python&&ffmpeg&opencv
音视频编解码,ffmpeg,OpenCV , python
- python开发指南(索引合集)
- liunx安装python3&&制作python镜像
- cuda安装
- 使用ffmpeg命令行工具
- ffmpeg命令行硬件编解码
- ffmpeg SDK使用指南
- 将ffmpeg编译为dll供外部调用
- 开源直播服务器OSSRS
- 项目集成paddleocr功能
- pandas && 强大的数据操作处理程序
- python中的模块(module)包(package)和import
- pyqt使用资源文件
- fastapi
- deepseek
- deepseek 环境搭建
- docker搭建deepseek运行环境和open-webui
- deepseek和dify环境搭建
- deepseek嵌入工作流实现直接驱动业务的探索
- 网站采集工具firecrawl
- deepseek提示词小技巧
- deepseek开发流程
- 通义千问&&deepseek模型对比
- 优秀提示词示例
- yolo
- pandas创建excel
- 常用ai语音配音
- 微软语言合成
- 千问图片和视频相关提示词
- comfyui安装
- comfyui文生图
- comfyui图生图
- comfy图生视频
- facefusion&&人脸替换
- 千问修图
python开发指南(索引合集)
方法二(推荐):安装python 多版本环境(conda)
由于python有各种不同版本,且各版本不能完全兼容,anaconda 工具包可以完美解决该问题。
下载地址: https://repo.anaconda.com/archive/
或者 miniconda(推荐) , 二者的区别在于内置的常用包的多少
下载地址:https://repo.anaconda.com/miniconda/
一路 enter 下来安装,可能出现找不到命令的提示,需要进行初始化配置
# windows 下是找到 `Anaconda Prompt`
conda init --all
# 进入安装目录执行 conda init bash
/root/anaconda3/bin/conda init bash
# bash参数为你的 shell 环境,可以使用 echo $SHELL 查看
# 也可以使用参数 --all 全部设置
/root/anaconda3/bin/conda init --all
# 此时,还可以出现找不到命令情况,需要重新加载shell
source /root/.bashrc
# 查看所有已经安装的模块
pip list
# 将所有的模块输出到 文件
pip freeze > requirements.txt
# 卸载所有的模块
pip uninstall -r requirements.txt -y
# 从 requirements.txt 安装依赖
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
# 查看当前python版本
python --version
# 查看安装了哪些包
conda list
# 查看环境列表
conda env list
# 查看环境列表
conda info -e
# 创建环境,后面为使用的python版本
conda create -n your_env_name python=x.x
conda create -n cvyolo python=3.12
# 切换环境
conda activate cvyolo
# 安装依赖,应该有限用conda安装,实在找不到采用pip安装
conda install numpy
conda install --file requirements.txt
# 删除环境
conda remove --name myenv --all
使用清华源加速安装
pip install pyinstaller==6.5.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
vscode相关插件
- 格式化:https://marketplace.visualstudio.com/items?itemName=ms-python.black-formatter
- vscode扩展:https://marketplace.visualstudio.com/items?itemName=ms-python.python
- 调试扩展:https://marketplace.visualstudio.com/items?itemName=ms-python.debugpy
- IDEA快捷键:https://marketplace.visualstudio.com/items?itemName=k--kato.intellij-idea-keybindings
将py打包为exe
# 安装打包工具,注意,
# 截止至2024年6月3日,其他版本打包出来的exe报毒
pip install pyinstaller==6.5.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
# 高级设置
pyinstaller --onefile \
--windowed \
--icon=./icon.ico \
--name=贵阳燃气内网域名设置工具 \
--uac-admin \
main.py
方法一:使用pyhton3的venv多环境
python -m venv venv
source venv/Scripts/activate
pip install -r requirements.txt
liunx安装python3&&制作python镜像
制作python3 docker镜像
FROM alpine
RUN apk update && \
apk add --no-cache mysql-client \
bash \
curl \
build-base \
libffi-dev \
openssl-dev \
zlib-dev \
bzip2-dev \
readline-dev \
sqlite-dev
