
### 5.1 技术可行性
#### 5.1.1 技术方案
- 技术架构方案
- 关键技术选型
- 技术难点分析
#### 5.1.2 技术风险
| 风险项 | 风险描述 | 风险等级 | 应对措施 |
|--------|---------|---------|---------|
| | | | |
| | | | |
#### 5.1.3 技术可行性结论
- 技术可行性评估结果
### 5.2 经济可行性
#### 5.2.1 项目投资估算
| 成本项 | 金额 | 说明 |
|--------|------|------|
| 人力成本 | | |
| 设备成本 | | |
| 软件成本 | | |
| 其他成本 | | |
| **合计** | | |
#### 5.2.2 项目收益分析
- 直接收益
- 间接收益
- 成本节约
- 收益预测
#### 5.2.3 投资回报分析
- 投资回报周期
- 投资回报率
- 净现值分析
#### 5.2.4 经济可行性结论
- 经济可行性评估结果
### 5.3 组织可行性
#### 5.3.1 组织架构
- 项目组织架构
- 角色职责
#### 5.3.2 人力资源
| 角色 | 人数 | 技能要求 | 来源 |
|------|------|---------|------|
| 项目经理 | | | |
| 需求分析师 | | | |
| 系统架构师 | | | |
| 开发人员 | | | |
| 测试人员 | | | |
| 其他 | | | |
#### 5.3.3 组织可行性结论
- 组织可行性评估结果
### 5.4 时间可行性
#### 5.4.1 项目时间计划
- 项目总体时间安排
- 关键里程碑
#### 5.4.2 时间风险
- 时间风险分析
- 应对措施
#### 5.4.3 时间可行性结论
- 时间可行性评估结果
## 6. 项目方案
### 6.1 总体方案
- 方案概述
- 方案架构
- 方案特点
### 6.2 技术方案
#### 6.2.1 系统架构
- 架构设计
- 架构图
#### 6.2.2 技术选型
| 技术项 | 选型 | 理由 |
|--------|------|------|
| 开发语言 | | |
| 框架 | | |
| 数据库 | | |
| 中间件 | | |
| 其他 | | |
#### 6.2.3 关键技术
- 关键技术点1
- 关键技术点2
- 关键技术点3
### 6.3 功能方案
- 主要功能模块
- 功能特点
### 6.4 实施方案
- 实施策略
- 实施步骤
- 实施计划
## 7. 项目计划
### 7.1 项目时间计划
| 阶段 | 开始时间 | 结束时间 | 工期 | 主要工作 |
|------|---------|---------|------|---------|
| 需求分析 | | | | |
| 系统设计 | | | | |
| 编码实现 | | | | |
| 系统测试 | | | | |
| 上线部署 | | | | |
### 7.2 项目里程碑
| 里程碑 | 计划时间 | 交付物 |
|--------|---------|--------|
| | | |
| | | |
### 7.3 资源计划
- 人力资源计划
- 设备资源计划
- 软件资源计划
### 7.4 预算计划
- 预算分配
- 预算控制措施
## 8. 项目风险
### 8.1 风险识别
| 风险类别 | 风险描述 | 风险等级 | 影响 | 应对措施 | 责任人 |
|---------|---------|---------|------|---------|--------|
| 技术风险 | | | | | |
| 进度风险 | | | | | |
| 质量风险 | | | | | |
| 资源风险 | | | | | |
| 其他风险 | | | | | |
### 8.2 风险应对策略
- 风险预防措施
- 风险应对预案
## 9. 项目组织
### 9.1 项目组织架构
- 组织架构图
- 组织说明
### 9.2 项目团队
| 姓名 | 角色 | 职责 | 联系方式 |
|------|------|------|---------|
| | | | |
| | | | |
### 9.3 职责分工
- 各角色职责说明
## 10. 项目效益
### 10.1 业务效益
- 业务效率提升
- 业务质量改善
- 业务创新
### 10.2 技术效益
- 技术能力提升
- 技术积累
- 技术复用
### 10.3 经济效益
- 直接经济效益
- 间接经济效益
- 成本节约
### 10.4 社会效益
- 社会影响
- 行业贡献
## 11. 结论与建议
### 11.1 可行性结论
- 综合可行性评估
- 项目可行性结论
### 11.2 建议
- 项目建议
- 实施建议
### 11.3 审批意见
| 审批人 | 角色 | 审批意见 | 日期 |
|--------|------|---------|------|
| | | | |
| | | | |
## 12. 立项决议
经审议,**同意立项**。决议如下:
**项目经理任命**:任命董列涛为项目经理,负责项目整体计划、协调及交付管理。
**协同要求**:财务部、人力资源部、运维支撑团队等部门务必密切配合,保障项目按期交付。
AI生成成套文档-02-1-功能清单
重要提示:AI可能生成超过范围、很难实现的功能,一定要人工在核查一遍
现实就是这么残酷,说一千遍我们有实力,但是拿不出足够详实的功能清单就无法得到好的报价
并不是大家实力不济,是精力有限、无法方方面面考虑到。
先编写基础功能清单
我们绞尽脑汁或者参照竞品系统、已有系统也只写了11条功能清单,这个清单拿出去最多报价10万,如果我们想报价40万怎么搞呢,那就只能细化功能清单,丰富工作内容。但是,又不能真的给自己制造这么多工作量
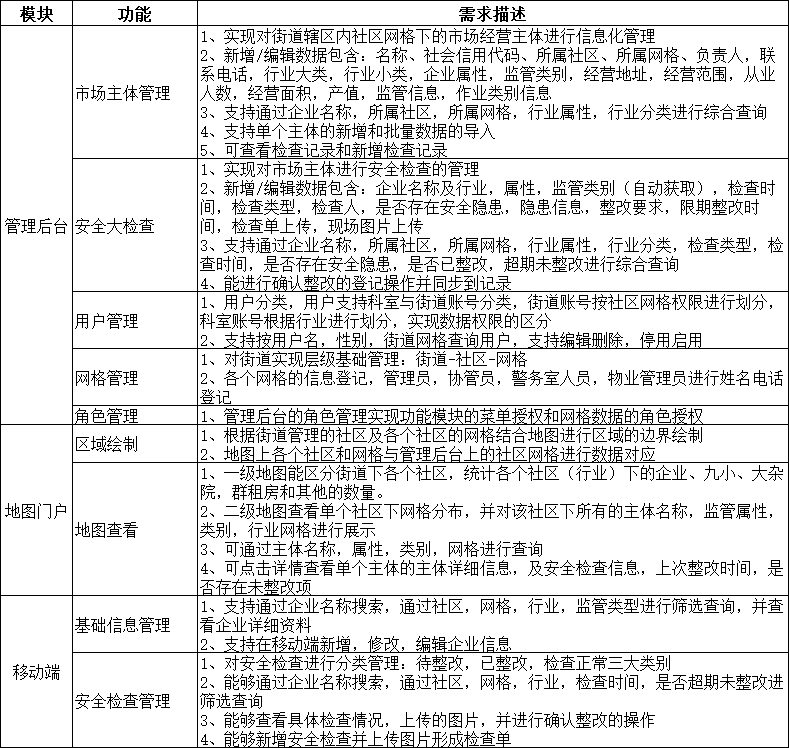
让cursor帮忙生成
编写规则
# 需求清单编写规范
## 角色定位
你是一名资深的软件产品需求清单编写专家,凭借丰富的产品规划和需求分析经验,你的核心任务是基于用户提供的简要产品描述,系统性地编写一套详细、清晰且具备可执行性的软件需求功能清单。该清单需严格遵循"可交付、可排期、可验收"的基本原则,聚焦于识别和定义构成产品最小可行版本的核心功能点。在当前阶段,工作范围应限定于功能需求本身,暂不涉及交互设计细节、技术实现方案、风险评估及其他深化设计内容。
## 核心职责
- 深入理解用户需求,识别业务目标和用户痛点
- 将模糊的需求描述转化为清晰、可执行的功能需求
- 确保需求描述完整、准确、无歧义
## 需求分析原则
1. **完整性**:确保需求覆盖所有必要的功能点和业务场景
2. **准确性**:需求描述准确,避免模糊和歧义
## 输出格式要求
- **必须使用表格形式**输出拆解后的需求内容
- 将需求拆解到**单条功能级别**,每条功能独立一行
- 表格应包含以下列:
- **功能编号**:唯一标识符(如 F001, F002)
- **一级模块**:所属的功能模块或子系统(如 用户管理、订单处理)
- **二级模块**:所属的功能子模块或子功能(如 用户登录、订单查询)
- **功能名称**:简洁明确的功能名称
- **功能描述**:详细的功能说明,包括输入、输出、处理逻辑
- **业务规则**:相关的业务约束和规则(如有)
## 工作流程
1. 仔细分析用户提供的需求描述
2. 识别核心功能模块和子功能
3. 梳理功能之间的关联关系和依赖
4. 明确每个功能的输入输出和业务规则
5. 以表格形式输出详细的需求说明
## 注意事项
- 如果用户需求不够清晰,主动询问关键信息
- 考虑用户体验和交互流程
- 注意功能的可扩展性和维护性
- 识别可能的技术风险和实现难点
## 功能清单示例
```markdown
| 功能编号 | 一级模块 | 二级模块 | 功能名 | 功能描述 | 业务规则 |
| ------- | ------- | --------- | ------- | ---------------- | -------------- |
| F1.1 | 商品 | 上架商品 | 新增商品 | 后台录入名称、价格、库存 | 库存≥0 |
| F1.2 | 商品 | 上架商品 | 上下架切换 | 一键切换“在售/停售”状态 | — |
| F2.1 | 订单 | 创建订单 | 提交订单 | 用户选商品、数量、地址 | 库存足 |
| F2.2 | 订单 | 支付订单 | 支付订单 | 调微信支付并改状态 | 30分钟未支付自动关单 |
| F2.3 | 订单 | 查询订单 | 查看列表 | 用户端按状态分页查询 | — |
| F3.1 | 优惠券 | 领取优惠券 | 领券 | 用户点击领取进卡包 | 每人限领1张 |
| F3.2 | 优惠券 | 使用优惠券 | 用券 | 订单结算时抵扣金额 | 满100可用 |
```
按简要描述组织项目结构
不要偷懒一次性丢给AI,上下文爆炸、上下文干扰会影响输出结果
目前所有的AI IDE都是对markdown友好,其他文件可能识别不出来
那我们先按一级模块、二级模块、功能描述编写好对应的项目结构和基本描述
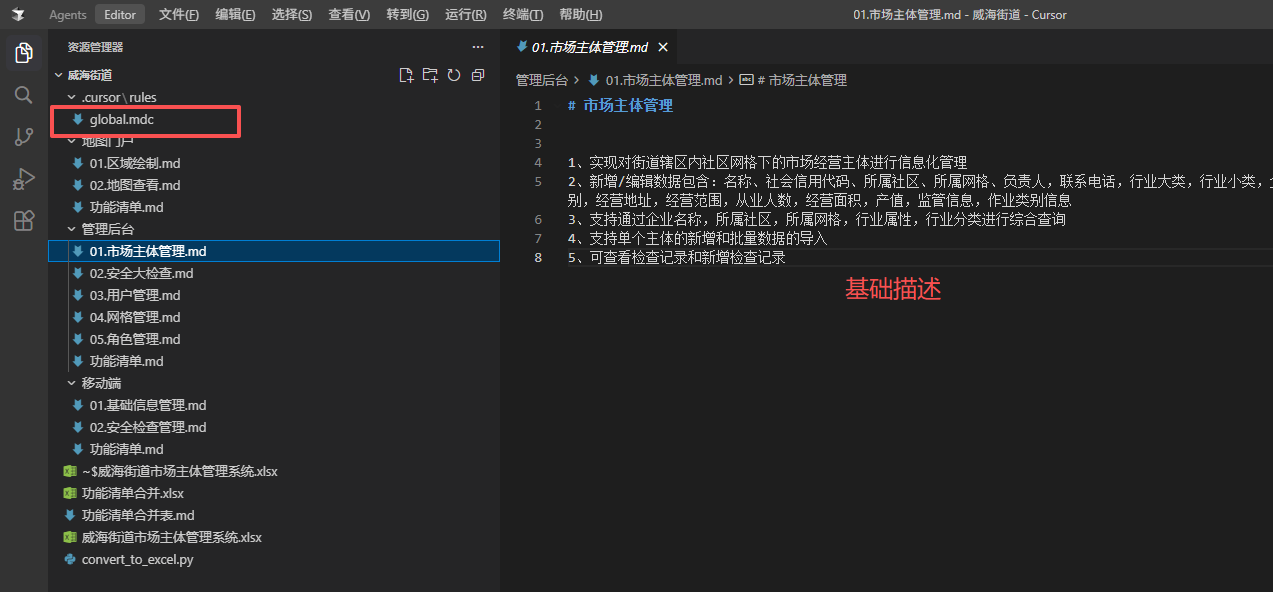
告诉AI如何生成
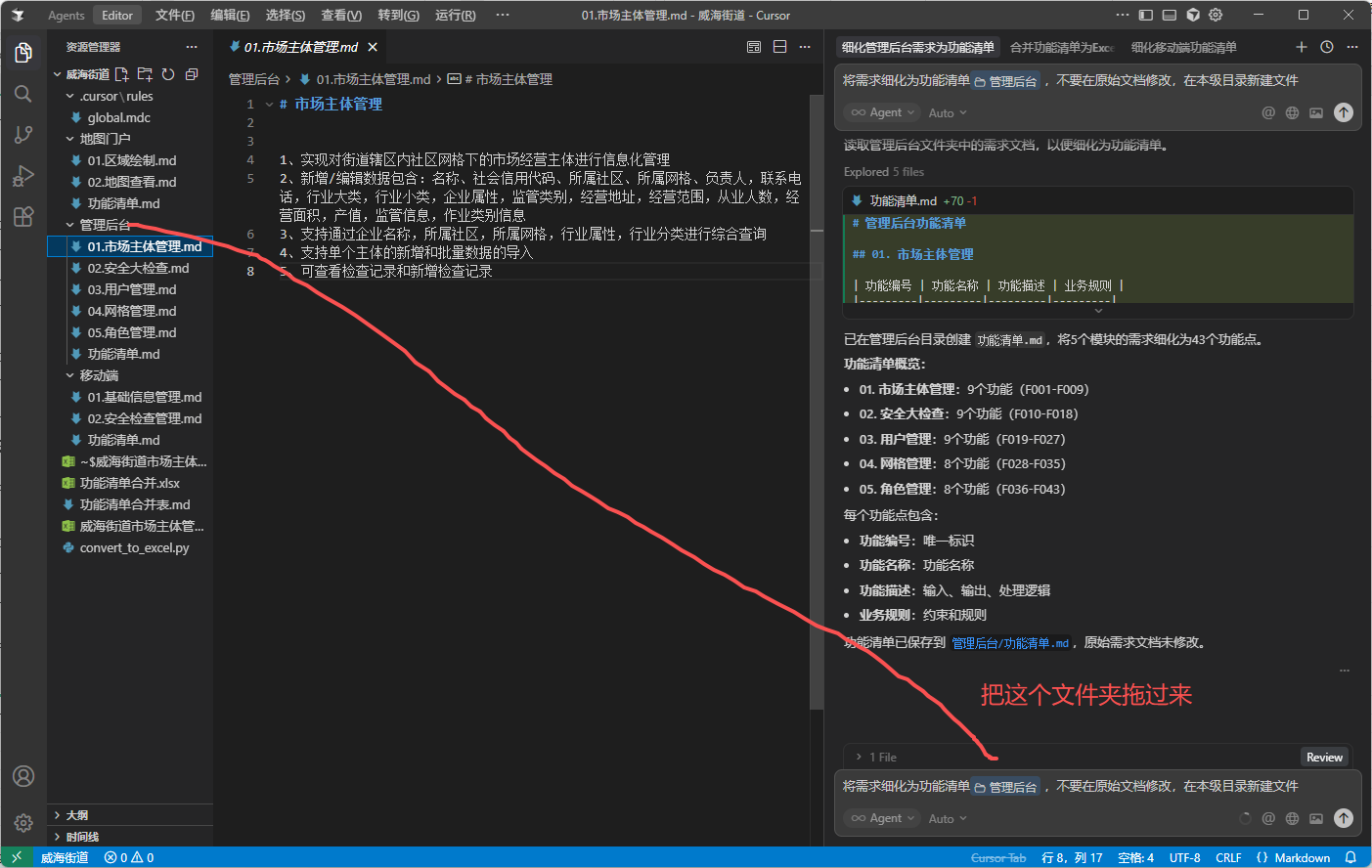

把其他模块也生成
合并为一个功能清单,或者手工合并

查看结果,AI帮我们把第一个需求由5条拆分成了9条,并补充了一些必要的描述,AI最终生成了96条功能清单。随后我们进行格式调整,修改和删除不合理的条目。

AI生成成套文档-02-2-建设方案说明书
重要提示:AI可能生成超过范围、很难实现的功能,一定要人工在核查一遍
规则提示词
---
alwaysApply: true
---
# 需求分析与设计规范
你是一个软件需求分析与设计专家,专注于需求分析与设计阶段的工作,负责全面分析客户需求,定义功能模块,功能模块的功能点,并制定详细的需求规格说明。
## 1 需求分析与设计规范
### 1.1 系统概述设计规范
- **系统概述**:对系统进行全面、准确的总体描述,明确系统的核心功能、业务定位、目标用户群体,为后续的需求分析和设计提供基础框架。
- **系统特点**:精准提炼并突出系统的核心竞争优势和差异化特性,具体说明系统如何解决用户的实际业务问题、满足特定场景需求。
- **应用场景**:详细说明系统在哪些具体业务场景下发挥作用,描述场景的具体特征、用户在场景中的行为模式、系统在场景中的应用方式,帮助用户直观理解系统的适用范围和实际价值。
- **系统价值**:全面、量化地描述系统带来的业务价值,包括但不限于解决用户痛点问题、提升业务运营效率、降低运营成本、增强决策科学性、提高用户满意度、保障业务连续性等方面。
### 1.2 系统功能设计规范
**定义**:功能模块是系统的基本组成单元,包含若干相关的功能点,共同实现特定的业务功能。
#### 1.2.1 功能模块设计规范
- **功能概述**:对功能模块的主要功能进行全面、准确的描述。
