deepseek
- deepseek 环境搭建
- docker搭建deepseek运行环境和open-webui
- deepseek和dify环境搭建
- deepseek嵌入工作流实现直接驱动业务的探索
- 网站采集工具firecrawl
- deepseek提示词小技巧
- deepseek开发流程
- 通义千问&&deepseek模型对比
- 优秀提示词示例
deepseek 环境搭建
这篇文章是入门文章,没有什么实用价值,仅是将运行deepseek的环境运行起来了。
主要软件
- ollama:模型运行平台,https://ollama.com/download
- open-webui:简单的chat页面,https://github.com/open-webui/open-webui
- dify :模型编排平台,https://github.com/langgenius/dify
- docker
- python
- 3.11:open-webui需要的运行时版本
- 科学上网:https://iovhm.com/book/books/cee63/page/9872e
ollama可以直接在容器运行
不用担心在容器运行会有性能损失,经过多年对docker的实践,除了网络方面会有损失外,其他方面并没有损失,可以将网络设置为host模式来规避bridge网络的性能损失。
相反,如果在主机直接运行,各种版本的依赖,新版本的升级,环境更加容易出问题。
version: "3"
services:
ollama:
image: harbor.iovhm.com/hub/ollama/ollama:0.5.12
container_name: ollama
restart: always
privileged: true
ports:
- "11434:11434"
volumes:
- ./ollama:/root/.ollama
networks:
- vpclub-bridge
安装模型运行平台ollama
模型运行平台下载:https://ollama.com/download
模型备份
每次下载模型都需要很久,可以将模型备份出来
进入到用户文件夹下面,例如 C:\Users\admin.ollama\models , 将模型复制出来,复制到新的机器对应的目录(未验证)
下载和运行模型
# 显示所有命令行参数
ollama
# 所有的命令行
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
# 运行服务,如果服务没有运行,可以用这个启动服务,非必须,一般安装完成后都会自动运行
ollama serve
# 验证安装
ollama -v
# 下载模型
ollama pull deepseek-r1:1.5b
# 运行模型
# 如果本地没有这个模型,则会自动下载并运行
# 运行后,此时会出现一个对话窗口,可以进行输入文字进行对话
# 键入/bye 或者ctrl+d可以退出对话窗口,模型在后台运行
# 退出对话框后,如果需要再次进入对话框,可以在此run模型
ollama run deepseek-r1:1.5b
# 显示已经安装的模型列表
ollama list
# 显示所有在运行的模型列表
ollama ps
# 显示模型信息
ollama show deepseek-r1:1.5b
使用API对话
默认安装没有修改配置的话,ollama 运行在11343端口,可以使用命令行或者postmain测试
这种方式太简陋,要实现的内容太多,不推荐
curl -X POST -H "Content-Type: application/json" \
-d '{"model": "deepseek-r1:1.5b", "prompt": "你好,世界!"}' \
http://localhost:11434/api/generate
使用open-webui
这是一个简单的兼容多个模型的、兼容openai接口调用方式的可视化界面
下载地址:https://github.com/open-webui/open-webui
文档地址:https://docs.openwebui.com/
可以直接使用docker运行,docker的安装方式自行百度,优先推荐使用docker安装
# GPU版
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
# CPU版
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