RUN wget https://www.python.org/ftp/python/3.10.14/Python-3.10.14.tgz && \
tar -xvzf Python-3.10.14.tgz && \
cd Python-3.10.14 && \
./configure --prefix=/usr/local --enable-optimizations && \
make -j ${nproc} && \
make install && \
rm -rf /Python-3.10.14 && \
rm -rf /Python-3.10.14.tgz
linux安装
apk update
apk add --no-cache mysql-client bash curl build-base libffi-dev openssl-dev zlib-dev bzip2-dev readline-dev sqlite-dev
wget https://www.python.org/ftp/python/3.10.14/Python-3.10.14.tgz && \
tar -xvzf Python-3.10.14.tgz
cd Python-3.10.14
./configure --prefix=/usr/local --enable-optimizations
make -j ${nproc}
make install
rm -rf /Python-3.10.14
rm -rf /Python-3.10.14.tgz
cuda安装
安装cuda
CUDA Toolkit Archive:https://developer.nvidia.com/cuda-toolkit-archive
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda-repo-rhel7-11-8-local-11.8.0_520.61.05-1.x86_64.rpm
sudo rpm -i cuda-repo-rhel7-11-8-local-11.8.0_520.61.05-1.x86_64.rpm
sudo yum -y install nvidia-driver-latest-dkms
sudo yum -y install cuda
sudo yum clean all
# 查看板卡信息
lspci | grep -i nvidia
# 查看驱动程序是否安装
nvidia-smi
# 查看nvcc版本
nvcc --version
# 此时可能nvcc已经安装,但是没有配置环境变量
查看GPU加速CUDA是否生效
# 单次查看
nvidia-smi
# 监视查看
watch -n 10 nvidia-smi
docker支持nvidia gpu
# 主机安装docker
# 主机安装nvidia-container-toolkit
curl -s -L https://nvidia.github.io/libnvidia-container/centos7/libnvidia-container.repo | sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo
yum install -y nvidia-container-toolkit
# 配置docker运行时支持gpu
nvidia-ctk runtime configure --runtime=docker
# 命令行运行使容器支持gpu
docker run -itd --gpus all python:3.10.14
使用ffmpeg命令行工具
- 下载地址:https://ffmpeg.org/download.html
- 官方文档:https://ffmpeg.org/documentation.html
- 编译好的二进制:https://github.com/GyanD/codexffmpeg/releases
使用命令行
# 命令行基本用法
# ffmpeg <全局参数> <输入参数> -i <输入文件> <输出参数> <输出文件>
# 自动推导视频播放URL
ffmpeg -v debug -re -i $(curl -L -s http://10.10.56.18:30088/video/common/videoApi?cid=557254322 | jq -r .data) -vcodec libx264 -vf scale=1280:-1 -r 20 -an -f flv rtmp://ossrs:1935/csud/live/557254322
# 获取网络文件
ffmpeg -v debug -re -i https://qq829.cn/uploads/20221204/1.mp4 -vcodec libx264 -vf "scale=1280:-2" -r 20 -an -f flv rtmp:/ossrs:1935/csud/live/557254322
# 获取网络文件
ffmpeg -v debug -re -i https://qq829.cn/uploads/20221204/1.mp4 -vcodec libx264 -f flv rtmp://ossrs:1935/live/557254322
# 屏幕截图
ffmpeg -r 8 -f "gdigrab" -i "desktop" -vcodec libx264 -f flv rtmp://ossrs:1935/live/557254322
# -stream_loop -1 循环播放
# -v debug 打开调试信息
# -re 实时读取,既按原视频的帧率读取,否则会以最快的速度读取,通常在将视频文件读取为直播源的时候需要,摄像头(直播)源不需要
# -i 输入文件
# -vcodec libx264 视频编码器
# -vf "scale=1280:-2 "视频画面大小调整,-2指强制偶数对其,因为奇数会报错
# -r 20 输出帧率
# -an 静音
# -f flv 输出 格式
# 视频截图
ffmpeg -i https://qq829.cn/uploads/20221204/1.mp4 -ss 20 -vframes 1 -vf scale=800:-2 -qscale:v 2 -y 2.jpg