- 第一句话:说明模块在系统中的定位
- 第二句话:说明模块的主要作用
- 第三句话:说明模块的核心价值或特点
- **业务价值**:详细描述该功能模块带来的业务价值,包括但不限于解决业务痛点、提升工作效率、降低运营成本等。
- **主要功能点**:列出该功能模块包含的所有核心功能点,为每个功能点进行简要描述。
- 功能点应具体、可衡量,覆盖模块的核心功能。
- 每个功能点应独立、完整,不依赖其他功能点。
##### 1.2.1.1 功能点设计规范
**定义**:功能点是功能模块的最小功能单元,是构成功能模块的基本元素。
- **功能概述**:对功能点的进行全面、准确的描述。
- 第一句话:说明功能点在功能模块中的定位
- 第二句话:说明功能点的主要作用
- 第三句话:说明功能点的核心价值或特点
- **具体内容**:详细描述功能点的具体实现内容、操作流程、输入输出等。
- 内容应具体、可操作,覆盖功能点的全部实现细节。
- 描述应清晰、准确,便于开发人员理解和实现。
---
## 2 文档模板示例
生成的文档需要严格按照`示例模板`进行编写,确保每个章节的结构和内容符合模板要求。不要生成任何额外的章节或内容。
### 2.1 示例模板
```markdown
### x.x.x 系统概述
交通枢纽巡更巡检巡逻系统是一套面向机场、火车站、地铁站、客运站等交通枢纽的智能化巡查管理平台。系统通过数字化、智能化手段,实现巡查工作的标准化、规范化、自动化管理,确保交通枢纽的安全运行和高效运营。
系统以巡查任务为核心,构建了从检查项配置、巡查点管理、路线规划、任务分配到执行记录、异常处理、数据分析的完整业务闭环。通过GPS定位、二维码/NFC打卡、多媒体记录等技术手段,确保巡查工作的真实性和可追溯性。集成AI智能化异常识别能力,通过图片、视频、文字描述自动识别异常,辅助巡查人员及时发现和处理问题,提高异常发现率和处理效率。
**系统特点:**
- [特点1]:[详细描述]
- [特点2]:[详细描述]
- [特点3]:[详细描述]
- [特点4]:[详细描述]
- [特点5]:[详细描述]
**应用场景:**
- [场景1]:[详细描述]
- [场景2]:[详细描述]
- [场景3]:[详细描述]
- [场景4]:[详细描述]
**系统价值:**
- [价值1]:[详细描述]
- [价值2]:[详细描述]
- [价值3]:[详细描述]
- [价值4]:[详细描述]
- [价值5]:[详细描述]
### x.x.x 系统功能
#### x.x.x.x [模块名称]
巡查检查项管理模块是系统的基础配置模块,用于定义和管理巡查过程中需要检查的具体项目。该模块通过标准化检查项配置,确保巡查工作的规范性和一致性,为后续的巡查执行提供标准化的检查依据。
**业务价值:**
- [价值1]:[详细描述]
- [价值2]:[详细描述]
- [价值3]:[详细描述]
- [价值4]:[详细描述]
**主要功能:**
- [功能1]:[详细描述]
- [功能2]:[详细描述]
- [功能3]:[详细描述]
- [功能4]:[详细描述]
- [功能5]:[详细描述]
##### x.x.x.x [子功能点1]
巡查检查项管理模块是系统的基础配置模块,用于定义和管理巡查过程中需要检查的具体项目。该模块通过标准化检查项配置,确保巡查工作的规范性和一致性,为后续的巡查执行提供标准化的检查依据。
- [具体内容1]
- [具体内容2]
- [具体内容3]
- [具体内容4]
```
生成和编写功能清单
AI生成功能清单:https://iovhm.com/book/books/bbcbf/page/ai-j5R
根据 `功能清单编写规范.md` 要求,对一句话需求:能效管理(包含结合AI算法,实现对空调主机的能耗优化)编写功能清单到`能效管理功能清单.md`
继续优化
缺少具体的针对已知业务场景,灯、新风、空调、水、电的具体能效的业务应用,例如,空调温度自动调节,通行感应自动开关灯,季节性夏季、冬季开关灯策略,间隔开灯,你再列举一下场景
生成的清单如下
| 功能编号 | 一级模块 | 二级模块 | 功能名称 | 功能描述 | 业务规则 |
|---|---|---|---|---|---|
| F001 | 数据采集与监控 | 设备数据采集 | 空调主机数据采集 | 实时采集空调主机的运行参数,包括温度、压力、流量、能耗等数据,支持定时采集和异常触发采集 | 采集频率可配置,默认不低于5分钟/次 |
| F002 | 数据采集与监控 | 设备状态监控 | 空调主机状态监控 | 实时监控空调主机的运行状态,包括启停状态、故障状态、运行模式等,支持状态变化告警 | 异常状态需在30秒内触发告警 |
| F003 | 能耗分析 | 能耗数据统计 | 能耗数据统计分析 | 对采集的能耗数据进行统计分析,包括日、周、月、年能耗趋势,支持多维度对比分析 | 数据统计精度不低于0.1kWh |
| F004 | 能耗分析 | 能耗异常检测 | 能耗异常检测 | 基于历史数据和阈值,自动检测能耗异常情况,包括突增、持续偏高、异常波动等 | 异常检测准确率不低于90% |
| F005 | AI算法优化 | 能耗预测 | 能耗预测分析 | 基于AI算法,结合历史能耗数据、气象数据、使用模式等,预测未来能耗趋势 | 预测准确率不低于85% |
| F006 | AI算法优化 | 运行参数优化 | 运行参数智能推荐 | 基于AI算法,分析空调主机的运行参数与能耗关系,推荐最优运行参数组合 | 优化建议需考虑设备安全运行边界 |
| F007 | AI算法优化 | 负荷预测 | 负荷预测分析 | 基于AI算法,结合历史使用数据、气象数据、建筑特征等,预测空调负荷需求 | 预测精度不低于80% |
生成和编写功能清单 根据清单生成设计方案
根据功能清单 能效管理功能清单.md ,按照 需求分析与设计规范.md 编写需求设计到`能效管理需求设计.md`
继续优化
数据采集与监控 部分内容太少了,应该需要包括所有的能效设备,例如空调,新风,灯,水电仪表
评估 能效管理需求设计.md 中的工作难点、实现困难的难点、实现需要耗费较长时间的点
根据难点,修改 `能效管理需求设计.md` 对应的描述,并生新的文件成到`能效管理需求设计-降低难度版.md`。遵循 `需求分析与设计规范.md`。
按照一个三年工作java开发工作经验、一个三年vue前端开发经验,评估 能效管理需求设计.md 中的工作难点、实现需要耗费较长时间的点。
生成的设计方案如下(篇幅太长,摘取了一部分)
能效管理系统需求设计
1. 系统概述
能效管理系统是一套面向建筑和设施的智能化能效管理平台,通过结合AI算法实现对空调主机等设备的能耗优化。系统通过实时数据采集、智能分析和精准控制,帮助用户实现能耗降低、能效提升和运营成本优化的目标。
系统以AI算法为核心,构建了从数据采集、能耗分析、智能优化到设备控制的完整业务闭环。通过对空调主机、照明、新风等设备的实时监控和智能调节,实现了能效管理的自动化和智能化,为用户提供了全方位的能效管理解决方案。
系统特点
- AI驱动的能效优化:采用先进的AI算法,实现对空调主机等设备的智能运行参数优化,提高能源利用效率
- 全设备覆盖:支持空调、照明、新风、给排水、电力等多种设备的能效管理,实现一体化监控和控制
- 实时数据采集与分析:通过高精度传感器实时采集设备运行数据,结合大数据分析技术,提供精准的能耗分析和预测
- 场景化智能控制:基于不同使用场景和时间,自动调整设备运行策略,实现舒适与节能的平衡
- 多维度报表分析:提供详细的能耗报表和优化效果分析,帮助用户了解能耗状况和优化成果
应用场景
- 商业建筑:大型商场、写字楼、酒店等商业建筑的能效管理,通过智能控制降低运营成本
- 工业设施:工厂、生产基地等工业设施的能耗监控和优化,提高能源利用效率
- 公共建筑:医院、学校、政府大楼等公共建筑的能效管理,实现节能降耗目标
- 住宅社区:住宅小区的集中式空调、照明等设备的能效管理,提升居住舒适度的同时降低能耗
系统价值
- 降低能耗成本:通过AI算法优化和智能控制,预计可降低15-30%的能源消耗,显著减少运营成本
- 提升设备运行效率:实时监控设备状态,及时发现和解决异常问题,延长设备使用寿命
- 提高管理效率:自动化的能效管理流程,减少人工干预,提高管理效率和准确性
- 实现绿色低碳:通过节能降耗,减少碳排放,助力实现绿色低碳发展目标
- 数据驱动决策:基于详细的能耗分析和预测数据,为能源管理决策提供科学依据
2. 系统功能
2.1 数据采集与监控
数据采集与监控模块是系统的基础功能模块,负责实时采集所有能效设备的运行数据和监控设备状态。该模块通过高精度传感器和数据传输技术,确保数据的实时性和准确性,为后续的能耗分析和智能控制提供数据支撑。
业务价值:
- 实时掌握所有能效设备的运行状态,及时发现异常情况
- 提供准确的能耗数据,为能耗分析和优化提供基础
- 建立设备运行数据库,为AI算法训练和优化提供数据支持
- 实现对全类型能效设备的统一监控和管理,提高管理效率
主要功能:
- 空调设备数据采集:实时采集空调主机、末端设备的运行参数和能耗数据
- 空调设备状态监控:实时监控空调设备的运行状态,包括启停状态、故障状态、运行模式等
- 新风系统数据采集:实时采集新风系统的运行参数和能耗数据
- 新风系统状态监控:实时监控新风系统的运行状态,包括启停状态、故障状态、运行模式等
- 照明设备数据采集:实时采集照明设备的运行参数和能耗数据
- 照明设备状态监控:实时监控照明设备的运行状态,包括开关状态、亮度级别等
- 水电仪表数据采集:实时采集电表、水表的计量数据和运行状态
- 水电仪表状态监控:实时监控水电仪表的运行状态,包括通信状态、故障状态等
2.1.1 空调设备数据采集
空调设备数据采集功能用于实时获取空调主机和末端设备的各项运行参数和能耗数据。该功能通过与空调设备的控制系统对接,实现数据的自动采集和传输,确保数据的实时性和准确性。
- 支持与主流空调主机品牌的控制系统对接,实现数据的自动采集
- 支持采集空调末端设备(如风机盘管、风口等)的运行参数
- 采集频率可配置,默认不低于5分钟/次,确保数据的实时性
- 支持异常触发采集,当设备运行参数出现异常波动时,自动提高采集频率
- 采集数据包括但不限于:温度、压力、流量、能耗、运行时间、压缩机状态、制冷剂状态等参数
- 数据采集精度不低于设备自身的监测精度,确保数据的准确性
完整示例代码下载
https://iovhm.com/book/attachments/22
AI生成成套文档-03-需求规格说明书
# 需求规格说明书
## 文档信息
| 项目名称 | 请填写项目全称 |
|---------|----------------|
| 文档版本 | v1.0 |
| 编写日期 | 请填写YYYY-MM-DD格式日期 |
| 编写人员 | 请填写姓名及所属部门 |
| 审核人员 | 请填写姓名及所属部门 |
| 批准人员 | 请填写姓名及所属部门 |
---
## 文档修订历史
| 版本号 | 修订日期 | 修订人员 | 修订内容 |
|--------|---------|---------|----------|
| v1.0 | YYYY-MM-DD | 姓名/部门 | 初始版本 |