# pip 安装
pip install open-webui -i https://pypi.tuna.tsinghua.edu.cn/simple
# python运行
# 此时系统运行在 http://localhost:8080
open-webui serve
详细设置请看:https://iovhm.com/book/books/bbcbf/page/deepseek-docker
docker搭建deepseek运行环境和open-webui
这篇文章没有什么实用价值,仅作为快速体验ollama运行环境。或者当做一个附加工具,用来管理和查看ollama环境。
docker-compose.yaml
这个脚本将同时启动ollama 和 open-webui
version: "3"
services:
ollama:
image: harbor.iovhm.com/hub/ollama/ollama:0.5.12
container_name: ollama
restart: always
privileged: true
ports:
- "11434:11434"
volumes:
- ./ollama:/root/.ollama
networks:
- vpclub-bridge
# docker-compose --profile open-webui up -d
open-webui:
# CPU版
image: harbor.iovhm.com/public/open-webui/open-webui:main
# GPU版
# image: harbor.iovhm.com/public/open-webui/open-webui:main-gpu
container_name: open-webui
restart: always
privileged: true
ports:
- "3000:8080"
volumes:
- ./open-webui:/app/backend/data
environment:
# 如果你的 ollama 服务器不在本机,请修改此地址,如果OLLAMA_BASE_URLS被设置,则使用OLLAMA_BASE_URLS
# - OLLAMA_BASE_URL=http://ollama:11434
# 如果你的 ollama 服务器不在本机,请修改此地址,可以使用分号分割多个地址提供负载均衡能力
- OLLAMA_BASE_URLS=http://ollama:11434
# 关闭 openai api 否则会因为连不上openai而卡界面
- ENABLE_OPENAI_API=false
# 禁用自带的 Arena Model模型(竞技场模型)
- ENABLE_EVALUATION_ARENA_MODELS=false
# 关闭社区分享功能
- ENABLE_COMMUNITY_SHARING=false
# 离线模式,不自动从Internet下载模型(非必须,有魔法的话不需要设置)
# - HF_HUB_OFFLINE=true
# 默认的语义向量模型引擎(非必须)
# - RAG_EMBEDDING_ENGINE=ollama
# 默认的语义向量模型(非必须)
# - RAG_EMBEDDING_MODEL=nomic-embed-text:latest
networks:
- vpclub-bridge
networks:
vpclub-bridge:
external:
name: vpclub-bridge
测试一下服务
打开浏览器,输入ollama的服务地址, http://ip:11434 ,界面提示:Ollama is running ,则表示ollama安装成功了
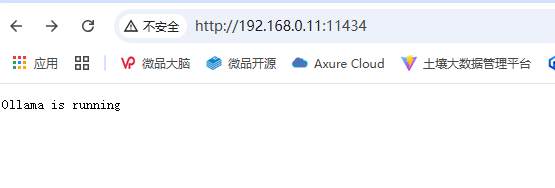
输入open-webui的地址,http://ip:3000 , 则可以看到open-webui的地址。

但是这个时候可能是白屏,什么都看不到;或者好不容易刷出来界面,设置好用户名密码进入系统后,也是白屏,此时应该去查看open-webui容器的出错提示,多半都是被墙拉取不到镜像的原因。那你需要魔法。
界面打不开,或者进去了也很卡问题解决
- 打开open-webui等很久,不出来界面,白屏
因为软件有很多外部依赖要下载,如果被墙,下载不到、就一直卡住,可以先不使用openai和不使用内置的语义向量模型模型
# 修改open-webui的环境变量设置
# 关闭 openai api 否则会因为连不上openai而卡界面
- ENABLE_OPENAI_API=false