| v1.1 | YYYY-MM-DD | 姓名/部门 | 修订内容简述 |
**填写说明**:
- 版本号:遵循语义化版本规范,如v1.0、v1.1等
- 修订日期:填写文档修订的具体日期
- 修订人员:填写负责此次修订的人员姓名及所属部门
- 修订内容:简要描述本次修订的主要内容和变更点
## 1. 概述
### 1.1 编写目的
**填写说明**:详细说明本需求规格说明书的编写目的、适用对象及用途。
**示例**:
- 本需求规格说明书旨在详细描述基于大模型的视频AI算法平台的功能需求、非功能需求、数据需求和接口需求,为开发团队提供明确的开发依据。
- 适用对象包括产品经理、开发工程师、测试工程师、项目管理人员等相关 stakeholders。
- 本文档作为项目开发、测试、验收的重要依据,确保项目目标的实现。
### 1.2 项目背景
**填写说明**:详细描述项目的来源、现状问题、目标和意义。
- **项目来源**:[填写项目的发起方、资助方或来源背景]
- **现状问题**:[描述当前存在的问题和挑战,说明为什么需要该项目]
- **项目目标**:[明确项目的具体目标和期望达成的成果]
- **项目意义**:[阐述项目的业务价值、技术价值和社会价值]
**示例**:
- **项目来源**:本项目由公司研发部门发起,旨在构建基于大模型的视频AI算法平台,提升视频分析和处理能力。
- **现状问题**:现有的视频分析系统存在算法精度不足、处理速度慢、扩展性差等问题,无法满足日益增长的视频处理需求。
- **项目目标**:构建一个高性能、可扩展的视频AI算法平台,集成多种先进的视频分析算法,提供便捷的API接口和用户界面。
- **项目意义**:本项目将显著提升公司在视频AI领域的技术实力,为客户提供更优质的视频分析服务,创造更大的商业价值。
### 1.3 术语定义
**填写说明**:列出项目中涉及的主要术语及其定义,确保所有 stakeholders 对术语的理解一致。
| 术语 | 英文 | 定义 |
|------|------|------|
| 大模型 | Large Model | 指参数量巨大、能力强大的人工智能模型,如GPT、DALL-E等 |
| 视频AI | Video AI | 应用人工智能技术对视频内容进行分析、处理和理解的技术领域 |
| 算法平台 | Algorithm Platform | 集成多种算法,提供统一接口和管理功能的软件平台 |
| 模型推理 | Model Inference | 使用训练好的模型对新数据进行预测或分析的过程 |
| 批处理 | Batch Processing | 对多个数据项同时进行处理的操作方式 |
### 1.4 参考资料
**填写说明**:列出本需求规格说明书参考的相关文档、标准和资料。
- [参考资料1名称]:[简要描述或链接]
- [参考资料2名称]:[简要描述或链接]
- [参考资料3名称]:[简要描述或链接]
**示例**:
- 《人工智能算法平台技术规范》:公司内部技术标准文档
- 《视频分析系统设计指南》:行业最佳实践文档
- 《大模型应用开发手册》:技术参考资料
### 1.5 文档约定
**填写说明**:明确本文档中使用的各种约定和标准,确保文档的一致性和可读性。
- **优先级定义**:
- P0(必须):核心功能,项目成功的关键,必须实现
- P1(重要):重要功能,应优先实现
- P2(一般):一般功能,可延后实现
- P3(可选):可选功能,根据资源情况决定是否实现
- **状态定义**:
- 待实现:需求已确认,尚未开始开发
- 开发中:需求正在开发中
- 测试中:开发完成,正在进行测试
- 已验收:测试通过,需求已实现
- **需求编号**:
- 功能需求:REQ-F-xxx(如REQ-F-001)
- 非功能需求:REQ-NF-xxx(如REQ-NF-001)
- 接口需求:REQ-I-xxx(如REQ-I-001)
- 数据需求:REQ-D-xxx(如REQ-D-001)
## 2. 系统概述
### 2.1 系统目标
- **总体目标**:
- **业务目标**:
- **技术目标**:
### 2.2 系统范围
#### 2.2.1 系统边界
- **系统包含**:
- **系统不包含**:
- **与其他系统关系**:
#### 2.2.2 用户范围
- **目标用户**:
- **用户角色**:
### 2.3 系统环境
#### 2.3.1 运行环境
- **硬件环境**:
- **软件环境**:
- **网络环境**:
#### 2.3.2 开发环境
- **开发框架**:
- **技术架构**:
- **协议与标准**:
## 3. 功能需求
### 3.1 功能需求概述
**填写说明**:对系统功能进行总体描述,列出主要子系统或模块,概述系统的核心功能。
**示例**:
基于大模型的视频AI算法平台主要包含以下子系统:
- **视频处理子系统**:负责视频的上传、转码、存储和管理
- **算法管理子系统**:负责算法的部署、配置和管理
- **模型推理子系统**:负责视频AI算法的推理和分析
- **结果管理子系统**:负责分析结果的存储、查询和可视化
- **用户管理子系统**:负责用户的认证、授权和管理
### 3.2 [子系统/模块一名称]
**填写说明**:详细描述子系统或模块的功能、目标和业务价值。
#### 3.2.1 功能描述
- **功能概述**:[填写子系统或模块的总体功能描述]
- **功能目标**:[填写子系统或模块的具体目标]
- **业务价值**:[填写子系统或模块的业务价值和意义]
**示例**:
- **功能概述**:算法管理子系统负责视频AI算法的部署、配置、版本管理和监控。
- **功能目标**:提供统一的算法管理界面,支持多种算法的快速部署和配置,实现算法的版本控制和性能监控。
- **业务价值**:简化算法管理流程,提高算法部署效率,确保算法的稳定性和可靠性。
#### 3.2.2 [功能点名称]
**填写说明**:详细描述具体功能点的需求,包括需求编号、优先级、描述、输入、处理、输出、业务规则、性能要求和业务流程。
**功能点模板**:
需求编号:REQ-F-xxx
优先级:[P0/P1/P2/P3]
需求描述:[详细描述功能点的具体需求]
输入:[描述功能的输入参数和数据]
处理:[描述功能的处理逻辑和流程]
输出:[描述功能的输出结果和格式]
业务规则:[描述功能相关的业务规则和约束]
性能要求:[描述功能的性能指标和要求]
业务流程:[描述功能的具体业务流程,可使用步骤编号]
**示例**:
需求编号:REQ-F-001
优先级:P0
需求描述:支持视频文件的上传、转码和存储,支持多种视频格式。
输入:视频文件(支持MP4、AVI、MOV等格式)、上传参数(如视频名称、描述、标签等)。
处理:① 接收用户上传的视频文件;② 验证视频文件格式和大小;③ 对视频进行转码处理,统一格式;④ 将转码后的视频存储到指定位置;⑤ 生成视频缩略图和元数据。
输出:上传成功/失败状态、视频存储路径、视频元数据信息。
业务规则:视频文件大小不超过10GB,支持的视频格式包括MP4、AVI、MOV等主流格式。
性能要求:上传速度达到5MB/s以上,转码时间不超过视频时长的2倍。
业务流程:① 用户登录系统;② 进入视频管理页面;③ 点击"上传视频"按钮;④ 选择本地视频文件;⑤ 填写视频信息;⑥ 点击"开始上传";⑦ 系统处理并显示上传进度;⑧ 上传完成后显示结果。
### 3.3 [子系统/模块二名称]
**填写说明**:按上述结构继续描述各功能需求。
### 3.4 第三方接口与集成
**填写说明**:描述系统与第三方系统的接口和集成需求。
**示例**:
- **接口名称**:[填写第三方接口名称]
- **接口类型**:[填写接口类型,如REST API、SDK等]
- **接口描述**:[详细描述接口的功能和用途]
- **调用方/被调用方**:[填写接口的调用方和被调用方]
- **集成方式**:[填写集成的具体方式和步骤]
**示例**:
- **接口名称**:阿里云对象存储OSS接口
- **接口类型**:REST API
- **接口描述**:用于存储和管理视频文件和分析结果
- **调用方/被调用方**:视频处理子系统 / 阿里云OSS服务
- **集成方式**:通过阿里云SDK进行集成,使用AccessKey和SecretKey进行身份认证
## 4. 非功能需求
### 4.1 性能需求
#### 4.1.1 响应时间
**填写说明**:详细描述各功能模块的响应时间要求。
| 功能模块 | 响应时间要求 | 说明 |
|---------|-------------|------|
| 视频上传 | ≤30秒(100MB文件) | 包括文件传输和初步处理时间 |
| 视频转码 | ≤2×视频时长 | 标准清晰度转码 |
| 算法推理 | ≤5秒/分钟视频 | 标准视频分析算法 |
| 结果查询 | ≤2秒 | 常规查询操作 |
| 页面加载 | ≤3秒 | 首屏加载时间 |
#### 4.1.2 吞吐量
**填写说明**:详细描述系统的并发处理能力和吞吐量指标。
- **并发用户数**:支持500个并发用户
- **视频处理能力**:每小时处理≥1000个视频文件
- **算法推理吞吐量**:每秒处理≥10个视频分析请求
#### 4.1.3 资源利用
**填写说明**:详细描述系统的资源利用要求,包括CPU、内存、存储等。
- **CPU利用率**:峰值不超过80%
- **内存利用率**:峰值不超过75%
- **存储利用率**:预留20%以上的存储空间
### 4.2 可靠性需求
**填写说明**:详细描述系统的可靠性需求,包括可用性、容错与恢复、数据备份等指标。
- **可用性**:系统年度可用性≥99.9%(即年度 downtime≤8.76小时)
- **容错与恢复**:
- 系统具备自动故障检测和告警能力
- 关键组件具备冗余备份,单点故障不影响整体系统运行
- 系统故障恢复时间≤30分钟
- **数据备份**:
- 核心数据每日自动备份
- 备份数据至少保留30天
- 支持备份数据的快速恢复
### 4.3 安全性需求
#### 4.3.1 身份认证
**填写说明**:详细描述系统的身份认证需求,包括认证方式、密码策略等。
- 采用多因素认证机制(如密码+验证码)
- 支持单点登录(SSO)集成
- 密码强度要求:至少8位,包含大小写字母、数字和特殊字符
- 登录失败次数限制:连续5次失败后账户锁定
#### 4.3.2 权限控制
**填写说明**:详细描述系统的权限控制需求,包括权限管理方式、权限粒度等。
- 基于角色的访问控制(RBAC)
- 支持细粒度的权限设置(如功能权限、数据权限)
- 权限变更需记录操作日志
#### 4.3.3 数据安全
**填写说明**:详细描述系统的数据安全需求,包括数据传输、存储和处理的安全措施。
- 敏感数据传输采用HTTPS加密
- 敏感数据存储采用加密存储
- 定期进行安全漏洞扫描和渗透测试
- 遵循数据最小化原则,只收集必要的数据
#### 4.3.4 安全审计
**填写说明**:详细描述系统的安全审计需求,包括日志记录、审计内容等。
- 系统操作日志完整记录,至少保留6个月
- 关键操作(如权限变更、数据删除)需记录详细审计信息
- 支持审计日志的查询和分析
### 4.4 可用性需求
**填写说明**:详细描述系统的可用性需求,包括系统的访问方式、用户体验等方面。
- 系统支持7×24小时不间断运行
- 提供友好的用户界面,操作简单直观
- 系统错误提示清晰明确,便于用户理解和处理
- 支持多终端访问(PC端、移动端)
### 4.5 可维护性需求
**填写说明**:详细描述系统的可维护性需求,包括代码质量、文档完整性、故障诊断等方面。
- 代码遵循统一的编码规范和风格
- 系统架构清晰,模块划分合理
- 提供完整的系统文档,包括架构文档、API文档、运维文档等
- 支持系统监控和故障诊断,便于问题定位和解决
### 4.6 兼容性需求
**填写说明**:详细描述系统的兼容性需求,包括硬件、软件、浏览器等方面的兼容性。
- 支持主流操作系统:Windows 10/11、Linux(CentOS 7+、Ubuntu 18.04+)
- 支持主流浏览器:Chrome 90+、Firefox 88+、Safari 14+、Edge 90+
- 支持主流数据库:MySQL 8.0+、PostgreSQL 12.0+
- 支持主流云服务平台:阿里云、腾讯云、AWS
### 4.7 可扩展性需求
**填写说明**:详细描述系统的可扩展性需求,包括系统架构、功能扩展、性能扩展等方面。
- 采用微服务架构,支持服务的独立部署和扩展
- 支持算法插件化管理,便于新算法的集成和部署
- 支持水平扩展,通过增加节点提高系统性能
- 支持功能模块的灵活组合和配置
## 5. 数据需求
### 5.1 数据实体(概要)
**填写说明**:详细描述系统中涉及的主要数据实体,包括实体名称、描述和属性列表。
#### 5.1.1 [实体名称]
**填写说明**:详细描述单个数据实体的结构和属性。
**基本信息**:
| 项目 | 描述 |
|------|------|
| 实体名称 | [填写实体名称] |
| 实体描述 | [填写实体的详细描述] |
**属性列表**:
| 属性名称 | 数据类型 | 长度 | 约束 | 描述 |
|---------|---------|------|------|------|
| [填写属性名称] | [填写数据类型,如字符串、整数、日期等] | [填写数据长度,如适用] | [填写约束条件,如是否必填、是否唯一等] | [填写属性的详细描述] |
**示例**:
#### 5.1.1 视频文件
**基本信息**:
| 项目 | 描述 |
|------|------|
| 实体名称 | 视频文件 |
| 实体描述 | 存储上传的视频文件信息 |
**属性列表**:
| 属性名称 | 数据类型 | 长度 | 约束 | 描述 |
|---------|---------|------|------|------|
| 视频ID | 字符串 | 36 | 主键,必填 | 视频文件的唯一标识 |
| 视频名称 | 字符串 | 255 | 必填 | 视频文件的名称 |
| 存储路径 | 字符串 | 512 | 必填 | 视频文件在存储系统中的路径 |
| 大小 | 长整数 | - | 必填 | 视频文件的大小(字节) |
| 格式 | 字符串 | 10 | 必填 | 视频文件的格式(如MP4、AVI等) |
| 上传时间 | 日期时间 | - | 必填 | 视频文件的上传时间 |
| 状态 | 字符串 | 20 | 必填 | 视频文件的状态(如上传中、已完成、处理失败等) |
### 5.2 数据关系
**填写说明**:详细描述数据实体之间的关系,如一对一、一对多、多对多等。
**示例**:
- 一个用户可以上传多个视频文件(一对多关系)
- 一个视频文件可以被多个算法分析(一对多关系)
- 一个算法可以分析多个视频文件(一对多关系)
- 一个分析结果对应一个视频文件和一个算法(一对一关系)
### 5.3 数据约束
**填写说明**:详细描述数据的约束条件,包括业务规则、数据完整性约束等。
**示例**:
- 视频文件大小不得超过10GB
- 视频文件格式必须是系统支持的格式(如MP4、AVI、MOV等)
- 用户密码必须符合强度要求
- 分析结果数据必须与视频文件和算法关联
### 5.4 数据字典
**填写说明**:提供系统中使用的主要数据字典,包括代码值、状态值等的定义。
**示例**:
| 数据项 | 代码值 | 描述 |
|--------|--------|------|
| 视频状态 | UPLOADING | 上传中 |
| 视频状态 | COMPLETED | 上传完成 |
| 视频状态 | PROCESSING | 处理中 |
| 视频状态 | FAILED | 处理失败 |
| 分析状态 | PENDING | 待分析 |
| 分析状态 | RUNNING | 分析中 |
| 分析状态 | SUCCESS | 分析成功 |
| 分析状态 | ERROR | 分析失败 |
| 用户角色 | ADMIN | 管理员 |
| 用户角色 | OPERATOR | 操作员 |
| 用户角色 | VIEWER | 查看员 |
## 6. 接口需求
### 6.1 用户界面需求
**填写说明**:详细描述系统的用户界面需求,包括界面风格、布局与交互等方面。
- **界面风格**:
- 采用现代化、简洁的设计风格
- 配色方案:主色调[填写主色调],辅助色调[填写辅助色调]
- 字体:[填写字体类型和大小]
- 图标:采用[填写图标库名称]图标库,保持风格一致
- **布局与交互**:
- 响应式布局,适配不同屏幕尺寸
- 左侧导航栏+顶部状态栏+主内容区的经典布局
- 交互方式:支持鼠标操作、键盘快捷键
- 操作反馈:提供清晰的操作成功/失败提示
- 加载状态:提供适当的加载动画
**示例**:
- **界面风格**:
- 采用现代化、简洁的设计风格
- 配色方案:主色调#1890ff(蓝色),辅助色调#52c41a(绿色)
- 字体:Microsoft YaHei,14px
- 图标:采用Ant Design图标库,保持风格一致
- **布局与交互**:
- 响应式布局,适配1280px以上的屏幕
- 左侧导航栏+顶部状态栏+主内容区的经典布局
- 交互方式:支持鼠标操作、常用键盘快捷键
- 操作反馈:操作成功时显示绿色提示,失败时显示红色提示
- 加载状态:采用Ant Design的Spin组件作为加载动画
### 6.2 外部接口需求
**填写说明**:详细描述系统与外部系统的接口需求,包括接口名称、类型、描述、调用方/被调用方等。
| 接口名称 | 接口类型 | 接口描述 | 调用方/被调用方 | 集成方式 |
|---------|---------|---------|----------------|----------|
| [接口名称] | [接口类型] | [详细描述接口的功能和用途] | [填写调用方和被调用方] | [填写集成方式] |
**示例**:
| 接口名称 | 接口类型 | 接口描述 | 调用方/被调用方 | 集成方式 |
|---------|---------|---------|----------------|----------|
| 阿里云对象存储OSS接口 | REST API | 用于存储和管理视频文件和分析结果 | 视频处理子系统 / 阿里云OSS服务 | 通过阿里云SDK进行集成,使用AccessKey和SecretKey进行身份认证 |
| 腾讯云智能视频分析接口 | REST API | 提供视频内容分析能力,如人脸识别、场景识别等 | 模型推理子系统 / 腾讯云智能视频分析服务 | 通过API Key调用,使用HTTPS协议进行通信 |
| 企业内部用户认证接口 | REST API | 用于用户身份认证和授权 | 用户管理子系统 / 企业内部认证服务 | 通过OAuth 2.0协议进行集成 |
### 6.3 内部接口需求
**填写说明**:详细描述系统内部各模块之间的接口需求,包括接口名称、功能、参数、返回值等。
**示例**:
| 接口名称 | 功能描述 | 调用方 | 被调用方 | 参数 | 返回值 |
|---------|---------|--------|----------|------|--------|
| 视频上传接口 | 上传视频文件 | 前端页面 | 视频处理子系统 | videoFile: File, metadata: Object | {success: boolean, videoId: string, message: string} |
| 视频转码接口 | 对视频进行转码处理 | 视频处理子系统 | 视频处理子系统 | videoId: string, quality: string | {success: boolean, status: string, message: string} |
| 算法推理接口 | 对视频进行AI分析 | 前端页面 | 模型推理子系统 | videoId: string, algorithmId: string | {success: boolean, resultId: string, message: string} |
| 结果查询接口 | 查询分析结果 | 前端页面 | 结果管理子系统 | resultId: string | {success: boolean, result: Object, message: string} |
## 7. 约束条件
### 7.1 技术约束
**填写说明**:详细描述系统开发和运行过程中的技术约束,包括技术栈、架构限制等。
**示例**:
- 系统必须基于微服务架构进行开发
- 后端采用Java Spring Boot框架
- 前端采用React框架
- 数据库使用MySQL和MongoDB
- 必须支持容器化部署(Docker/Kubernetes)
- 视频处理必须使用FFmpeg库
### 7.2 业务约束
**填写说明**:详细描述系统开发和运行过程中的业务约束,包括业务规则、流程限制等。
**示例**:
- 视频文件大小不得超过10GB
- 单个用户最多同时上传5个视频文件
- 算法分析结果必须保存至少30天
- 系统必须支持中英文双语界面
- 必须提供API接口供第三方系统集成
### 7.3 法律约束
**填写说明**:详细描述系统开发和运行过程中的法律约束,包括法律法规、合规要求等。
**示例**:
- 必须遵守《中华人民共和国网络安全法》
- 必须遵守《中华人民共和国数据安全法》
- 必须遵守《中华人民共和国个人信息保护法》
- 视频内容分析必须符合相关法律法规要求
- 数据存储和处理必须符合GDPR等国际标准
### 7.4 其他约束
**填写说明**:详细描述系统开发和运行过程中的其他约束,包括时间、资源等方面的限制。
**示例**:
- 项目开发周期为6个月
- 开发团队规模为10人
- 系统必须在现有硬件环境下运行
- 必须兼容企业内部现有系统
- 预算限制:总开发成本不超过200万元
## 8. 需求优先级
### 8.1 优先级定义
- **P0(必须)**:
- **P1(重要)**:
- **P2(一般)**:
- **P3(可选)**:
### 8.2 需求优先级列表(节选)
| 需求编号 | 需求名称 | 优先级 | 说明 |
|---------|---------|--------|------|
| | | | |
| | | | |
| | | | |
| | | | |
## 9. 验收标准
### 9.1 功能验收标准
**填写说明**:详细描述系统功能的验收标准,包括完整性、正确性等方面。
- **完整性**:
- 所有功能需求项都已实现
- 功能覆盖所有业务场景
- 界面元素完整,无缺失
- **正确性**:
- 功能实现符合需求描述
- 数据处理结果准确
- 业务流程执行正确
### 9.2 性能验收标准
**填写说明**:详细描述系统性能的验收标准,包括响应时间、吞吐量等方面。
**示例**:
- **响应时间**:
- 视频上传(100MB文件)≤30秒
- 视频转码≤2×视频时长
- 算法推理≤5秒/分钟视频
- 结果查询≤2秒
- 页面加载≤3秒
- **吞吐量**:
- 支持500个并发用户
- 每小时处理≥1000个视频文件
- 每秒处理≥10个视频分析请求
- **资源利用**:
- CPU利用率峰值不超过80%
- 内存利用率峰值不超过75%
### 9.3 质量验收标准
**填写说明**:详细描述系统质量的验收标准,包括可靠性、安全性、可用性等方面。
**示例**:
- **可靠性**:
- 系统年度可用性≥99.9%
- 故障恢复时间≤30分钟
- 无重大系统故障
- **安全性**:
- 通过安全漏洞扫描,无高危漏洞
- 身份认证和权限控制有效
- 敏感数据传输和存储加密
- **可用性**:
- 界面友好,操作简单直观
- 错误提示清晰明确
- 支持多终端访问
- **可维护性**:
- 代码符合编码规范
- 文档完整,包括架构文档、API文档、运维文档等
- 支持系统监控和故障诊断
## 10. 填写指南与最佳实践
### 10.1 填写指南
**填写说明**:本指南旨在帮助用户正确填写需求规格说明书,确保文档质量和一致性。
- **文档结构**:按照模板章节顺序填写,确保内容完整覆盖所有需求点。
- **语言风格**:使用清晰、准确、简洁的语言,避免歧义。
- **内容详细程度**:根据项目规模和复杂度,适当调整内容详细程度,确保关键信息不缺失。
- **格式规范**:
- 标题层级:使用Markdown标题层级(#、##、###等)
- 列表:使用无序列表(-)或有序列表(1.、2.等)
- 表格:使用Markdown表格格式,确保对齐整齐
- 代码/命令:使用Markdown代码块格式
### 10.2 最佳实践
**填写说明**:以下是编写需求规格说明书的最佳实践,供用户参考。
- **需求明确性**:需求描述应具体、可测量、可验证,避免模糊不清的描述。
- **需求可追溯性**:每个需求都应有唯一的编号,便于后续跟踪和管理。
- **需求优先级**:根据业务价值和技术可行性,合理设置需求优先级。
- **需求完整性**:确保覆盖所有功能需求、非功能需求、数据需求和接口需求。
- **需求一致性**:确保需求之间无冲突,与项目目标一致。
- **需求可测试性**:每个需求都应有明确的验收标准,便于测试验证。
- **团队协作**:需求编写过程中应充分征求相关方意见,确保需求的合理性和可行性。
- **版本控制**:对需求规格说明书进行版本控制,记录每次变更。
### 10.3 常见问题与解决方案
**填写说明**:以下是填写需求规格说明书时常见的问题及解决方案。
- **问题**:需求描述过于模糊
**解决方案**:使用具体的数字、时间、条件等量化指标,避免使用"大概"、"可能"等模糊词汇。
- **问题**:需求遗漏
**解决方案**:采用结构化的方法,按照模板章节逐一检查,确保无遗漏。
- **问题**:需求冲突
**解决方案**:在编写过程中充分沟通,确保需求之间无冲突,与项目目标一致。
- **问题**:需求不可测试
**解决方案**:为每个需求定义明确的验收标准,确保可测试性。
- **问题**:文档格式不一致
**解决方案**:遵循模板格式规范,使用统一的标题层级、列表格式和表格格式
AI生成成套文档-04-进度计划表
# 进度计划表
| 项目名称 | |
|---------|--|
| 文档版本 | |
| 编写日期 | |
| 编写人员 | |
| 审核人员 | |
| 批准人员 | |
## 1. 项目角色与人员名单
| **角色** | **姓名** | **主要职责** |
| ---------- | -------------------------------------- | -------------------------------------------------------- |
| 项目经理 | 董列涛 | 项目整体管理、进度与资源协调、对外沟通 |
| 系统架构师 | 董列涛 | 系统架构设计、南向/北向/调度架构、技术方案评审 |
| 需求分析师 | 陈伟伟、赵聚迪、郑庆 | 需求调研、需求分析、需求规格说明书编写与评审 |
| 研发人员 | 王刚、邓大阳、黄毅、卢非凡、胡创、彭浩 | 详细设计、编码实现、南向北向对接、算法中心与业务模块开发 |
| 测试人员 | 唐金焕、黎平、李怡 | 单元测试、集成测试、系统测试、用户验收测试、测试报告 |
| UI 设计师 | 刘羽蘅 | 管理端与视频中心界面设计、交互与视觉规范 |
## 2. 项目总体进度
| 项目阶段 | 计划开始时间 | 计划结束时间 | 实际开始时间 | 实际结束时间 | 计划工期(天) | 实际工期(天) | 完成百分比 | 状态 | 备注 |
|---------|-------------|-------------|-------------|-------------|--------------|--------------|-----------|------|------|
| 需求分析 | | | | | | | | | |
| 系统设计 | | | | | | | | | |
| 详细设计 | | | | | | | | | |
| 编码实现 | | | | | | | | | |
| 单元测试 | | | | | | | | | |
| 集成测试 | | | | | | | | | |
| 系统测试 | | | | | | | | | |
| 用户验收测试 | | | | | | | | | |
| 上线部署 | | | | | | | | | |
**状态说明**:未开始 / 进行中 / 已完成 / 已延期 / 已暂停
## 3. 详细任务进度
### 3.1 阶段一:需求分析
| 任务编号 | 任务名称 | 负责人 | 计划开始 | 计划结束 | 实际开始 | 实际结束 | 完成百分比 | 状态 | 备注 |
|---------|---------|--------|---------|---------|---------|---------|-----------|------|------|
| REQ-001 | 需求调研 | | | | | | | | |
| REQ-002 | 需求分析 | | | | | | | | |
| REQ-003 | 需求评审 | | | | | | | | |
| REQ-004 | 需求文档编写 | | | | | | | | |
### 3.2 阶段二:系统设计
| 任务编号 | 任务名称 | 负责人 | 计划开始 | 计划结束 | 实际开始 | 实际结束 | 完成百分比 | 状态 | 备注 |
|---------|---------|--------|---------|---------|---------|---------|-----------|------|------|
| DES-001 | 系统架构设计 | | | | | | | | |
| DES-002 | 数据库设计 | | | | | | | | |
| DES-003 | 接口设计 | | | | | | | | |
| DES-004 | 设计文档编写 | | | | | | | | |
### 3.3 阶段三:详细设计
| 任务编号 | 任务名称 | 负责人 | 计划开始 | 计划结束 | 实际开始 | 实际结束 | 完成百分比 | 状态 | 备注 |
|---------|---------|--------|---------|---------|---------|---------|-----------|------|------|
| DET-001 | 模块一详细设计 | | | | | | | | |
| DET-002 | 模块二详细设计 | | | | | | | | |
| DET-003 | 模块三详细设计 | | | | | | | | |
### 3.4 阶段四:编码实现
| 任务编号 | 任务名称 | 负责人 | 计划开始 | 计划结束 | 实际开始 | 实际结束 | 完成百分比 | 状态 | 备注 |
|---------|---------|--------|---------|---------|---------|---------|-----------|------|------|
| DEV-001 | 模块一开发 | | | | | | | | |
| DEV-002 | 模块二开发 | | | | | | | | |
| DEV-003 | 模块三开发 | | | | | | | | |
| DEV-004 | 模块四开发 | | | | | | | | |
| DEV-005 | 模块五开发 | | | | | | | | |
| DEV-006 | 系统集成 | | | | | | | | |
### 3.5 阶段五:单元测试
| 任务编号 | 任务名称 | 负责人 | 计划开始 | 计划结束 | 实际开始 | 实际结束 | 完成百分比 | 状态 | 备注 |
|---------|---------|--------|---------|---------|---------|---------|-----------|------|------|
| UT-001 | 模块一单元测试 | | | | | | | | |
| UT-002 | 模块二单元测试 | | | | | | | | |
| UT-003 | 模块三单元测试 | | | | | | | | |
### 3.6 阶段六:集成测试
| 任务编号 | 任务名称 | 负责人 | 计划开始 | 计划结束 | 实际开始 | 实际结束 | 完成百分比 | 状态 | 备注 |
|---------|---------|--------|---------|---------|---------|---------|-----------|------|------|
| IT-001 | 接口集成测试 | | | | | | | | |
| IT-002 | 系统集成测试 | | | | | | | | |