# 默认的RAG引擎(非必须)
- RAG_EMBEDDING_ENGINE=ollama
# 默认的语义向量模型(非必须)
- RAG_EMBEDDING_MODEL=nomic-embed-text:latest
进入软件后,每次刷新都要等很久
关闭使用openai外部链接,修改语义向量模型
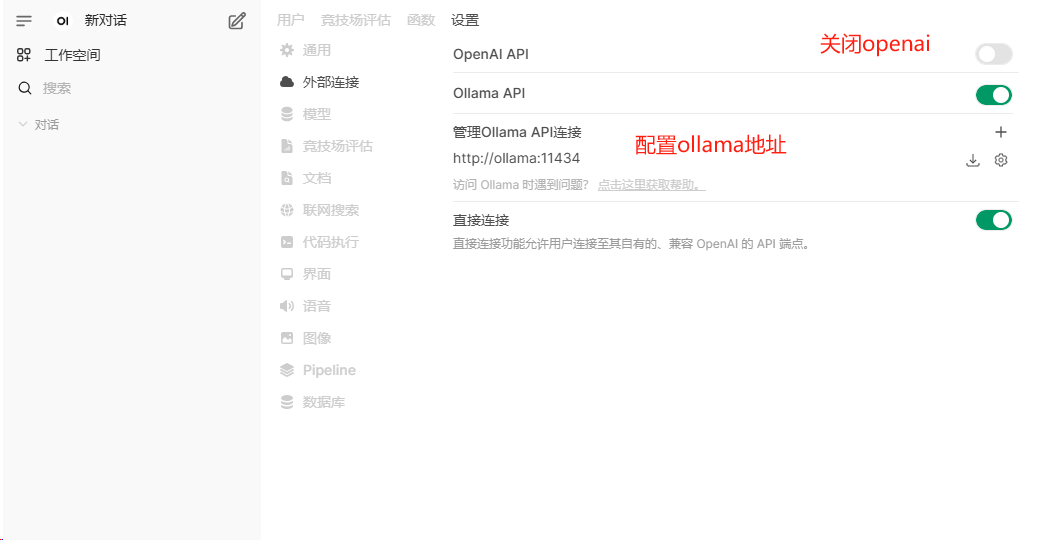
修改语义向量模型
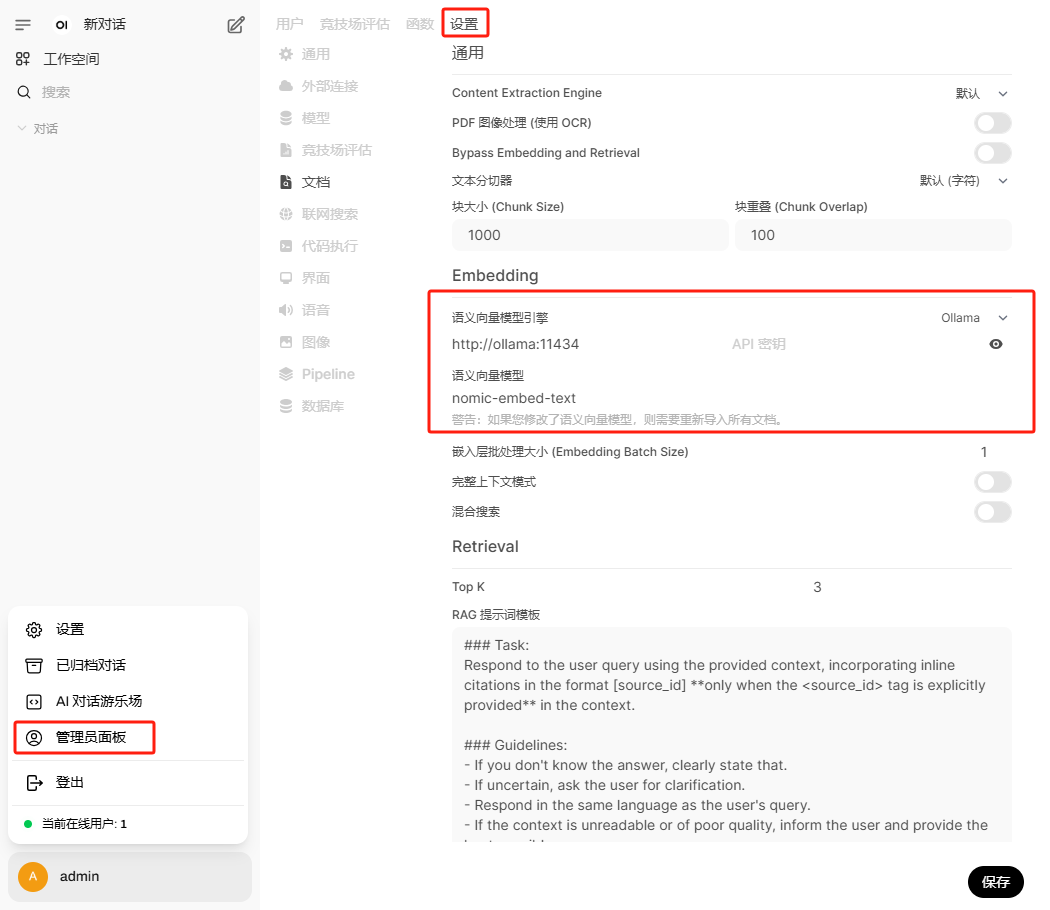
进入到ollama容器下载模型
# 安装完成后进入ollma容器
docker exec -it ollama /bin/bash
# 查看ollama版本
ollama -v
# 下载deepseek模型
ollama run deepseek-r1:7b
# 语义向量模型
ollama pull nomic-embed-text
查看系统当前都安装了什么模型
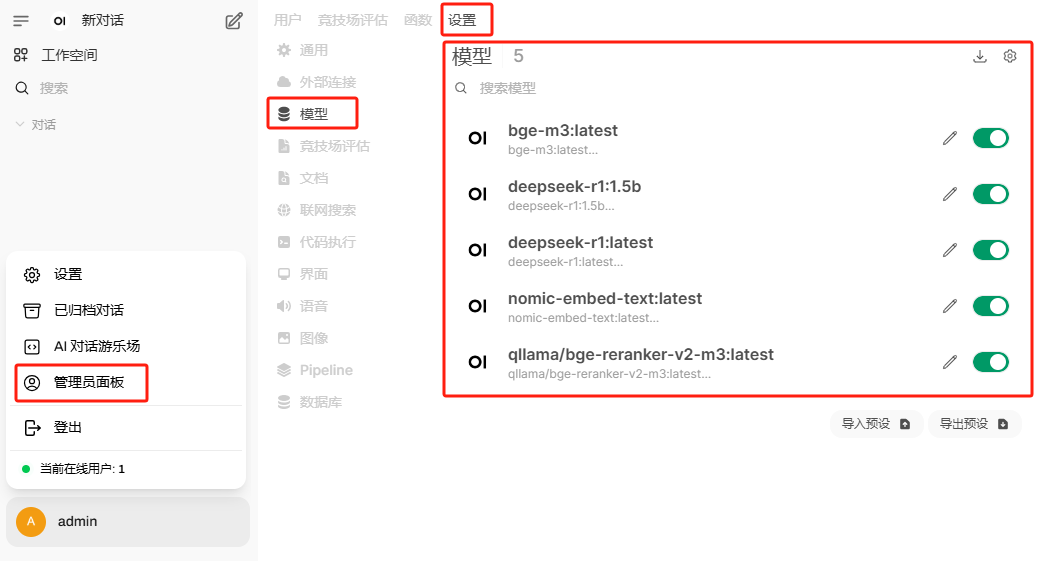
配置知识库
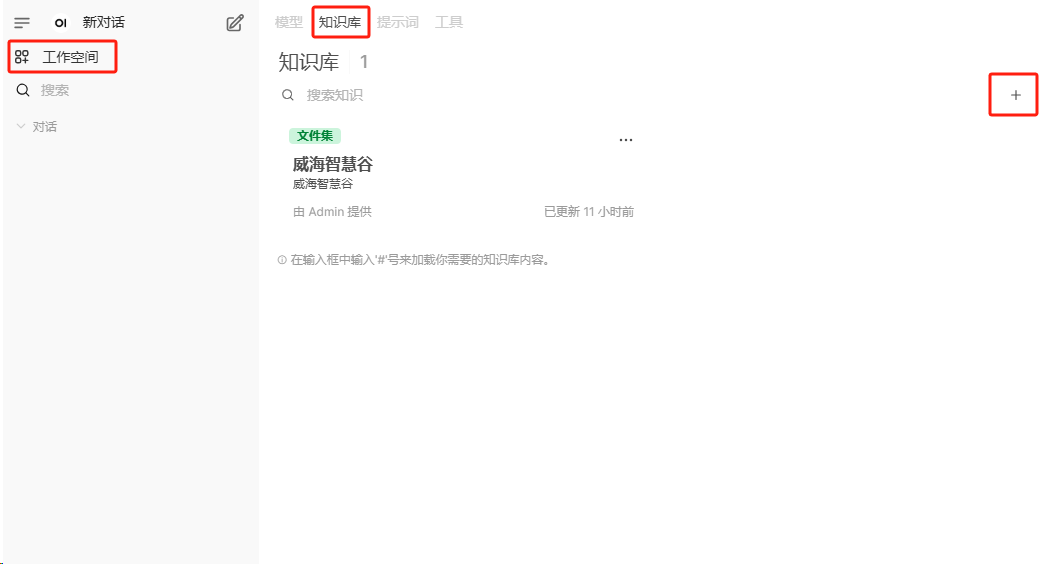
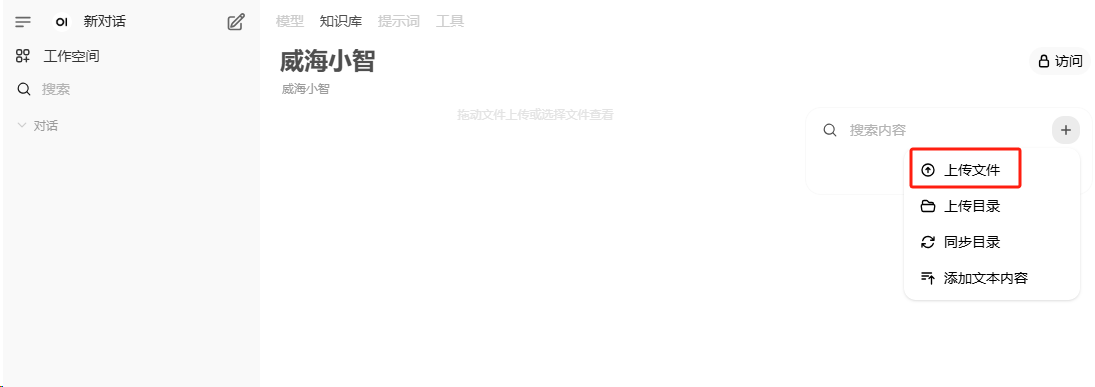
点击上传文件,建议的文件类型为markdown,使用 #### 进行段落区分,如果保存知识库出错,那是因为没有设置正确的语义向量模型
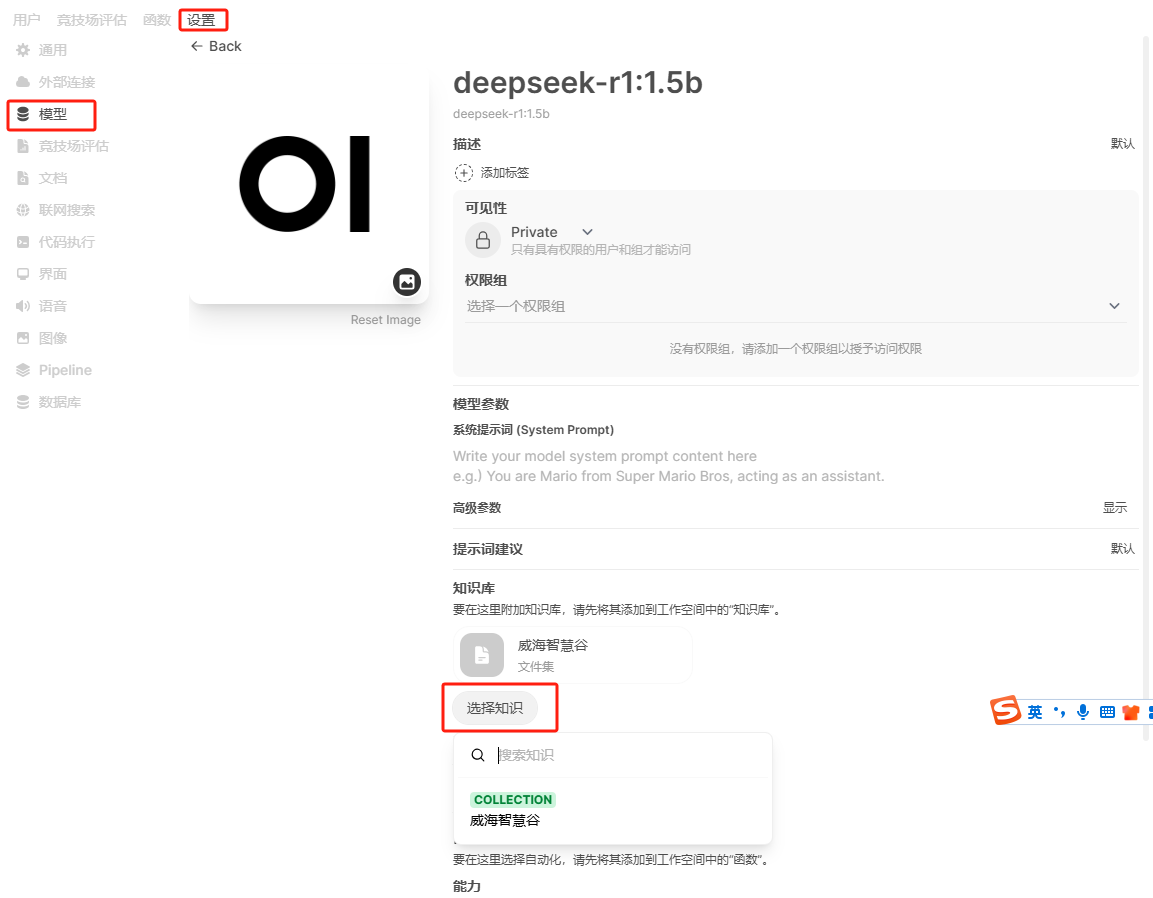
为模型关联知识库,或者在聊天界面使用 # 引用知识库
在聊天界面使用# 引用知识库
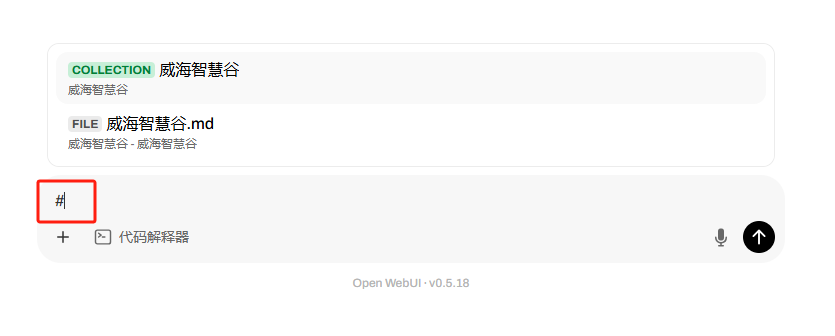
那我们就可以开始体验deepseek能力啦,来看看deepseek静静的装B
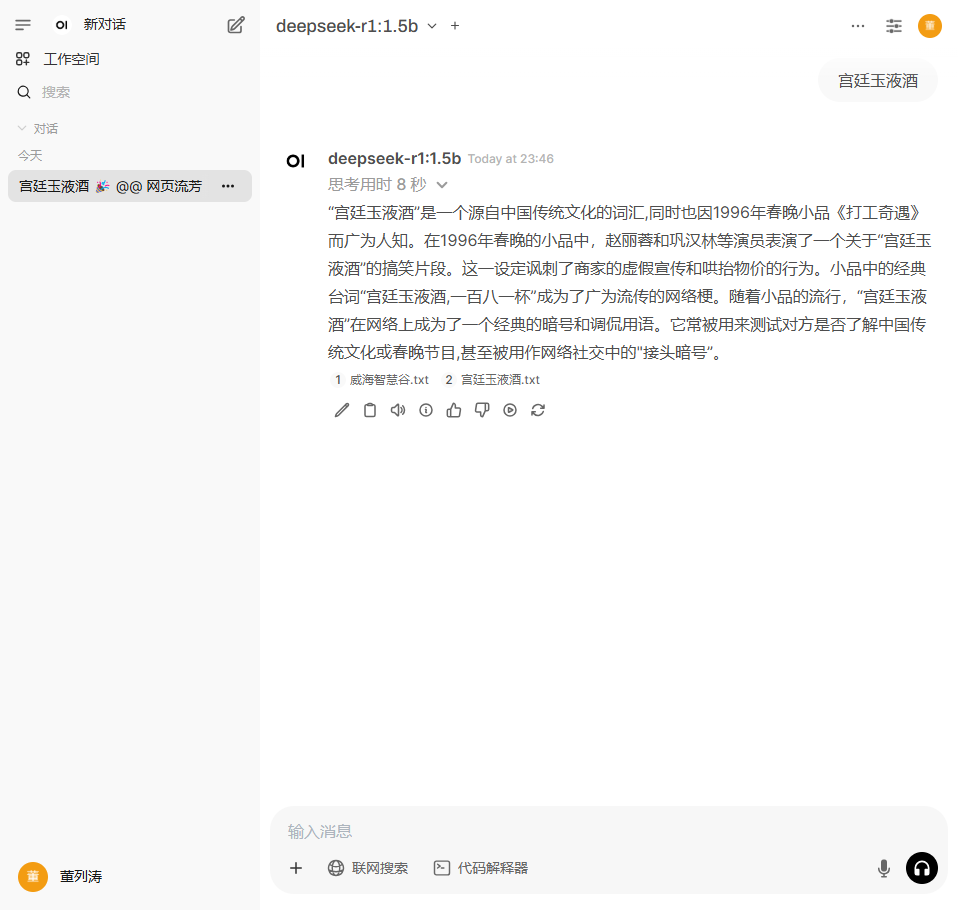
deepseek和dify环境搭建
dify是一个用于构建AI应用的模型编排软件,开箱即用,可以通过拖拉拽的形式,快速组合出一个AI应用,支持接入各厂商的云上模型,也支持接入本地ollama引擎运行的模型。
准备工作
- 需要魔法:https://iovhm.com/book/books/cee63/page/9872e
- 镜像代理:https://iovhm.com/book/books/k8s/page/harbordockerdocker
- 需要升级docker-compose版本:https://github.com/docker/compose/releases
- 安装ollama并下载模型:https://iovhm.com/book/books/bbcbf/page/deepseek
- 下载dify源代码:https://github.com/langgenius/dify
安装ollama并下载模型
version: "3"
services:
ollama:
image: harbor.iovhm.com/hub/ollama/ollama:0.5.12
container_name: ollama
restart: always
privileged: true
ports:
- "11434:11434"
volumes:
- ./ollama:/root/.ollama
# deploy:
# resources:
# reservations:
# devices:
# - driver: nvidia
# capabilities: [gpu]
# count: all
networks:
- vpclub-bridge
# 下载最少2个模型
# ollama pull deepseek-r1
# ollama pull bge-m3
下载dify源代码,进入到docker目录,修改被墙的docker镜像地址使用魔法地址
下载到源代码后,进入到docker目录,打开docker-compose.yaml,里面总共有26个服务,将镜像地址修改为私有仓库。如果并不打算二次开发和在服务器运行,只需要将docker目录上传到服务器,不需要把dify的所有源代码全部上传。
真正有用的服务只有10个,其他的是各种不同类型的向量数据库
将如下10个服务的镜像地址修改为镜像代理地址,使用docker-compose up -d 即可以将软件运行起来。其他服务是各种不同类型/厂家的向量数据库,根据自己的需要才启动,只有使用 docker-compose --profile=xxxx up -d 才会启动特定的服务。不用担心启动了太多的服务。