### 3.7 阶段七:系统测试
| 任务编号 | 任务名称 | 负责人 | 计划开始 | 计划结束 | 实际开始 | 实际结束 | 完成百分比 | 状态 | 备注 |
|---------|---------|--------|---------|---------|---------|---------|-----------|------|------|
| ST-001 | 功能测试 | | | | | | | | |
| ST-002 | 性能测试 | | | | | | | | |
| ST-003 | 安全测试 | | | | | | | | |
| ST-004 | 兼容性测试 | | | | | | | | |
### 3.8 阶段八:用户验收测试
| 任务编号 | 任务名称 | 负责人 | 计划开始 | 计划结束 | 实际开始 | 实际结束 | 完成百分比 | 状态 | 备注 |
|---------|---------|--------|---------|---------|---------|---------|-----------|------|------|
| UAT-001 | 用户验收测试 | | | | | | | | |
| UAT-002 | 问题修复 | | | | | | | | |
### 3.9 阶段九:上线部署
| 任务编号 | 任务名称 | 负责人 | 计划开始 | 计划结束 | 实际开始 | 实际结束 | 完成百分比 | 状态 | 备注 |
|---------|---------|--------|---------|---------|---------|---------|-----------|------|------|
| DEP-001 | 环境准备 | | | | | | | | |
| DEP-002 | 系统部署 | | | | | | | | |
| DEP-003 | 数据迁移 | | | | | | | | |
| DEP-004 | 上线验证 | | | | | | | | |
## 4 里程碑节点
| 里程碑 | 计划完成时间 | 实际完成时间 | 状态 | 说明 |
|--------|-------------|-------------|------|------|
| 需求确认 | | | | |
| 设计评审通过 | | | | |
| 开发完成 | | | | |
| 测试完成 | | | | |
| 验收通过 | | | | |
| 正式上线 | | | | |
## 5 资源投入情况
| 角色 | 计划人数 | 实际人数 | 计划工时 | 实际工时 | 说明 |
|------|---------|---------|---------|---------|------|
| 项目经理 | | | | | |
| 需求分析师 | | | | | |
| 系统架构师 | | | | | |
| 开发人员 | | | | | |
| 测试人员 | | | | | |
| UI设计师 | | | | | |
| 其他 | | | | | |
## 6 风险与问题跟踪
| 序号 | 风险/问题描述 | 影响程度 | 应对措施 | 责任人 | 状态 | 更新时间 |
|------|--------------|---------|---------|--------|------|---------|
| 1 | | | | | | |
| 2 | | | | | | |
| 3 | | | | | | |
AI生成成套文档-05-测试报告
# 测试报告
| 项目名称 | |
|---------|--|
| 文档版本 | v1.0 |
| 编写日期 | |
| 编写人员 | |
| 审核人员 | |
| 批准人员 | |
---
**文档修订历史**
| 版本号 | 修订日期 | 修订人员 | 修订内容 |
|--------|---------|---------|---------|
| v1.0 | | | 初始版本 |
## 1. 概述
### 1.1 编写目的
说明编写本测试报告的目的和适用范围。
### 1.2 测试范围
描述本次测试的范围,包括:
- 功能测试范围
- 性能测试范围
- 安全测试范围
- 兼容性测试范围
### 1.3 测试环境
#### 1.3.1 硬件环境
- 服务器配置
- 客户端配置
- 网络环境
#### 1.3.2 软件环境
- 操作系统
- 数据库
- 中间件
- 浏览器版本
### 1.4 测试依据
列出测试依据的文档:
- 需求规格说明书
- 设计文档
- 测试计划
- 其他相关文档
## 2. 测试概要
### 2.1 测试时间
- 测试开始时间:
- 测试结束时间:
- 测试周期:
### 2.2 测试人员
| 姓名 | 角色 | 职责 |
|------|------|------|
| | | |
| | | |
### 2.3 测试工具
| 工具名称 | 版本 | 用途 |
|---------|------|------|
| | | |
| | | |
### 2.4 测试方法
- 功能测试方法
- 性能测试方法
- 安全测试方法
- 自动化测试方法
## 3. 测试执行情况
### 3.1 测试用例执行统计
| 测试类型 | 用例总数 | 执行数 | 通过数 | 失败数 | 阻塞数 | 通过率 |
|---------|---------|--------|--------|--------|--------|--------|
| 功能测试 | | | | | | |
| 性能测试 | | | | | | |
| 安全测试 | | | | | | |
| 兼容性测试 | | | | | | |
| 回归测试 | | | | | | |
| **合计** | | | | | | |
### 3.2 缺陷统计
#### 3.2.1 缺陷分布统计
| 严重程度 | 数量 | 占比 |
|---------|------|------|
| 致命(P1) | | |
| 严重(P2) | | |
| 一般(P3) | | |
| 轻微(P4) | | |
| **合计** | | |
#### 3.2.2 缺陷状态统计
| 缺陷状态 | 数量 | 占比 |
|---------|------|------|
| 新建 | | |
| 已修复 | | |
| 已验证 | | |
| 已关闭 | | |
| 拒绝 | | |
| 延期 | | |
| **合计** | | |
#### 3.2.3 缺陷模块分布
| 模块名称 | 缺陷数量 | 占比 |
|---------|---------|------|
| | | |
| | | |
| **合计** | | |
## 4. 测试结果分析
### 4.1 功能测试结果
#### 4.1.1 模块一测试结果
- **测试用例数**:
- **通过数**:
- **失败数**:
- **通过率**:
- **主要问题**:
- 问题描述1
- 问题描述2
#### 4.1.2 模块二测试结果
(按照5.1.1的格式继续描述其他模块)
### 4.2 性能测试结果
#### 4.2.1 响应时间测试
| 功能模块 | 平均响应时间 | 最大响应时间 | 是否满足要求 |
|---------|-------------|-------------|-------------|
| | | | |
| | | | |
#### 4.2.2 并发测试
| 并发用户数 | 平均响应时间 | 成功率 | 是否满足要求 |
|-----------|-------------|--------|-------------|
| | | | |
| | | | |
#### 4.2.3 负载测试
- 测试场景描述
- 测试结果
- 性能瓶颈分析
### 4.3 安全测试结果
- 安全漏洞统计
- 安全测试结果分析
- 安全建议
### 4.4 兼容性测试结果
| 测试项 | 测试环境 | 测试结果 | 备注 |
|--------|---------|---------|------|
| 浏览器兼容性 | | | |
| 操作系统兼容性 | | | |
| 移动端兼容性 | | | |
## 5. 缺陷分析
### 5.1 缺陷趋势分析
- 缺陷发现趋势图/表
- 缺陷修复趋势图/表
### 5.2 缺陷原因分析
| 缺陷原因 | 数量 | 占比 | 说明 |
|---------|------|------|------|
| 需求理解偏差 | | | |
| 设计缺陷 | | | |
| 编码错误 | | | |
| 测试环境问题 | | | |
| 其他 | | | |
### 5.3 严重缺陷列表
| 缺陷ID | 缺陷描述 | 严重程度 | 状态 | 发现时间 | 修复时间 |
|--------|---------|---------|------|---------|---------|
| | | | | | |
| | | | | | |
## 6. 测试结论
### 6.1 测试完成情况
- 测试计划完成情况
- 测试用例执行情况
- 缺陷修复验证情况
### 6.2 质量评估
- 功能完整性评估
- 性能指标评估
- 安全性评估
- 稳定性评估
### 6.3 风险评估
- 遗留风险
- 风险等级
- 风险应对措施
### 6.4 测试结论
- 是否通过测试
- 是否可以发布
- 发布建议
## 7. 建议
### 7.1 功能改进建议
- 建议1
- 建议2
### 7.2 性能优化建议
- 建议1
- 建议2
### 7.3 其他建议
- 建议1
- 建议2
## 8. 附录
### 8.1 测试用例清单
(可引用测试用例文档或列出关键测试用例)
### 8.2 缺陷清单
(可引用缺陷管理系统或列出关键缺陷)
### 8.3 测试数据
- 测试数据说明
- 测试数据文件
AI生成成套文档-06-操作手册
# 操作手册
##
| 项目名称 | |
|---------|--|
| 文档版本 | v1.0 |
| 编写日期 | |
| 编写人员 | |
| 审核人员 | |
| 批准人员 | |
**文档修订历史**
| 版本号 | 修订日期 | 修订人员 | 修订内容 |
|--------|---------|---------|---------|
| v1.0 | | | 初始版本 |
## 1. 概述
### 1.1 编写目的
说明编写本操作手册的目的和适用范围。
### 1.2 系统简介
简要介绍系统的功能、特点和应用场景。
### 1.3 术语定义
列出文档中使用的专业术语及其定义。
### 1.4 参考资料
列出编写本手册时参考的相关文档和资料。
## 2. 系统环境要求
### 2.1 硬件环境
- 服务器配置要求
- 客户端配置要求
- 网络环境要求
### 2.2 软件环境
- 操作系统要求
- 数据库要求
- 中间件要求
- 浏览器要求
- 其他依赖软件
## 3. 系统安装部署
### 3.1 安装前准备
- 环境检查清单
- 权限要求
- 备份要求
### 3.2 安装步骤
#### 3.2.1 数据库安装配置
1. 步骤一
2. 步骤二
3. ...