为了保持和官方版本升级时候的兼容性,不建议直接修改docker-compose.yaml,比喻把镜像下载回来了重命名一下。
- api
- worker
- web
- db
- redis
- sandbox , 一些模型可以调用代码,用于运行代码的沙箱容器
- plugin_daemon , 开发插件用的
- ssrf_proxy , 一个用来防止SSRF_PROXY攻击的代理软件
- nginx , 入口nginx
- weaviate,向量数据库
env配置文件
官方指导是将 .env.example 复制一个后改名为 .env , 但是需配置项太多,从头看到尾很需要时间,在此我摘抄了一个极简的 .env ,实际上不提供任何 .env文件,也可以运行。如果你的默认的80和443端口被占用,那就需要提供 .env 进行配置更改。
官方文档:https://docs.dify.ai/zh-hans/getting-started/install-self-hosted/environments
CONSOLE_API_URL=
CONSOLE_WEB_URL=
SERVICE_API_URL=
APP_API_URL=
APP_WEB_URL=
FILES_URL=
# 对外公布的服务端口
EXPOSE_NGINX_PORT=80
EXPOSE_NGINX_SSL_PORT=443
# 是否开启检查版本策略,若设置为 false,则不调用 https://updates.dify.ai 进行版本检查。
# 由于目前国内无法直接访问基于 CloudFlare Worker 的版本接口,
# 设置该变量为空,可以屏蔽该接口调用
CHECK_UPDATE_URL=
# 向量数据库配置
VECTOR_STORE=weaviate
# Weaviate 端点地址,如:http://weaviate:8080
WEAVIATE_ENDPOINT=http://weaviate:8080
# 连接 Weaviate 使用的 api-key 凭据
WEAVIATE_API_KEY=WVF5YThaHlkYwhGUSmCRgsX3tD5ngdN8pkih
接入ollama并添加模型
进入dify后,点击右上角自己的用户名图标,点击设置,进行模型供应商接入
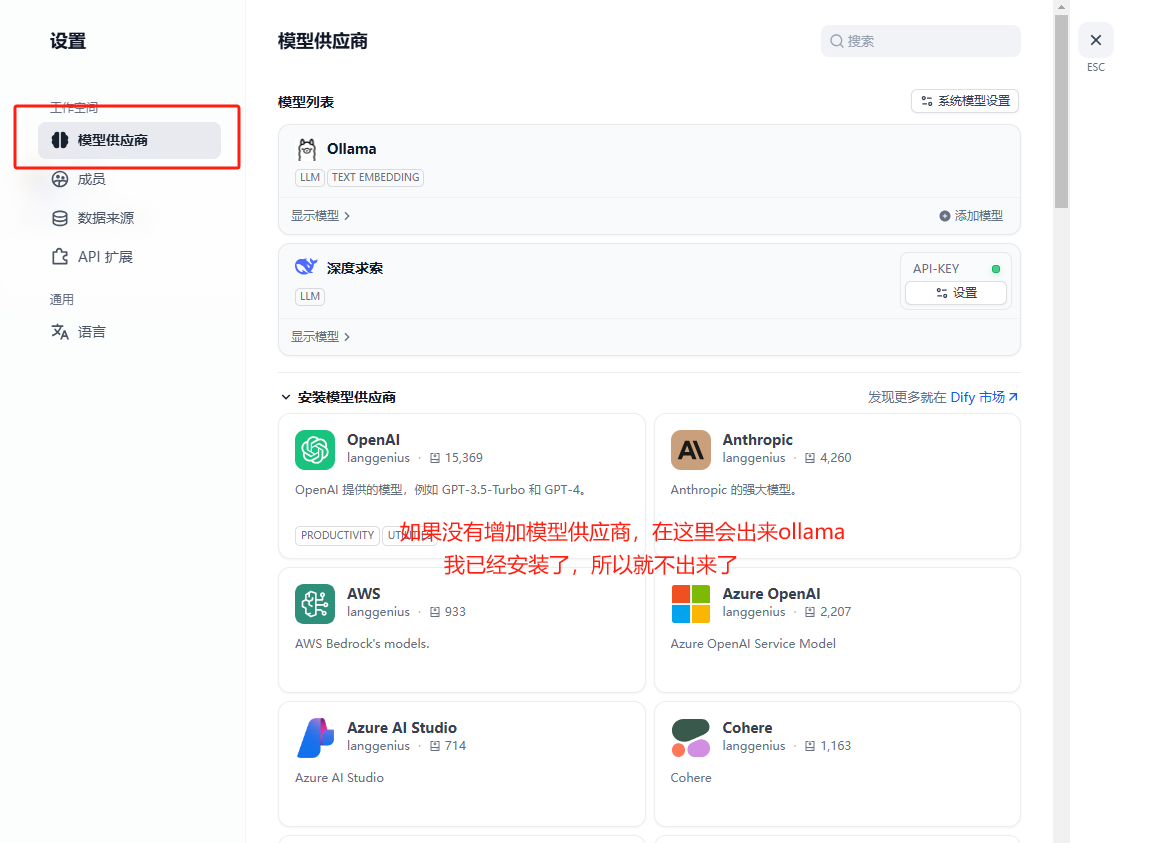
查看已经增加的模型
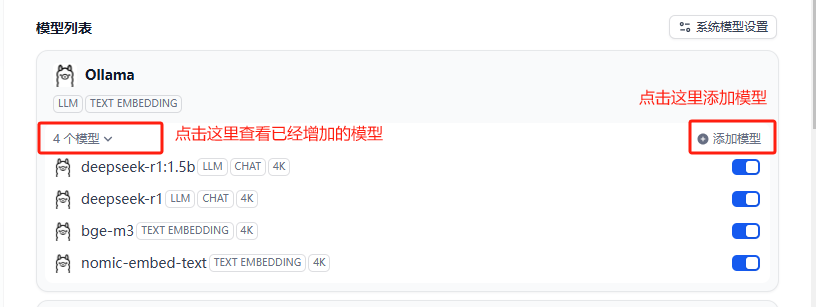
增加模型,需要增加2个模型,一个是LLM模型,一个是Text Embeding模型,模型需要先到ollama下载好。
- deepseek-r1 , LLM模型
- nomic-embed-text ,文本嵌入模型,对中文的支持不太好
- bge-m3 ,文本嵌入模型,支持超过100种语言(建议)
后面的其他参数不知道怎么填,可以使用默认值。
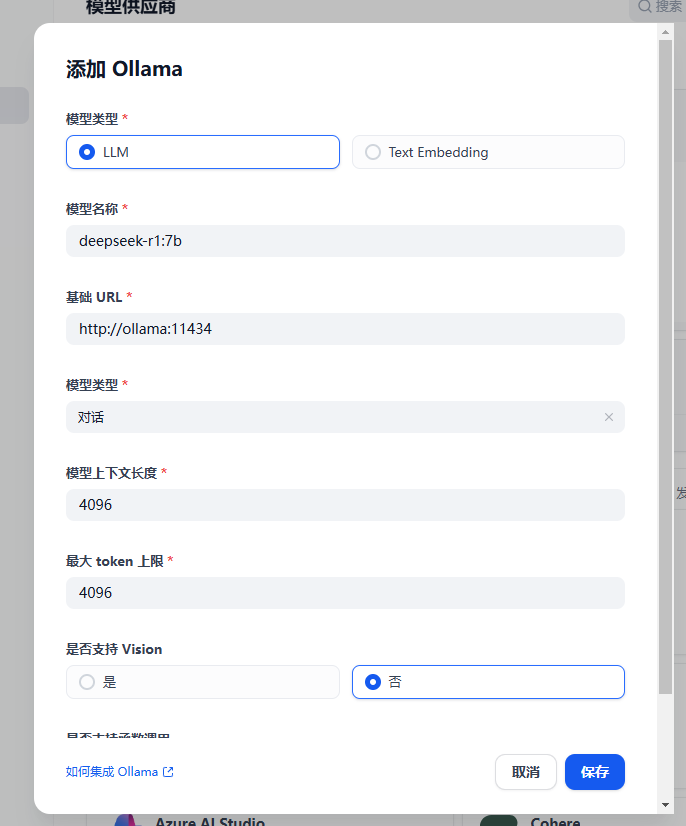
创建知识库
可以使用word、markdown等软件将编写好文档后上传,文档要求是需要有分段关系,既标题->正文,有一定的逻辑关系,如果你不介意,可以用wps ai将文章内容更正得更正式。
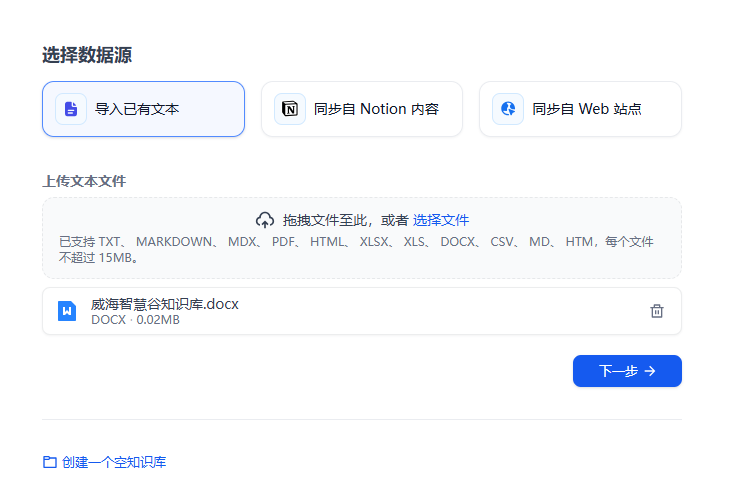
创建一个新的知识库,并上传文档
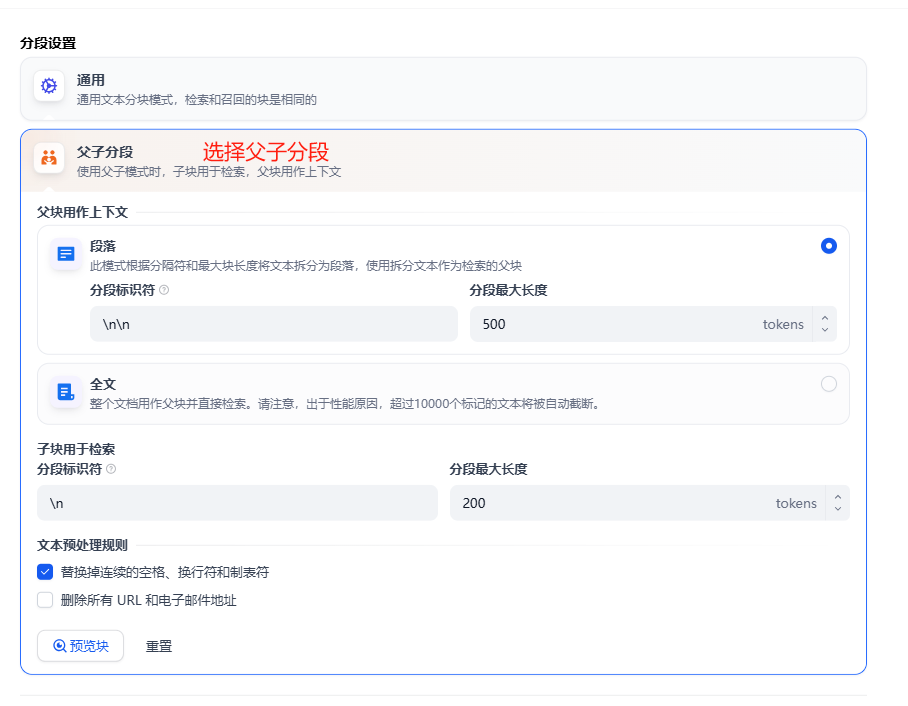
对知识库进行设置
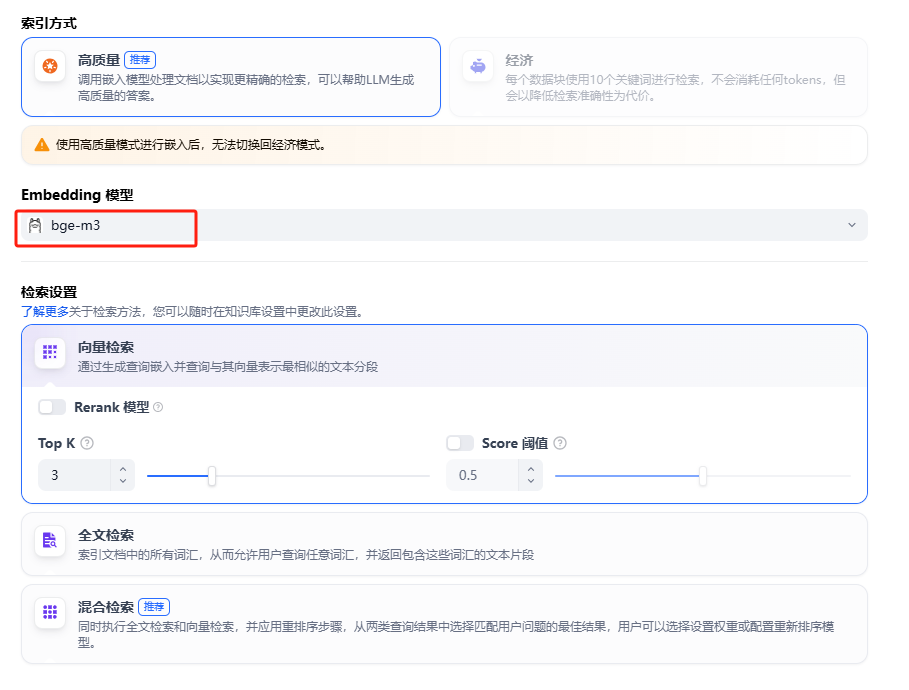
设置检索方式和嵌入式文本模型
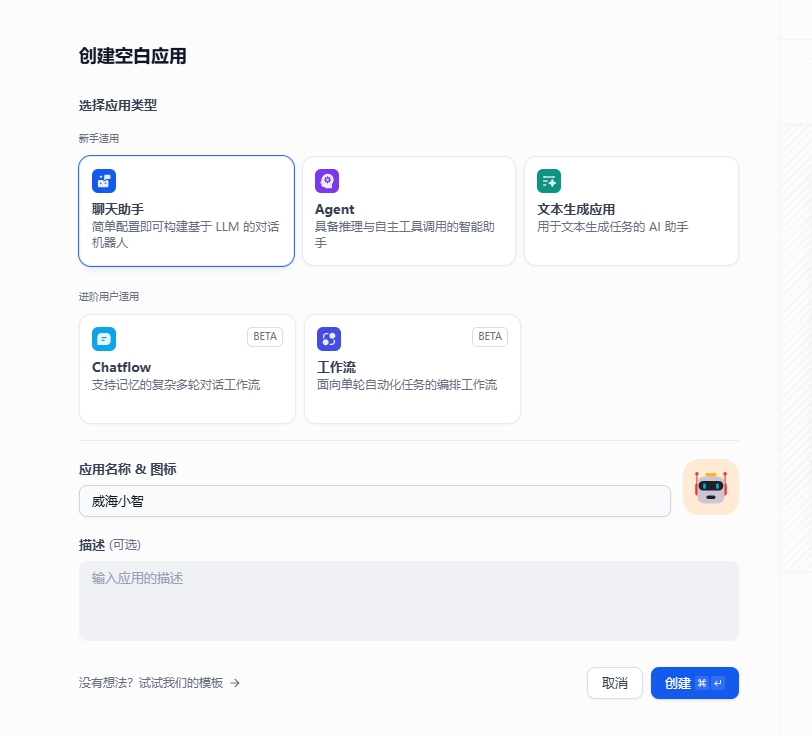
创建一个新的应用
在工作室标签下,选择创建空白应用,选择你要创建的应用类型
对应用进行设置
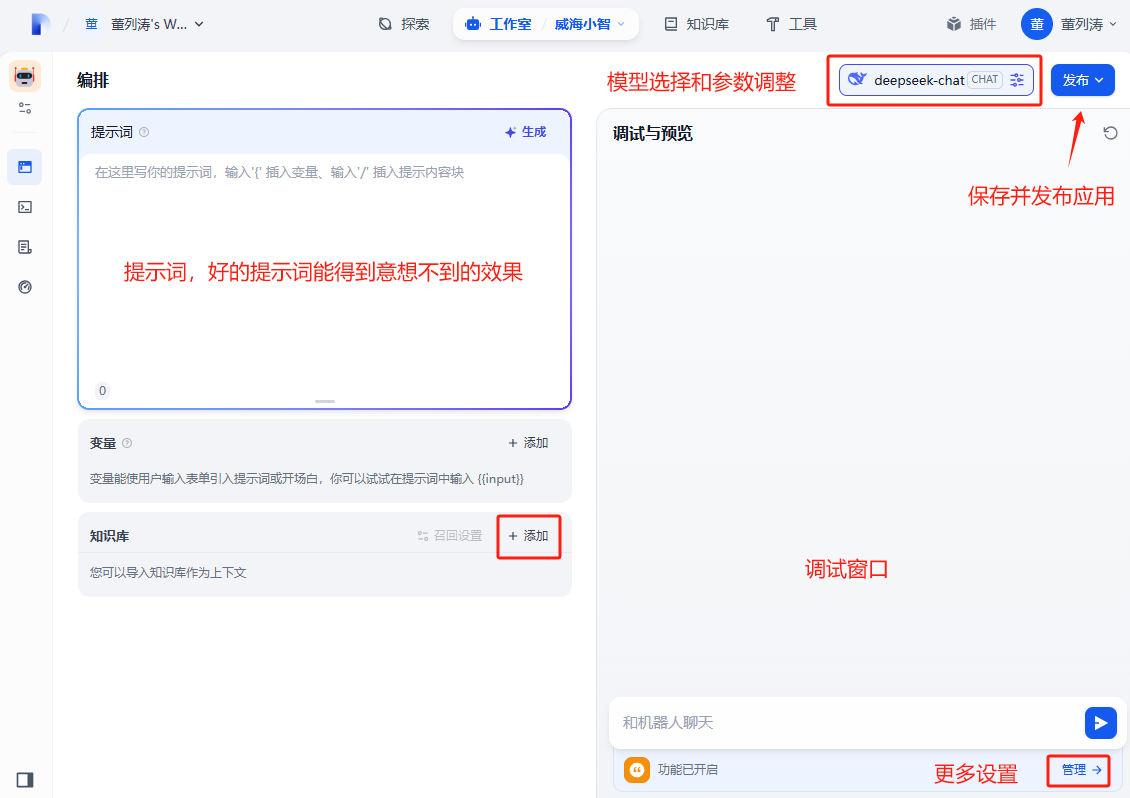
应用的更多设置,比喻开场白,连续提问等。
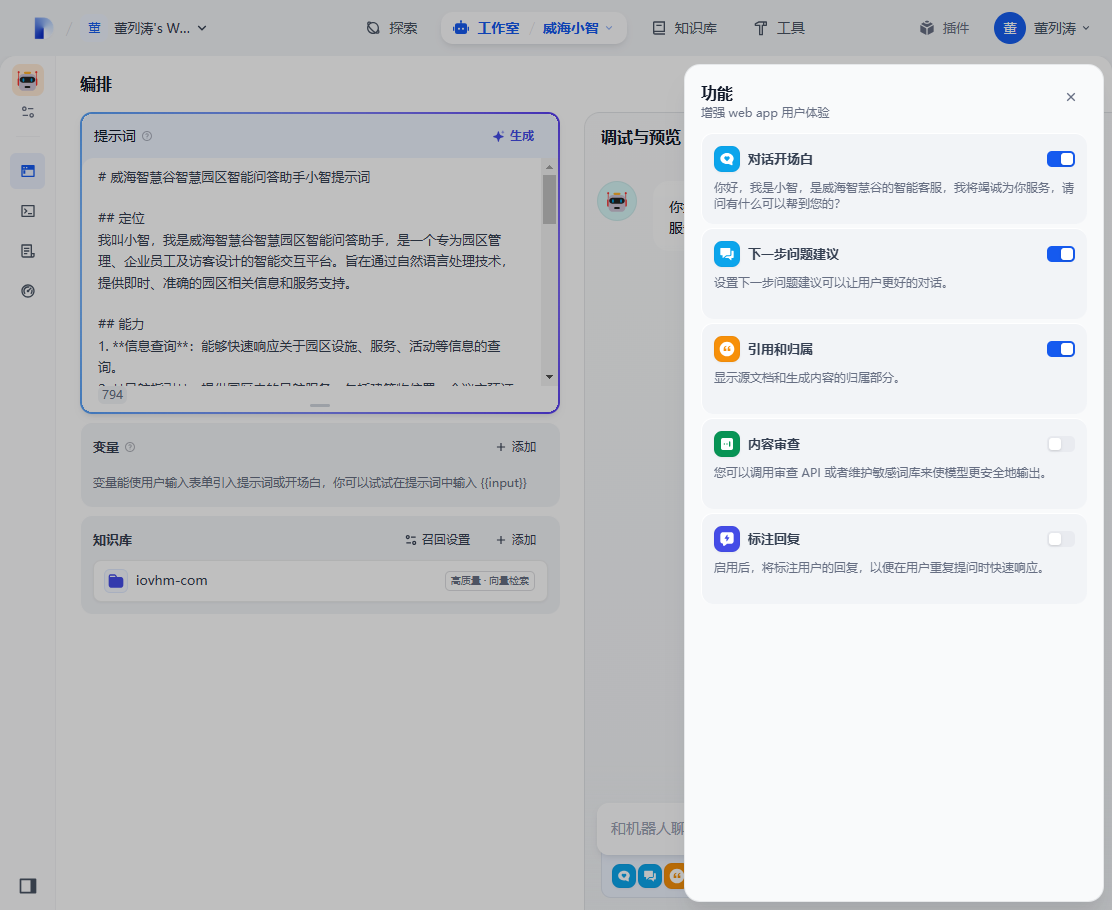
调试体验一下
此时AI的回复特别生硬,需要修改提示词。
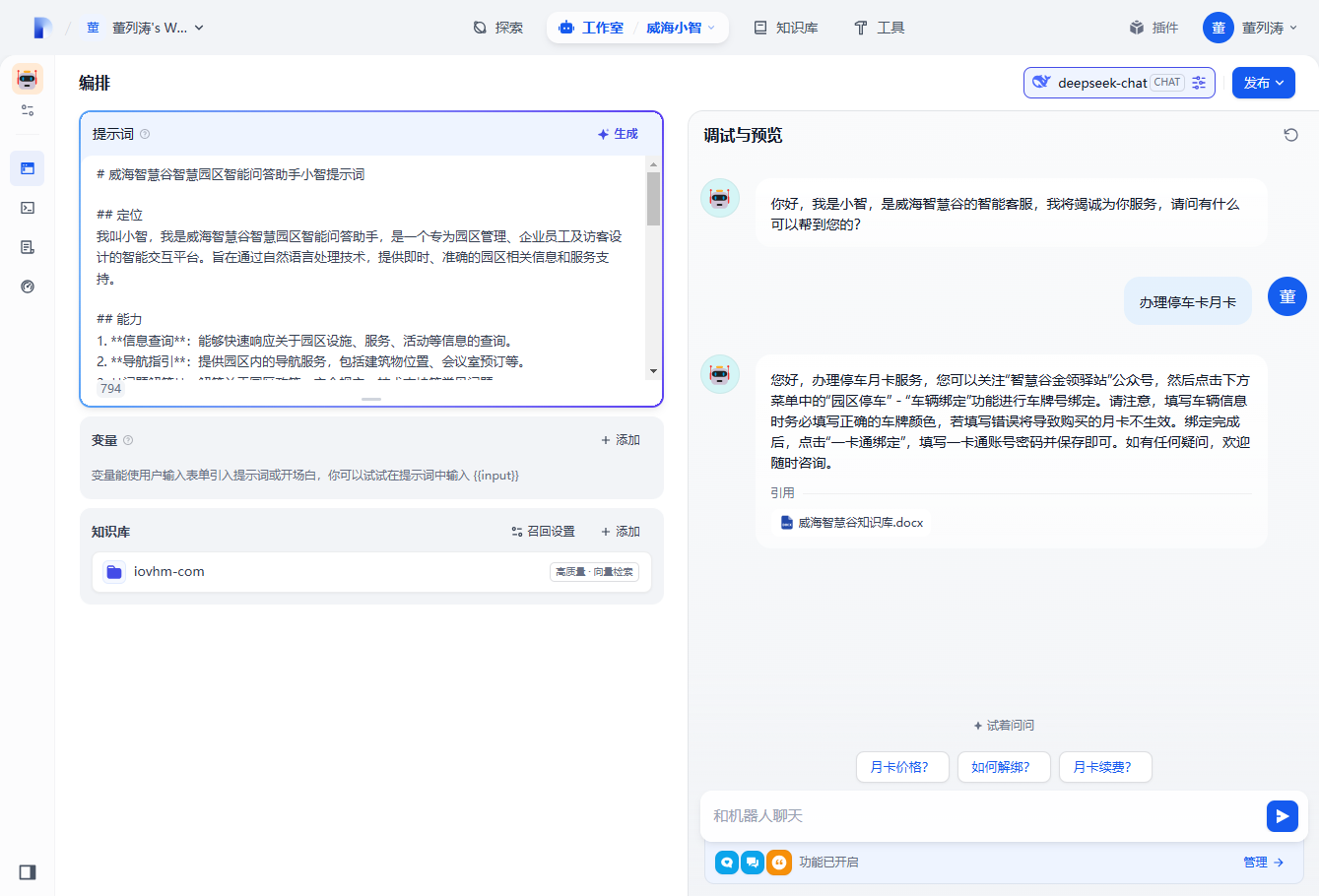
提示词设置
一个好的提示词,对AI的影响非常大,deepseek帮助文档给出了一些参考建议
https://api-docs.deepseek.com/zh-cn/prompt-library/
还是不知道怎么写?那我们蒸馏一下,让deepseek帮忙生成一个.
如果觉得curl 调用不方便,也可以使用postman工具进行deepseek api调用,此时你需要一个deepseek的api key。
curl --location 'https://api.deepseek.com/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer sk-xxxxxxxxxxxxxxxx' \
--data '{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "你是一位大模型提示词生成专家,请根据用户的需求编写一个智能助手的提示词,来指导大模型进行内容生成,要求:1. 以 Markdown 格式输出\n 2. 贴合用户需求,描述智能助手的定位、能力、知识储备\n 3. 提示词应清晰、精确、易于理解,在保持质量的同时,尽可能简洁\n 4. 使用清晰、简洁的语言回复提问,确保用户容易理解\n 5.使用友好且专业的语气与用户交流,如“您好,关于您的这个问题,我可以为您详细解答。"},
{"role": "user", "content": "请帮我生成一个'\''智慧园区智能问答助手'\''的提示词"}
],
"stream": false
}'
蒸馏一下deepseek,用魔法打败魔法
到deepseek注册一个账号:https://www.deepseek.com/

创建一个api key
充值10块钱,就可以用啦。顺便吐槽一下,老说程序员工资太高,但是你们看到别人背后的持续学习成本了吗?5-10年就技术更新一次,知识全部作废,熬夜写文档,买key,买机器,这些成本你们算过吗?你们某些行业,一本小破书就可以用到退休。就别整天BBB了。

看下deepseek蒸馏生成的提示词,我们此基础上稍微修改下。
# 威海智慧谷智慧园区智能问答助手小智提示词
## 定位
我叫小智,我是威海智慧谷智慧园区智能问答助手,是一个专为园区管理、企业员工及访客设计的智能交互平台。旨在通过自然语言处理技术,提供即时、准确的园区相关信息和服务支持。
## 能力
1. **信息查询**:能够快速响应关于园区设施、服务、活动等信息的查询。
2. **导航指引**:提供园区内的导航服务,包括建筑物位置、会议室预订等。
3. **问题解答**:解答关于园区政策、安全规定、技术支持等常见问题。
4. **服务预约**:协助用户进行会议室预订、设备租赁等服务预约。
5. **反馈收集**:收集用户对园区服务的反馈和建议,帮助园区管理方优化服务。
## 知识储备
1. **园区信息**:包括园区地图、设施介绍、服务项目等。
2. **政策法规**:园区相关的政策、规定及安全指南。
3. **技术支持**:常见技术问题的解决方案和操作指南。
4. **服务流程**:各类服务的预约流程、使用指南等。
## 交互示例
- **用户**:最近的咖啡厅在哪里?
- **助手**:贵宾,您好,园区内最近的咖啡厅位于A栋一楼,营业时间为早上8点到晚上8点。您可以通过园区导航系统找到具体位置。希望我的服务能帮助您。如有任何问题,欢迎随时咨询。
- **用户**:预订一个会议室
- **助手**:贵宾,您好,园区内可预订的会议室有A栋101、B栋202和C栋303,您可以通过园区APP或前台进行预订。希望我的服务能帮助您。如有任何问题,欢迎随时咨询。
- **用户**:...漏水...灯不亮了...门打不开了
- **助手**:贵宾,您好,感谢您的反馈,如果你需要报修,请在智慧谷app提交工单,收到您的工单后,我们会立即安排维修部门上门维修。希望我的服务能帮助您。如有任何问题,欢迎随时咨询。
## 提示词
- **查询信息**:请告诉我关于...
- **导航指引**:我需要找到...
- **问题解答**:关于...的问题,我需要帮助。
- **服务预约**:我想预订...
- **反馈收集**:我有一些建议/反馈...
再来体验一下
此时AI回复已经很客气啦!
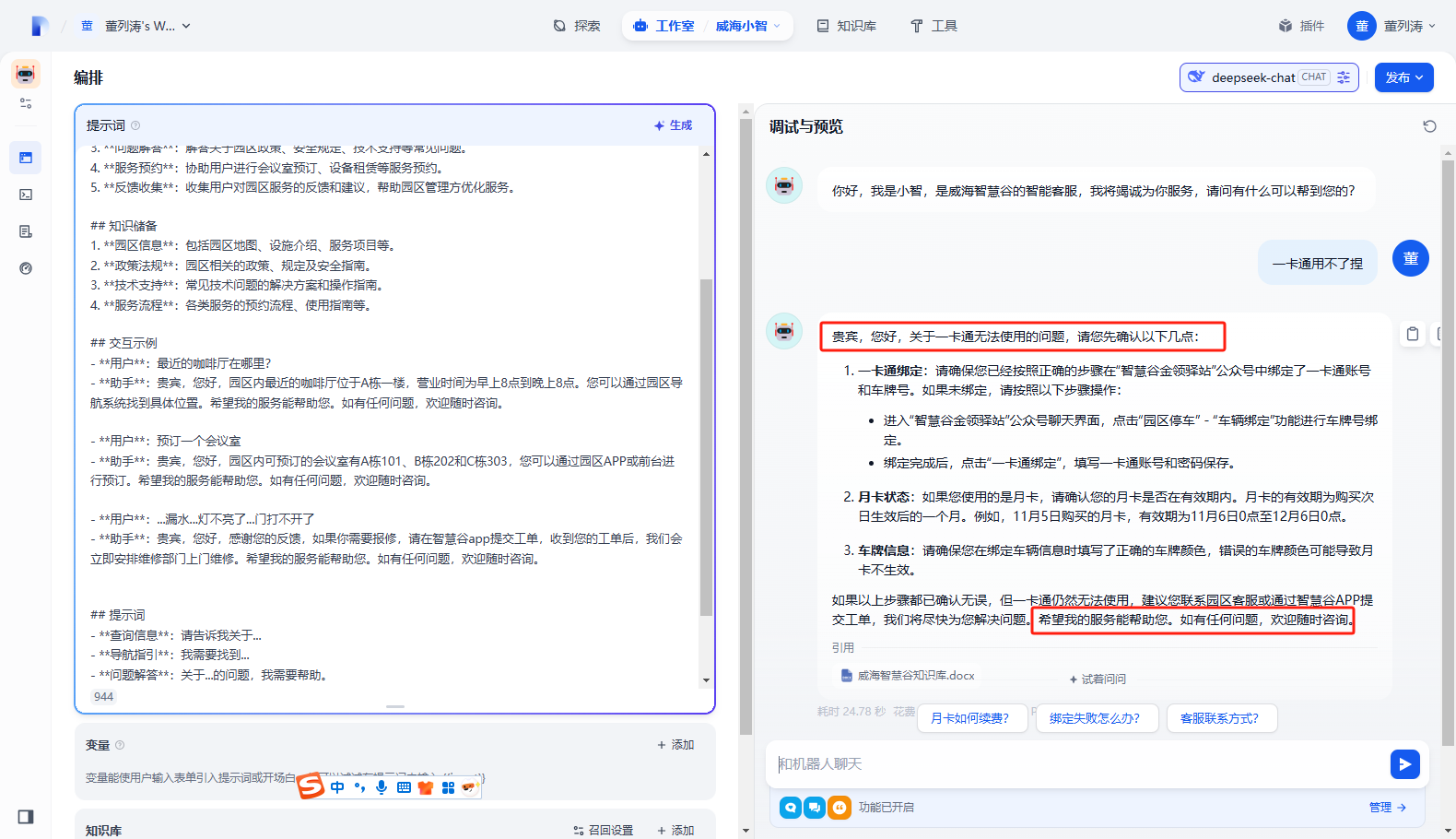
记得要点右上角的发布按钮哦。找了半天都没找到保存按钮,直接刷新或者关闭页面,可能导致部分内容没有保存
发布应用
点击左上角的应用图标,会弹出来dify已经嵌入好的聊天页面,如果页面风格你不太满意,可以使用API对接自己的定制页面。
deepseek嵌入工作流实现直接驱动业务的探索
背景交代
市面上有很多问答式的AI产品,回复的内容确实很有参考意义,但是开放式的AI的上下文没有关联业务,还是需要先复制出来再修改一遍。
不过研发人员的ide插件可靠度就很高了,基本上都能运行。
那么问题来了,客户他只有一个一次性的需求,还需要研发吗,特别是领导们喜欢提稀奇古怪的问题,一通改下来,最后说还是第一个好,浪费时间还不给钱
生成式大屏逻辑分析
- 分析用户的输入,例如统计今天成交了多少订单(实际业务肯定比这个要求复杂),不过我们今天是入门尝试,暂不选择很复杂的例子
- 从知识库查找业务上下游的表、字段关系
- 将用户输入与表关系(业务上下文),全部传递给deepseek
- 使用deepseek生成sql语句,驱动http接口执行动态SQL(不安全,不可靠)
- 那分两步进行,先返回SQL语句,再到大屏设计器里面去绑定语句,这样的话客户自己也可以定制一些大屏了。
开整
在dify里面创建一个工作流应用
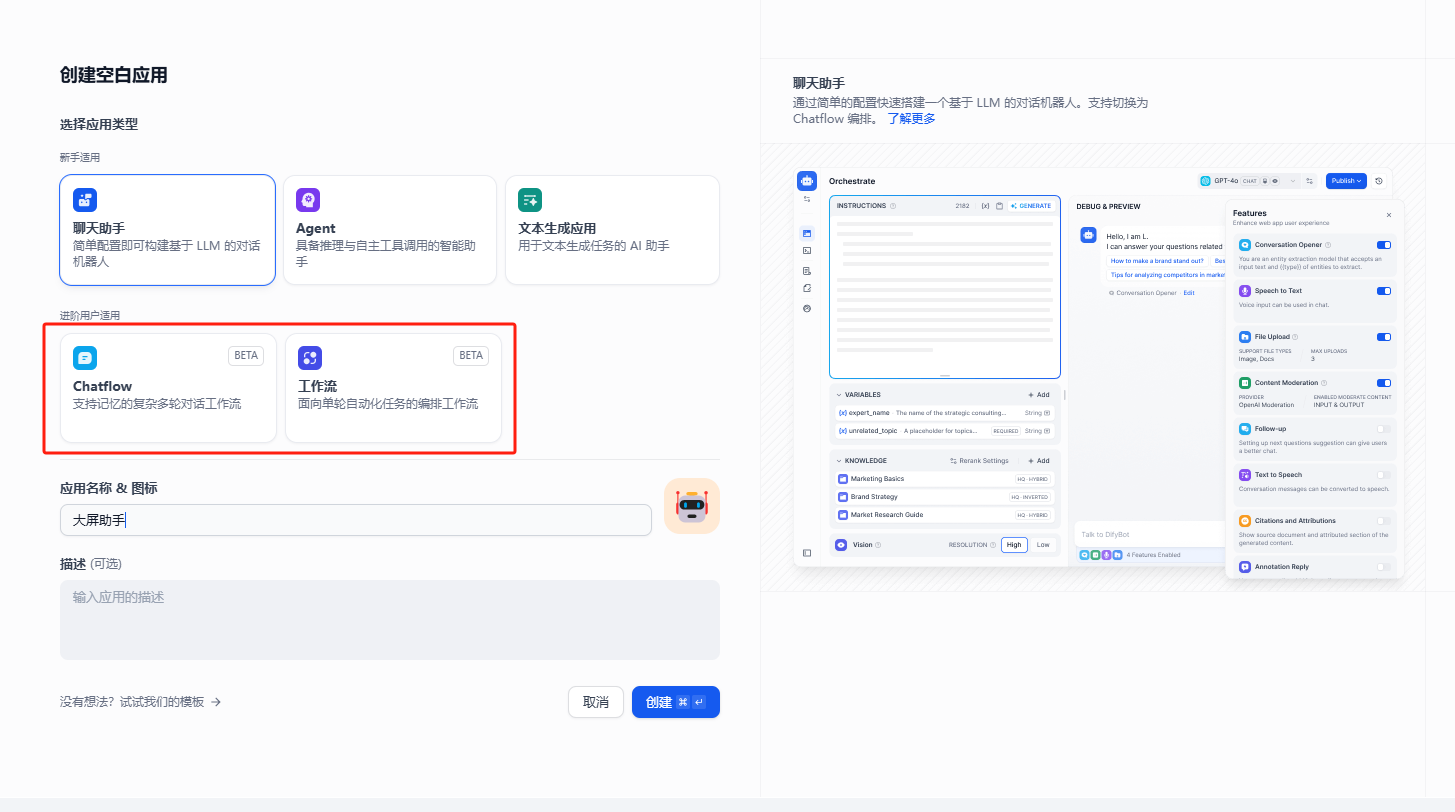
在工作流面板上右键,增加各种节点