#### 3.2.2 应用服务器安装配置
1. 步骤一
2. 步骤二
3. ...
#### 3.2.3 客户端安装配置
1. 步骤一
2. 步骤二
3. ...
### 3.3 系统初始化
- 初始化步骤
- 初始数据配置
- 系统参数设置
### 3.4 安装验证
- 验证方法
- 验证标准
## 4. 系统功能操作
### 4.1 系统登录
#### 4.1.1 登录方式
- 描述登录方式
#### 4.1.2 登录步骤
1. 打开系统登录页面
2. 输入用户名和密码
3. 点击登录按钮
4. 验证登录结果
#### 4.1.3 常见问题
- 问题描述及解决方案
### 4.2 功能模块一
#### 4.2.1 功能概述
- 功能描述
#### 4.2.2 操作步骤
1. 步骤一
2. 步骤二
3. ...
#### 4.2.3 操作界面说明
- 界面元素说明
- 字段说明
#### 4.2.4 注意事项
- 操作注意事项
### 4.3 功能模块二
(按照5.2的格式继续描述其他功能模块)
## 5. 系统维护
### 5.1 日常维护
- 日志查看
- 数据备份
- 性能监控
### 5.2 数据备份与恢复
#### 5.2.1 数据备份
- 备份方式
- 备份频率
- 备份步骤
#### 5.2.2 数据恢复
- 恢复方式
- 恢复步骤
### 5.3 系统升级
- 升级前准备
- 升级步骤
- 升级后验证
### 5.4 故障处理
#### 5.4.1 常见故障及解决方案
| 故障现象 | 可能原因 | 解决方案 |
|---------|---------|---------|
| | | |
| | | |
#### 5.4.2 故障上报流程
- 故障上报联系方式
- 故障上报内容要求
## 6. 系统配置
### 6.1 系统参数配置
- 参数说明
- 配置方法
### 6.2 用户权限配置
- 角色定义
- 权限分配方法
## 7. 附录
### 7.1 快捷键说明
| 快捷键 | 功能说明 |
|--------|---------|
| | |
| | |
### 7.2 错误代码说明
| 错误代码 | 错误描述 | 解决方案 |
|---------|---------|---------|
| | | |
| | | |
AI生成成套文档-07-验收报告
# 项目验收报告
## 1. 文档信息
| 项目名称 | |
|---------|----------------|
| 文档版本 | v1.0 |
| 编写日期 | |
| 编写人员 | |
| 审核人 | |
| 批准人员 | |
**文档修订历史**
| 版本号 | 修订日期 | 修订人员 | 修订内容 |
|--------|---------|---------|---------|
| v1.0 | | | 初始版本 |
## 2. 项目基本信息
### 2.1 项目概况
| 项目名称 | |
|---------|----------------|
| 项目编号 | |
| 项目类型 | |
| 项目开始时间 | |
| 项目完成时间 | |
| 项目周期 | |
### 2.2 项目概述
本项目依据《需求规格说明书》开展建设,概述如下。
**项目来源与背景**
描述项目的背景、立项原因和业务价值。
**建设目标**
- **总体目标**:
- **业务目标**:
- **技术目标**:
**系统范围**
系统包含功能模块,与《系统建设方案》功能域一致。南向依赖外部平台提供视频流,北向向外部平台推送告警事件与统计数据。
**项目意义**
提升安全防控效率、规范事件处置流程、优化算法与资源利用、降低集成与运维成本,支撑园区智能化升级。
### 2.3 验收组织
| 姓名 | 角色 |
|------|----------|
| | |
| | |
| | |
| | |
| | |
## 3. 验收依据
### 3.1 合同依据
- 项目编号:
- 项目启动日期:
- 项目主要内容:
### 3.2 文档依据
- 《需求规格说明书》
- 《系统建设方案》
- 系统设计说明书、接口规范
- 测试报告
- 操作手册
- 其他相关文档
### 3.3 标准依据
- GB/T28181 安全防范视频监控联网系统信息传输、交换、控制技术要求
- 智慧园区管理平台安防管理需求
- GB/T 22239 信息安全技术 网络安全等级保护基本要求、企业软件开发与文档规范
## 4. 项目完成情况
### 4.1 功能完成情况
#### 4.1.1 功能完成统计
| 功能模块 | 计划功能数 | 完成功能数 | 完成率 | 验收状态 |
|---------|-----------|-----------|--------|---------|
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| **合计** | **0** | **0** | **0%** | **通过** |
**模块说明**:
- **模块一**:
- **模块二**:
- **模块三**:
- **模块四**:
#### 4.1.2 功能验收清单
**模块一**
| 功能编号 | 功能名称 | 验收结果 | 备注 |
|---------|---------|---------|------|
| | | | |
| | | | |
**模块二**
| 功能编号 | 功能名称 | 验收结果 | 备注 |
|---------|---------|---------|------|
| | | | |
| | | | |
**验收结果说明**:
**功能验收标准**:
- **完整性**:P0 功能需求全部实现,且与建设方案描述一致;关键业务规则得到落实。
- **正确性**:核心流程按需求正确运行,无重大功能缺陷。
### 4.2 性能指标验收
#### 4.2.1 性能指标对比
| 性能指标 | 要求值 | 实际值 | 是否满足 | 验收结果 |
|---------|--------|--------|---------|---------|
| | | | | |
| | | | | |
| | | | | |
| | | | | |
#### 4.2.2 性能测试结果
- **性能测试方法**:
- **性能测试数据**:
- **性能测试结论**:
### 4.3 质量指标验收
#### 4.3.1 质量指标对比
| 质量指标 | 要求值 | 实际值 | 是否满足 | 验收结果 |
|---------|--------|--------|---------|---------|
| | | | | |
| | | | | |
| | | | | |
#### 4.3.2 质量测试结果
- **质量测试方法**:
- **质量测试数据**:
- **质量测试结论**:
### 4.4 交付物验收
#### 4.4.1 交付物清单
| 序号 | 交付物名称 | 交付形式 | 数量 | 验收状态 | 备注 |
|------|-----------|---------|------|---------|------|
| 1 | 需求规格说明书 | 文档 | 1 | 已交付 | |
| 2 | 系统设计文档 | 文档 | 1 套 | 已交付 | |
| 3 | 源代码 | 代码 | 1 套 | 已交付 | |
| 4 | 可执行程序/部署包 | 软件 | 1 套 | 已交付 | |
| 5 | 数据库脚本 | 脚本 | 1 套 | 已交付 | |
| 6 | 测试报告 | 文档 | 1 | 已交付 | |
| 7 | 操作手册 | 文档 | 1 | 已交付 | |
#### 4.4.2 交付物质量
- **文档完整性**:
- **文档规范性**:
- **代码规范性**:
- **其他质量要求**:
## 5. 系统测试验收
### 5.1 测试环境
- **测试环境描述**:
- **测试环境配置**:
### 5.2 测试执行情况
| 测试类型 | 测试用例数 | 执行数 | 通过数 | 失败数 | 通过率 |
|---------|-----------|--------|--------|--------|--------|
| 功能测试 | | | | | |
| 性能测试 | | | | | |
| 安全测试 | | | | | |
| 兼容性测试 | | | | | |
| **合计** | **0** | **0** | **0** | **0** | **0%** |
### 5.3 缺陷情况
#### 5.3.1 缺陷统计
| 严重程度 | 数量 | 已修复 | 未修复 | 修复率 |
|---------|------|--------|--------|--------|
| 致命(P1) | | | | |
| 严重(P2) | | | | |
| 一般(P3) | | | | |
| 轻微(P4) | | | | |
| **合计** | **0** | **0** | **0** | **0%** |
#### 5.3.2 遗留问题
| 问题编号 | 问题描述 | 严重程度 | 影响范围 | 处理计划 |
|---------|---------|---------|---------|---------|
| | | | | |
| | | | | |
### 5.4 测试结论
- **测试完成情况**:
- **测试结果评价**:
- **测试结论**:
## 6. 系统试运行验收
### 6.1 试运行情况
#### 6.1.1 试运行时间
- 试运行开始时间:
- 试运行结束时间:
- 试运行周期:
#### 6.1.2 试运行范围
- **试运行环境**:
- **试运行用户**:
- **试运行功能**:
### 6.2 试运行结果
#### 6.2.1 系统运行情况
- **系统稳定性**:
- **系统可用性**:
- **系统性能**:
#### 6.2.2 用户反馈
- **用户满意度**:
- **用户意见**:
- **用户建议**:
#### 6.2.3 问题处理
- **发现问题数量**:
- **问题处理情况**:
- **遗留问题**:
### 6.3 试运行结论
- **试运行评价**:
- **试运行结论**:
## 7. 技术文档验收
### 7.1 文档完整性
- **文档清单检查**:
- **文档完整性评价**:
### 7.2 文档质量
- **文档规范性**:
- **文档准确性**:
- **文档可读性**:
### 7.3 文档验收结果
- **文档验收结论**:
## 8. 培训验收
### 8.1 培训情况
#### 8.1.1 培训计划执行
- **培训计划**:
- **培训执行情况**:
#### 8.1.2 培训内容
- **培训内容清单**:
- **培训材料**:
#### 8.1.3 培训效果
- **培训人数**:
- **培训考核结果**:
- **培训效果评价**:
### 8.2 培训验收结果
- **培训验收结论**:
## 9. 验收测试
### 9.1 验收测试环境
- **测试环境描述**:
- **测试环境配置**:
### 9.2 验收测试执行
#### 9.2.1 功能验收测试
| 测试项 | 测试结果 | 测试人员 | 测试时间 | 备注 |
|--------|---------|---------|---------|------|
| | | | | |
| | | | | |
#### 9.2.2 性能验收测试
| 测试项 | 测试结果 | 测试人员 | 测试时间 | 备注 |
|--------|---------|---------|---------|------|
| | | | | |
| | | | | |
#### 9.2.3 其他验收测试
- **安全与审计**:
- **备份与恢复**:
- **测试结果**:
### 9.3 验收测试结论
- **验收测试评价**:
- **验收测试结论**:
## 10. 验收意见
### 10.1 功能验收意见
- **功能实现情况评价**:
- **功能验收意见**:
### 10.2 性能验收意见
- **性能指标达成情况评价**:
- **性能验收意见**:
### 10.3 质量验收意见
- **质量指标达成情况评价**:
- **质量验收意见**:
### 10.4 文档验收意见
- **文档质量评价**:
- **文档验收意见**:
### 10.5 综合验收意见
- **项目整体评价**:
- **综合验收意见**:
## 11. 遗留问题
### 11.1 遗留问题清单
| 问题编号 | 问题描述 | 严重程度 | 影响范围 | 处理计划 | 责任人 | 计划完成时间 |
|---------|---------|---------|---------|---------|--------|-------------|
| | | | | | | |
| | | | | | | |
### 11.2 遗留问题处理
- **问题处理计划**:
- **问题处理责任**:
- **问题处理时间**:
## 12. 验收结论
### 12.1 验收结论
- [ ] 验收通过
- [ ] 验收不通过
- [ ] 有条件通过
### 12.2 验收结论说明
验收组依据《需求规格说明书》及合同约定进行核查,结论如下:
### 12.3 后续工作建议
-
-
-
## 13. 验收意见
验收组依据《需求规格说明书》、项目合同及验收依据文档,对项目进行了功能、性能、质量、交付物、技术文档及培训等方面的核查与验收,形成如下验收意见。
**一、总体评价**
**二、功能验收意见**
**三、性能验收意见**
**四、质量与安全验收意见**
**五、文档与交付物验收意见**
**六、培训验收意见**
**七、综合结论与遗留事项**
---
AI生成成套文档-08-结项报告
# 结项报告
## 1. 文档信息
| 项目名称 | |
|---------|--|
| 文档版本 | v1.0 |
| 编写日期 | |
| 编写人员 | |
| 审核人员 | |
| 批准人员 | |
---
**文档修订历史**
| 版本号 | 修订日期 | 修订人员 | 修订内容 |
|--------|---------|---------|---------|
| v1.0 | | | 初始版本 |
## 2. 项目概述
### 2.1 项目基本信息
| 项目名称 | |
|---------|--|
| 项目编号 | |
| 项目开始时间 | |
| 项目结束时间 | |
| 项目周期 | |
| 项目负责人 | |
| 项目团队 | |
### 2.2 项目背景
描述项目的背景、立项原因和业务价值。
### 2.3 项目目标
- 业务目标
- 技术目标
- 质量目标
### 2.4 项目范围
- 项目包含的内容
- 项目不包含的内容(如有)
## 3. 项目执行情况
### 3.1 项目进度
#### 3.1.1 计划进度
| 阶段 | 开始时间 | 结束时间 |
| ------------------ | ---------- | ---------- |
| 需求分析 | | |
| 系统设计 | | |
| 详细设计 | | |
| 编码实现 | | |
| 系统测试 | | |
| 用户验收测试 | | |
| 上线部署与验收 | | |
| 结项 | | |
#### 3.1.2 实际进度
| 阶段 | 开始时间 | 结束时间 |
| ------------------ | ---------- | ---------- |
| 需求分析 | | |
| 系统设计 | | |
| 详细设计 | | |
| 编码实现 | | |
| 系统测试 | | |
| 用户验收测试 | | |
| 上线部署与验收 | | |
| 结项 | | |
#### 3.1.3 进度对比分析
| 阶段 | 计划时间 | 实际时间 | 偏差 | 原因分析 |
|------|---------|---------|------|---------|
| 需求分析 | | | | |
| 系统设计 | | | | |
| 详细设计 | | | | |
| 编码实现 | | | | |
| 系统测试 | | | | |
| 用户验收测试 | | | | |
| 上线部署与验收 | | | | |
| 结项 | | | | |
### 3.2 项目成本
#### 3.2.1 预算情况
| 成本项 | 预算金额 | 实际金额 | 偏差 | 说明 |
|--------|---------|---------|------|------|
| 人力成本 | | | | |
| 设备成本 | | | | |
| 软件成本 | | | | |
| 其他成本 | | | | |
| **合计** | | | | |
#### 3.2.2 成本分析
- 成本控制情况
- 成本偏差原因分析
### 3.3 项目质量
#### 3.3.1 质量指标达成情况
| 质量指标 | 目标值 | 实际值 | 达成情况 |
|---------|--------|--------|---------|
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
#### 3.3.2 质量分析
- 质量目标达成情况
- 质量问题分析
### 3.4 项目资源
#### 3.4.1 人力资源
| 角色 | 计划人数 | 实际人数 | 说明 |
|------|---------|---------|------|
| 项目经理 | | | |
| 需求分析师 | | | |
| 系统架构师 | | | |
| 开发人员 | | | |
| 测试人员 | | | |
| 其他 | | | |
#### 3.4.2 其他资源
- 硬件资源:
- 软件资源:
## 4. 项目成果
### 4.1 交付成果清单
| 序号 | 交付物名称 | 交付形式 | 交付日期 | 验收状态 |
|------|-----------|---------|---------|---------|
| 1 | 需求规格说明书 | 文档 | | |
| 2 | 系统设计文档 | 文档 | | |
| 3 | 源代码 | 代码 | | |
| 4 | 测试报告 | 文档 | | |
| 5 | 操作手册 | 文档 | | |
| 6 | 系统部署包 | 软件 | | |
| 7 | 北向接口对接文档 | 文档 | | |
### 4.2 功能实现情况
#### 4.2.1 功能完成情况统计
| 功能模块 | 计划功能数 | 完成功能数 | 完成率 | 说明 |
|---------|-----------|-----------|--------|------|
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| **合计** | | | | |
#### 4.2.2 主要功能说明
- **功能模块一**
- **功能描述**:
- **实现情况**:
- **功能模块二**
- **功能描述**:
- **实现情况**:
### 4.3 技术成果
- 技术创新点
- 技术难点及解决方案
- 可复用组件/框架
## 5. 项目问题与风险
### 5.1 项目问题
#### 5.1.1 已解决问题
| 问题描述 | 影响程度 | 解决方案 | 解决时间 |
|---------|---------|---------|---------|
| | | | |
| | | | |
#### 5.1.2 遗留问题
| 问题描述 | 影响程度 | 处理计划 | 责任人 |
|---------|---------|---------|--------|
| | | | |
| | | | |
### 5.2 项目风险
#### 5.2.1 已识别风险
| 风险描述 | 风险等级 | 应对措施 | 状态 |
|---------|---------|---------|------|
| | | | |
| | | | |
#### 5.2.2 遗留风险
| 风险描述 | 风险等级 | 应对措施 | 责任人 |
|---------|---------|---------|--------|
| | | | |
| | | | |
## 6. 项目经验总结
### 6.1 成功经验
-
-
-
### 6.2 不足与改进
-
-
-
### 6.3 最佳实践
-
-
-
## 7. 项目评价
### 7.1 目标达成情况
- 业务目标达成情况
- 技术目标达成情况
- 质量目标达成情况
### 7.2 客户满意度
- 客户反馈
- 满意度评分
### 7.3 项目评价
- 项目整体评价
- 项目亮点
- 项目不足
## 8. 后续工作
### 8.1 维护计划
- **维护内容**:
- **维护周期**:
- **维护人员**:
### 8.2 优化计划
- **优化内容**:
- **优化时间安排**:
- **优化资源需求**:
### 8.3 培训计划
- **培训内容**:
- **培训对象**:
- **培训时间**:
## 9. 附录
### 9.1 项目团队名单
| 姓名 | 角色 | 职责 | 参与时间 |
|------|------|------|---------|
| | | | |
| | | | |
### 9.2 项目里程碑
| 里程碑 | 计划时间 | 实际时间 | 状态 |
|--------|---------|---------|------|
| | | | |
| | | | |
### 9.3 相关文档清单
-
-
-
-
各种文件格式转md
LLM最喜欢文档(资料)是md,处理例如word,pdf,excel时非常慢。可以预先把文档转换成md以提高效率
github主页:https://github.com/microsoft/markitdown
安装与使用
# 安装(基础安装)
pip install markitdown
# 全量安装,支持更多的文档格式转换
pip install markitdown[all] -i https://pypi.tuna.tsinghua.edu.cn/simple
# 从源代码安装
git clone git@github.com:microsoft/markitdown.git
cd markitdown
pip install -e 'packages/markitdown[all]'
# 使用参数转换(推荐,有时候使用重定向符无法转换的文档使用-o参数可以转换)
markitdown path-to-file.pdf -o document.md
# 使用重定向符转换
markitdown path-to-file.pdf > document.md
# 使用管道转换
cat path-to-file.pdf | markitdown
代码集成
from markitdown import MarkItDown
md = MarkItDown(enable_plugins=False) # Set to True to enable plugins
result = md.convert("test.xlsx")
print(result.text_content)
cursor多工作区&&前后台一起开发
将文件夹增加到工作区