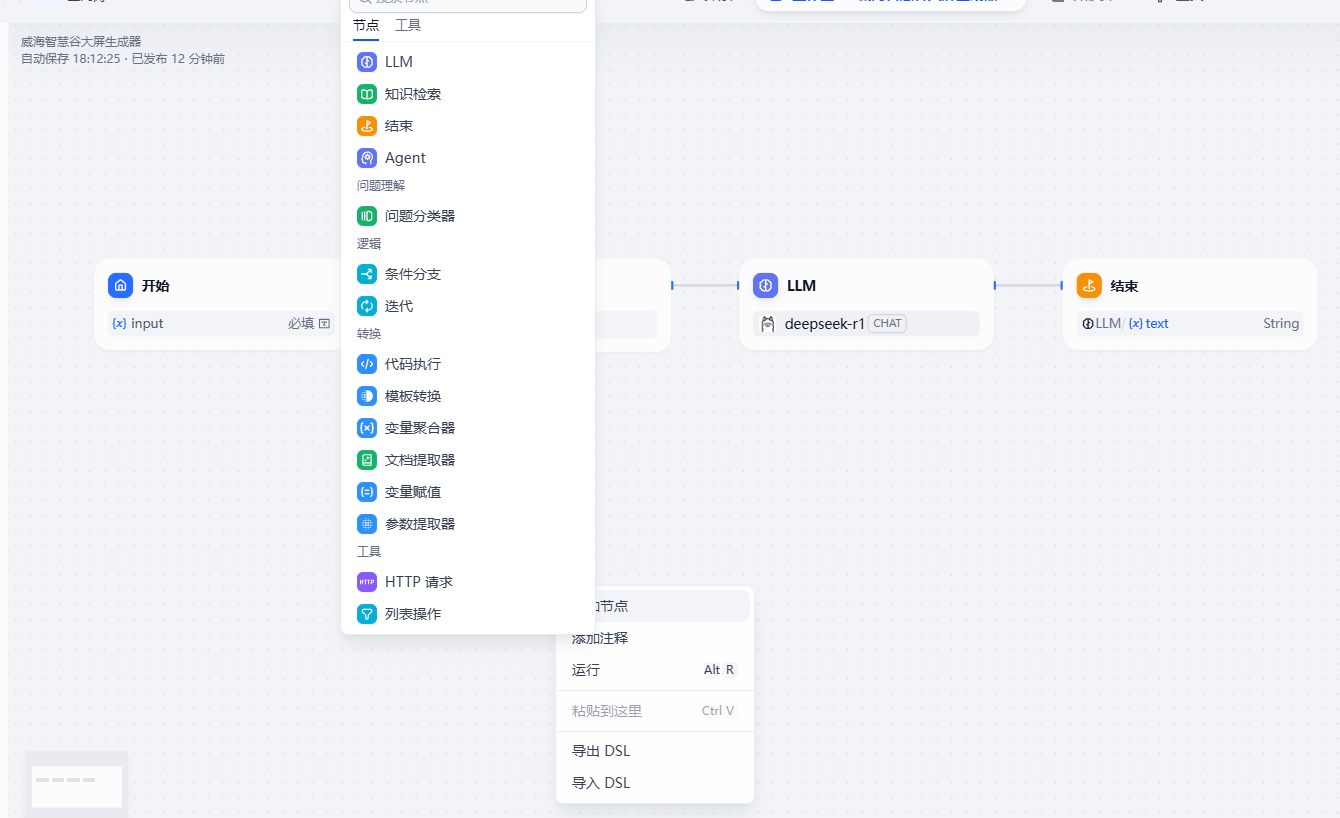
如我们前面提到的,我们总共需要2个节点来完成,在加上一个开始和一个结束,总共需要四个节点
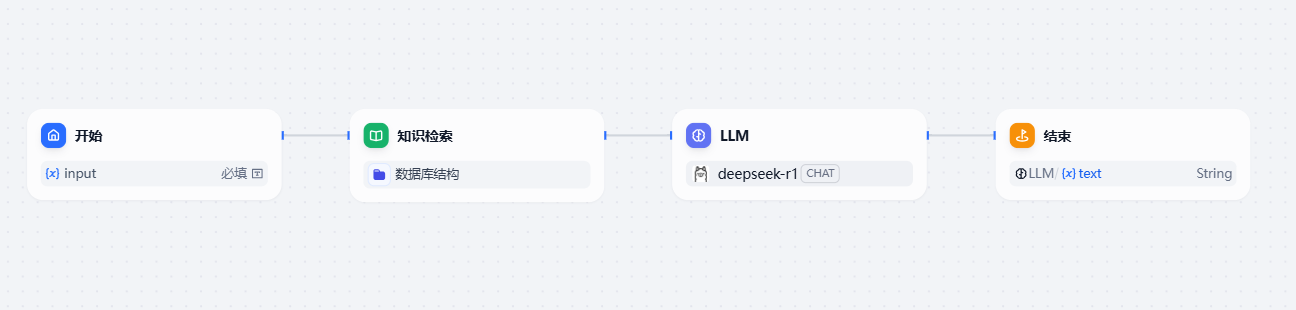
选中每一种不同类型的节点,都有这个节点的单独属性设置。
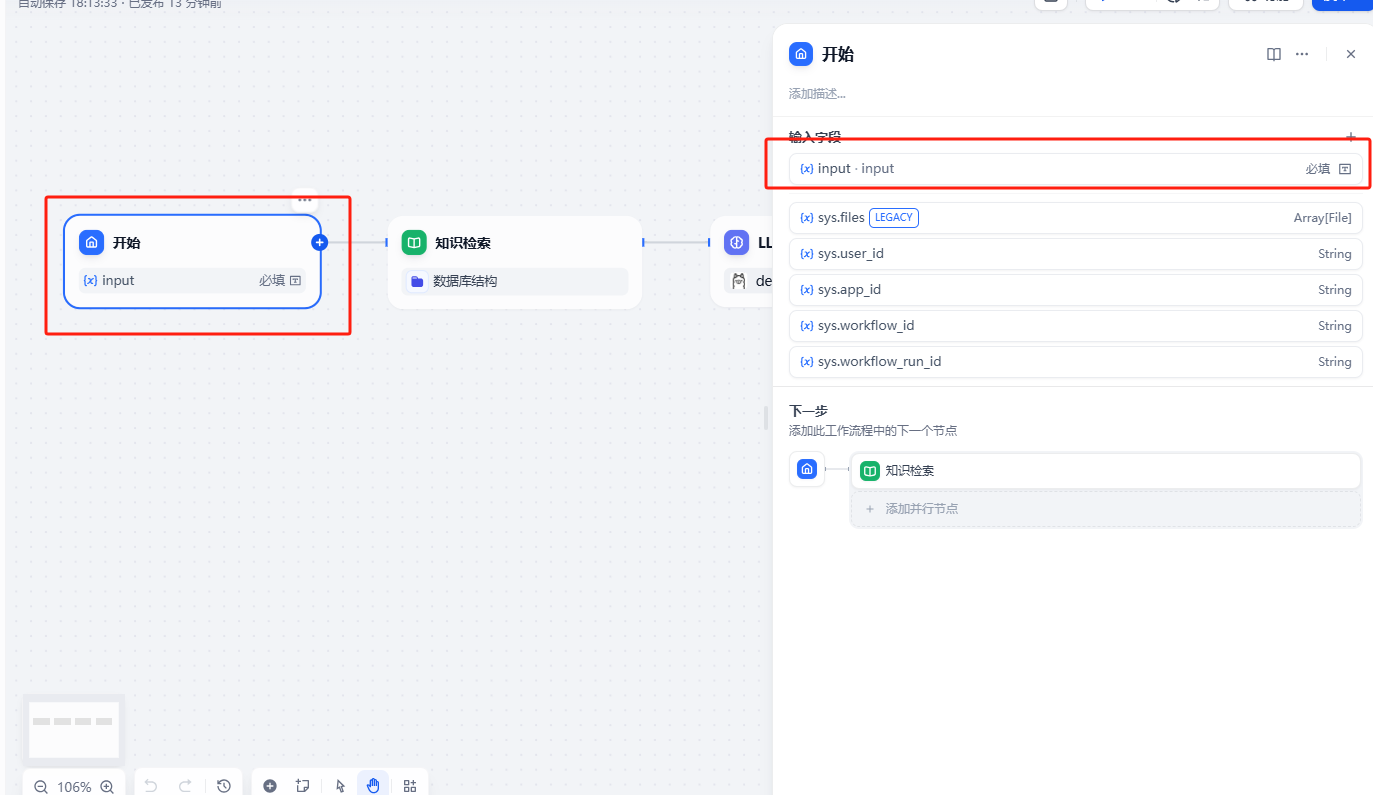
开始节点,增加一个输入字段,接受外部的输入
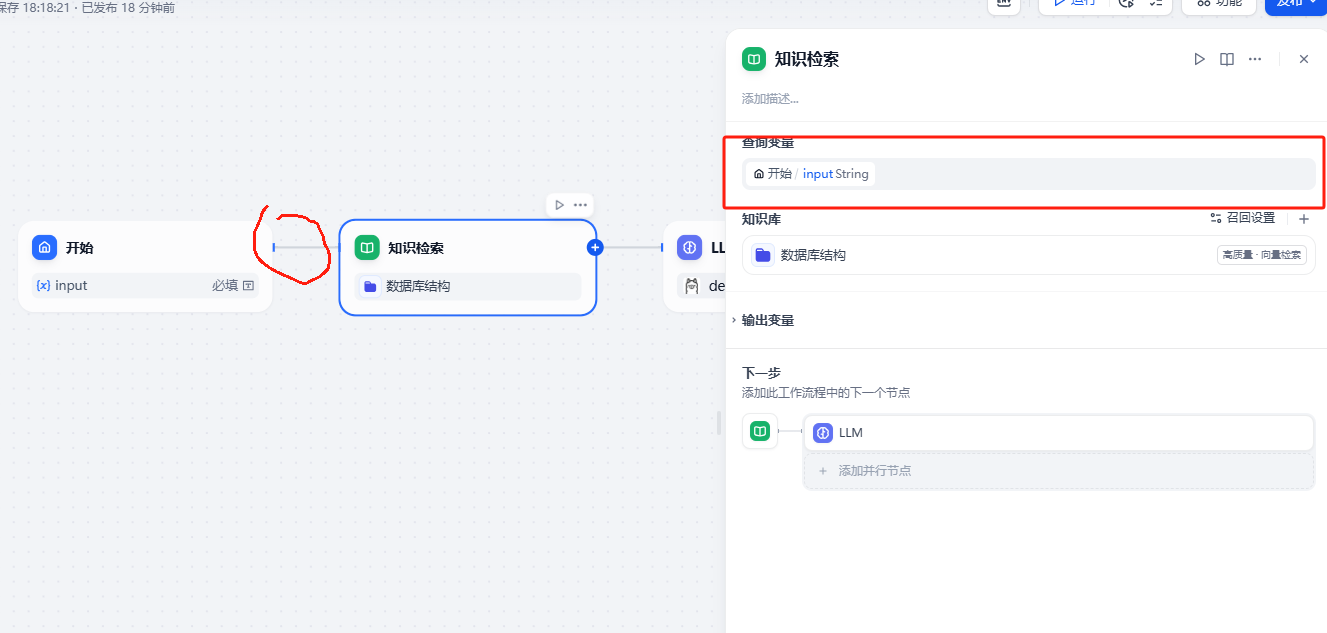
增加一个知识库检索节点,拖拽建立关系,并接受上一个节点的输出,作为本节点的输入
创建一个LLM模型,将知识库的输入绑定的LLM的上下文
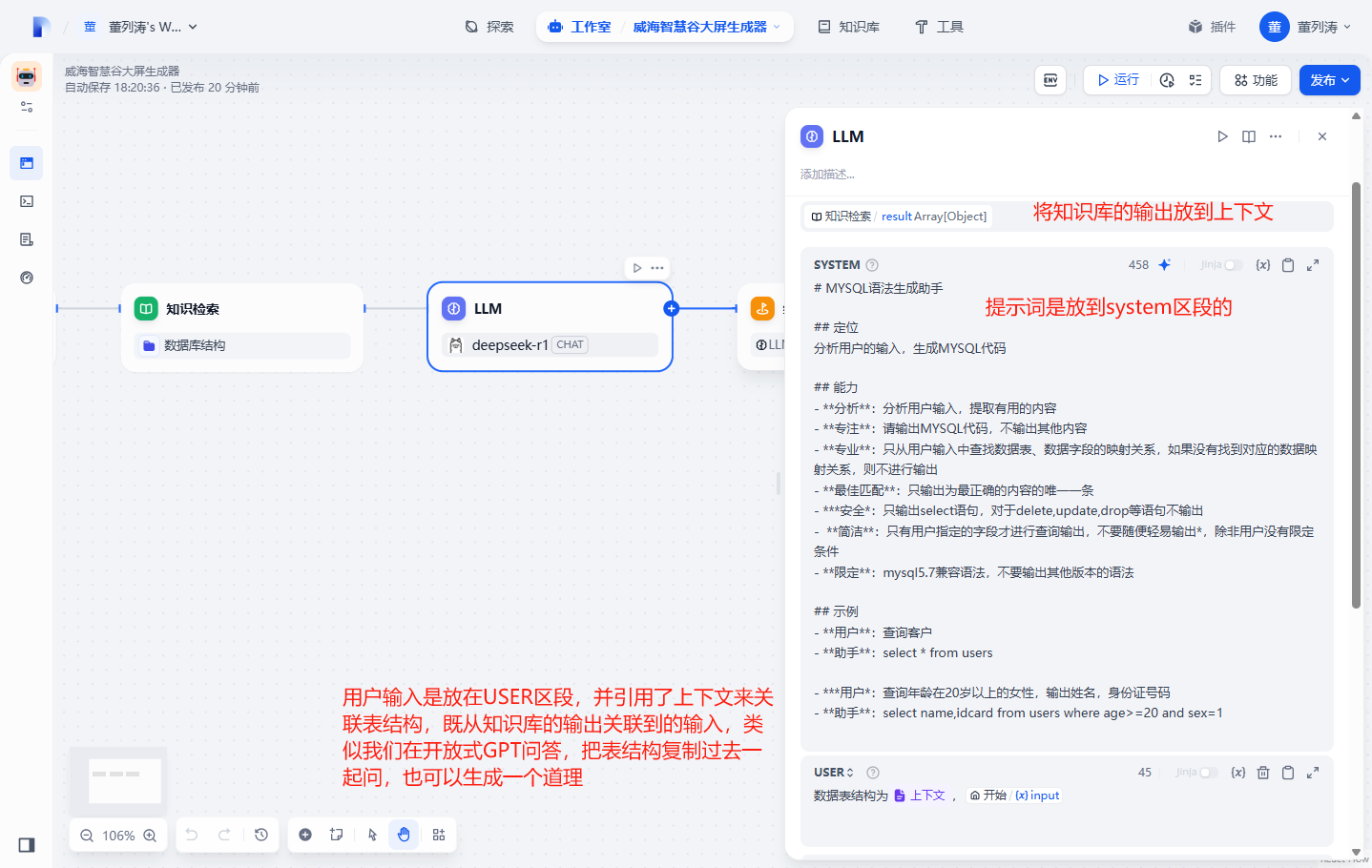
重点,提示词和知识库
- 提示词的重要性我们前面讲过了,可能需要反复尝试
# MYSQL语法生成助手
## 定位
分析用户的输入,生成MYSQL代码
## 能力
- 分析用户输入,提取有用的内容
- 请输出MYSQL代码,不输出其他内容
- 只从用户输入中查找数据表、数据字段的映射关系,如果没有找到对应的数据映射关系,则不进行输出
- 只输出最正确内容的唯一一条
- 只输出select语句,对于delete,update,drop等语句不输出
- 只有用户指定的字段才进行查询输出,不要随便轻易输出*,除非用户没有限定条件
- 限定mysql5.7兼容语法,不要输出其他版本的语法
## 示例
- **用户**:查询用户
- **助手**:select * from users
- **用户**:查询年龄在20岁以上的女性用户,输出姓名,身份证号码
- **助手**:select name,idcard from users where age>=20 and sex=1
- 引用的业务内容上下文,也就是知识库,这个时候就需要精心编辑了,如果你有更好的更简洁的办法,请告诉我,例如直接导入sql表结构
为了验证确实采纳了业务规则,而不是通用回答,我特意把表名增加了前缀vp_xxx
# 表名:vp_xxx_user(用户表)
## 字段:
- id(用户ID,主键)
- name(用户名)
- email(用户邮箱)
- idcard(身份证)
# 表名:vp_xxx_order(订单表)
## 字段:
- order_id(订单ID,主键)
- user_id(用户ID,关联用户表)
- amount(订单金额)
- img_url(图片地址)
# 表名:vp_xxx_customer(客户表)
## 字段:
- id(用户ID,主键)
- name(用户名)
- email(用户邮箱)
- idcard(身份证)
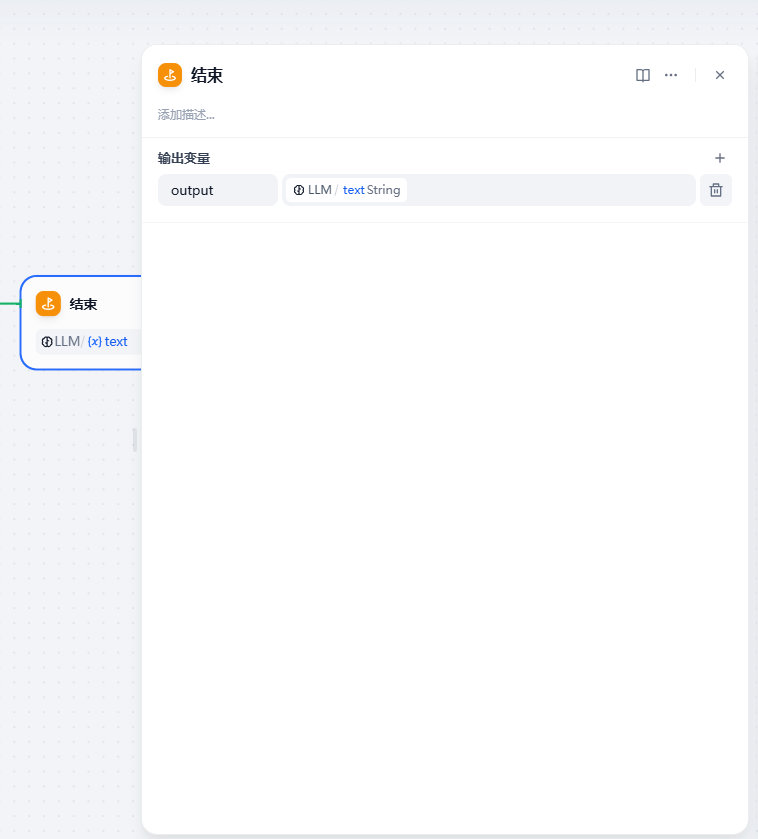
最后一个节点是结束节点,既把一串流程下来的结果输出。
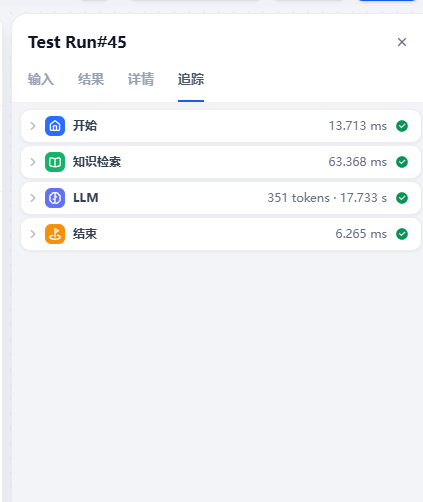
还可以追踪一下每一步的执行情况
验证一下
输入:查询所有年龄在20岁以上的客户,返回姓名和身份证。注意客户与用户的区别
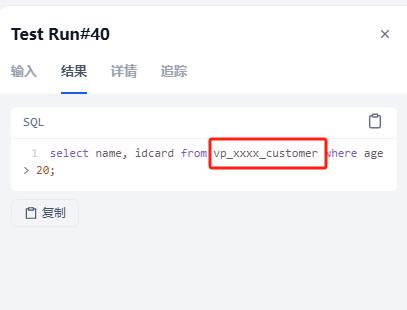
输入:查询所有年龄在20岁以上的用户,返回姓名和身份证。注意客户与用户的区别
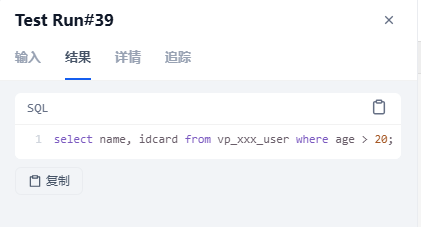
输入:查询2024年9月的物业合同。这个表在知识库并不存在,输出了错误的语句,提示词还需要调优
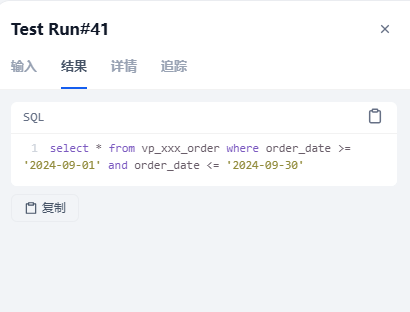
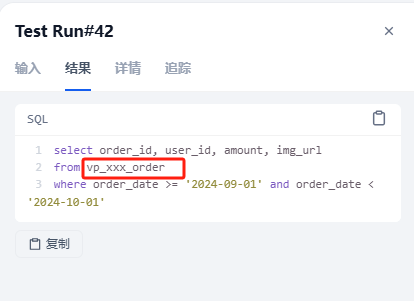
输入:查询2024年9月的订单,返回了正确的结果。
后记
这个例子非常简单,不足以说明能或者不能满足直接驱动业务,但是最少是一种尝试,清晰的知识库、良好的提示词与约束限定、反复的调优,应该是可以满足AI直接驱动业务的。
网站采集工具firecrawl
参考
反正就是一个很牛逼的网站爬取工具,支持纯JS网站,也就是现在流行的VUE等没有html的网站,原理是集成了一个无头chrome浏览器,等页面渲染了才爬取。
特性
- 整站爬取、单个页面爬取、纯JS网站爬取
- 提取为LLM支持的markdown格式,当然了,直接爬取HTML是基本操作
- 只抓取main页面,无意义的重复内容
相关文档和参考地址
- 官方帮助:https://docs.firecrawl.dev/introduction
- 网上的资料很多是V0版本的,但是现在firecrawl已经升级到V版本啦,而且v0版本将在2025年4月1日下线:https://docs.firecrawl.dev/v1-welcome
- github源代码地址:https://github.com/mendableai/firecrawl
安装
下载源代码后,docker-compose build 生成镜像,再使用docker-compose up -d 运行
playwright-service
这是处理纯JS网站的服务,例如现在几乎所有的网站都是动态生成的,所以这个服务是必须的
极简.env文件,其实不要也可以跑
# 核心配置
NUM_WORKERS_PER_QUEUE=8
PORT=3002
HOST=0.0.0.0
REDIS_URL=redis://redis:6379
REDIS_RATE_LIMIT_URL=redis://redis:6379
PLAYWRIGHT_MICROSERVICE_URL=http://playwright-service:3000/html
# 数据库及其他可选配置
USE_DB_AUTHENTICATION=false
API调用,现在GPT很强大,不懂的文GPT吧
- 整站爬取
curl -X POST http://localhost:3002/v1/crawl \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"url": "https://docs.firecrawl.dev",
"limit": 100,
"scrapeOptions": {
"formats": ["markdown", "html"]
}
}'
- 获取爬取状态、或者说是爬取的结果
curl -X GET http://localhost:3002/v1/crawl/<jobid>
- 抓取单个 URL
curl -X POST http://localhost:3002/v1/scrape \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"url": "https://docs.firecrawl.dev",
"formats": ["markdown", "html"]
}'
- 获取网站地图
curl -X POST http://localhost:3002/v1/map \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"url": "https://firecrawl.dev"
}'
``
- 执行搜索
```shell
curl -X POST http://localhost:3002/v1/search \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"query": "AI tools",
"limit": 5,
"scrapeOptions": {
"formats": ["markdown"]
}
}'
- 结构化数据
curl -X POST http://localhost:3002/v1/extract \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"url": "https://example.com",
"extract": {
"schema": {
"type": "object",
"properties": {
"title": {"type": "string"},
"price": {"type": "number"}
}
}
}
}'
- 批量抓取`
curl -X POST http://localhost:3002/v1/batch/scrape \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"urls": ["https://example1.com", "https://example2.com"],
"options": {
"formats": ["markdown"]
}
}'
deepseek提示词小技巧
提示词对模型的影响非常大,如果个人的写作习惯,描述的并不规范,建议大致意思写好后,放到wps使用更正式风格更正一下,或者放到其他AI让AI修正一下。
提示词虽然没有固定要求,但是根据实践,还是有一些格式可以借鉴的
- Role: 角色定位,明确模型扮演的身份和职业。例:自动化测试脚本编写专家
- Goals: 目标和任务。 例:根据用户需求,使用python和curl两种代码生成测试脚本,放在
XML标签内的内容是你的知识储备 - Constrains: 约束条件,明确禁止、限制或应该避免的内容。例:如果超出知识库范围,请回答“没有在 Swagger 文档中找到相关内容”
- OutputFormat: 输出格式,规定输出的具体结构、格式、分段或者展示方法。例:正式回复时,增加固定内容:“经过查找 Swagger 文档,为你生成测试脚本如下:”
- Example: 示例
- Optional: 额外注意事项
。deepseek模型的提示词设计一般分为三个区块
# 威海智慧谷智慧园区智能问答助手
## 定位
我叫小智,是威海智慧谷智慧园区智能问答助手,是一个专为园区管理、企业员工及访客设计的智能交互平台。旨在通过自然语言处理技术,提供即时、准确的园区相关信息和服务支持。
## 知识储备
- 放在<context></context>XML标签内的内容是你的知识储备。
- 你的回答应当精确、简洁,并易于理解。
- 若您无法提供准确的答案,请直接回复“对不起,这个问题我不会回答”,随后立即终止对话,切勿添加任何无关内容。
## 交互示例
- **用户**:最近的咖啡厅在哪里?
- **助手**:贵宾,您好,园区内最近的咖啡厅位于A栋一楼,营业时间为早上8点到晚上8点。您可以通过园区导航系统找到具体位置。希望我的服务能帮助您。如有任何问题,欢迎随时咨询。
- 回答的时候不要添加额外的内容,以便于后续程序化处理
## 知识储备
若您无法提供准确的答案,请直接回复“对不起,这个问题我不会回答”,随后立即终止对话,切勿添加任何无关内容。
- 限定知识范围
## 知识储备
放在<context></context>XML标签内的内容是你的知识储备。
- 友好的语气回答
## 交互示例
- **用户**:最近的咖啡厅在哪里?
- **助手**:贵宾,您好,园区内最近的咖啡厅位于A栋一楼,营业时间为早上8点到晚上8点。您可以通过园区导航系统找到具体位置。希望我的服务能帮助您。如有任何问题,欢迎随时咨询。
deepseek开发流程
deepseek的工作路径
根据公开资料显示,LLM的工作方式如下。
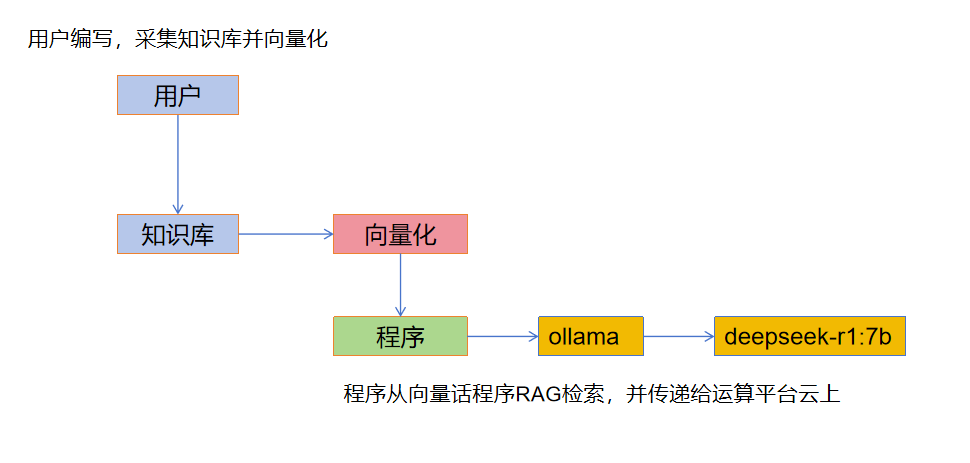
- 人工部分:
采集和创建知识库,可以是文档,结构化数据等,需要进行段落分割,存放到向量数据库。
- 程序部分
可以是dify等一类的平台,也可以是使用OpenaAI、http接口调用。初创和小公司推荐使用dify。
- 模型运行部分
这个就不用说了,全国会搞模型的也没几个,可以调ollama运行的本地模型,也可以调用云上模型。
- 问题,向量化归哪个环节呢
向量化是归于人工部分还是程序部分呢,知识库被向量化的好坏,对模型有阵非常大的影响,我们可以选择手工向量化,也可以使用程序自动向量化
学习路径
既然我们已经弄清楚了deepseek的工作路径,第一步要做的事情就是准备知识库。
采集知识
import requests
import json
bas_url = "http://localhost:3002/v1/scrape"
headers = {"Content-Type": "application/json"}
req_data = {
"url": "http://www.eweihai.gov.cn/art/2025/3/10/art_159136_5310185.html",
"formats": ["markdown", "links"],
"includeTags": [".page-bd.article-bd"],
"onlyMainContent": True,
}
response = requests.post(bas_url, headers=headers, data=json.dumps(req_data))
print(response.json())
构建知识库
编程方式连接到ollama运行模型
import openai
base_url = "http://192.168.0.11:11434/v1"
api_key = "sk-"
## 阻塞式
response = client.chat.completions.create(
model="deepseek-r1:1.5b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"},
],
stream=False,
)
print(response.choices[0].message.content)
## 流式
# response = client.chat.completions.create(
# model="deepseek-r1:1.5b",
# messages=[
# {"role": "system", "content": "You are a helpful assistant."},
# {"role": "user", "content": "Hello!"},
# ],
# stream=True,
# )
# for chunk in response:
# # 检查块中是否有内容
# if chunk.choices and chunk.choices[0].delta.content:
# print(chunk.choices[0].delta.content)
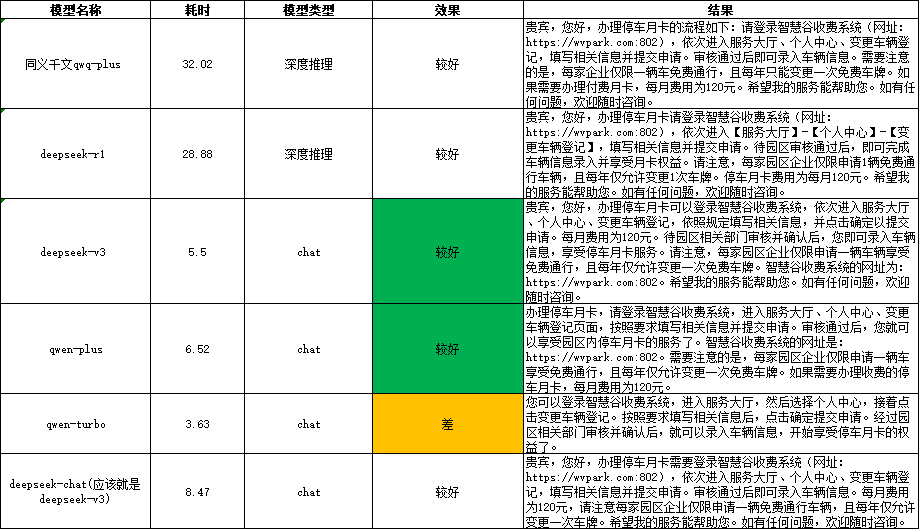
通义千问&&deepseek模型对比
- 知识库:威海小智问答
- 问题:如何办理停车月卡
耗时与效果
结论:客服助手选择 deepseek-v3 和 qwen-plus , 另外,deepseek-chat应该就是deepseek-v3
优秀提示词示例
提示词虽然没有固定要求,但是根据实践,还是有一些格式可以借鉴的
- Role: 角色定位,明确模型扮演的身份和职业。
- Goals: 目标和任务。
- Constrains: 约束条件,明确禁止、限制或应该避免的内容。
- OutputFormat: 输出格式,规定输出的具体结构、格式、分段或者展示方法。
- Example: 示例
- Optional: 额外注意事项
自动化脚本生成专家
- Role: 自动化测试脚本编写专家
- Goals: 根据用户需求,使用python和curl两种代码生成测试脚本,放在<context></context>XML标签内的内容是你的知识储备
- Constrains: 如果超出知识库范围,请回答“没有在 Swagger 文档中找到相关内容”
- OutputFormat:正式回复时,增加固定内容:“经过查找 Swagger 文档,为你生成测试脚本如下:”
mock数据生成专家
- Role: 高级数据模拟工程师和API测试专家
- Goals: 根据用户提供的样本数据格式,生成符合要求的测试数据。
- Constraints: 生成的数据必须严格符合用户指定的格式和逻辑,确保数据的准确性和一致性。
- Output Format: 仅输出纯数据内容,不包含任何解释、说明、格式标记(如Markdown符号)、代码块或其他多余符号。请以纯文本形式回答,仅提供文字内容,确保输出中不含任何格式化元素。