# -ss 视频开始位置
# -vframes 输出视频的帧目数
# -vf scale 视频滤镜,-2 表示根据前一个参数自动计算,并强制对其偶数,因为奇数会报错
# -qscale:v 2 图片质量,取值为2-10之间,数值越小画质越好
播放器
# 使用ffplay播放
ffplay 1.mp4
使用VLC播放:
https://srs.qq829.cn/csud/live/557254322.flv
https://srs.qq829.cn/csud/live/557254322.m3u8
# 使用bilibili开源的播放器
# https://github.com/xqq/mpegts.js
视频信息查看
# 显示媒体格式信息
ffprobe -show_format d:/1.mp4
# 显示每天流信息
ffprobe -show_streams d:/1.mp4
ffmpeg命令行硬件编解码
查看硬件支持情况
# 查看支持的硬件解码方式
ffmpeg -hwaccels
# cuda nvidia显卡
# dxva2
# qsv intel显卡
# d3d11va
# 查看解码器名称
ffmpeg -decoders | grep h264
# h264_qsv intel 硬件解码
# h264_cuvid nvidia 硬件解码
ffmpeg -decoders | grep hevc
# hevc_qsv intel硬解
# hevc_cuvid nvidia硬解
# 查看编码器名称
ffmpeg -encoders | grep h264
# h264_qsv intel 硬件编码
# h264_nvenc nvidia 硬件编码
ffmpeg -encoders | grep hevc
# hevc_qsv intel 硬件编码
# hevc_nvenc nvidia 硬件编码
在命令行中使用
# 根据硬件自动选择
ffmpeg.exe -hwaccel auto -i ./static/1.mp4 -f flv rtmp://secm-video.vppark.cn:31935/live/1
# 指定硬件编解码器
ffmpeg.exe -hwaccel qsv -c:v h264_qsv -i ./static/1.mp4 -c:v h264_qsv -an -f flv rtmp://secm-video.vppark.cn:31935/live/1
# 视频音频硬件编码
ffmpeg.exe -hwaccel qsv -c:v h264_qsv -i ./static/3.mp4 -c:v h264_qsv -c:a aac -ar 44100 -ab 48k -f flv rtmp://secm-video.vppark.cn:31935/live/3
ffmpeg SDK使用指南
官方编译好的release下载
https://github.com/GyanD/codexffmpeg/releases
修改过的支持dll调用的
https://github.com/donglietao/ffmpeg-dll
def ffmpeg():
dll = ctypes.windll.LoadLibrary(
"D:/cpp-sdk/FFmpeg-n7.0/ffmpeg-exe-dll/Release/release/ffmpeg-dll.dll"
)
ffmpeg_main = dll.ffmain
ffmpeg_main.argtypes = [ctypes.c_int, ctypes.POINTER(ctypes.c_char_p)]
ffmpeg_main.restype = ctypes.c_int
argv = (ctypes.c_char_p * 10)()
argv[0] = bytes("ffmpeg", "utf-8")
argv[1] = bytes("-f", "utf-8")
argv[2] = bytes("gdigrab", "utf-8")
argv[3] = bytes("-i", "utf-8")
argv[4] = bytes("desktop", "utf-8")
argv[5] = bytes("-vcodec", "utf-8")
argv[6] = bytes("libx264", "utf-8")
argv[7] = bytes("-f", "utf-8")
argv[8] = bytes("flv", "utf-8")
argv[9] = bytes("rtmp://srs-push.qq829.cn:31935/live/557254322", "utf-8")
ret = ffmpeg_main(10, argv)
ctypes.windll.kernel32.FreeLibrary.argtypes = [ctypes.c_void_p]
ctypes.windll.kernel32.FreeLibrary.restype = ctypes.c_int
ctypes.windll.kernel32.FreeLibrary(dll._handle)
return ret
ffmpeg()
ffmpeg编解码c++代码实现
// 注册输入和输出设备
avdevice_register_all();
// 初始化网络库
avformat_network_init();
//----------------打开输入设备----------------------//
// 确定输入格式
av_find_input_format("gdigrab");
// 打开输入文件
avformat_open_input();
// 查找输入流
avformat_find_stream_info();
// 选择流
in_stream = input_fmt_ctx->streams[i];
// 输入流的编解码器
AVCodec *in_codec = avcodec_find_decoder(in_stream->codecpar->codec_id);
// 解密上下文
in_codec_ctx = avcodec_alloc_context3(in_codec);
// 解码参数复制
avcodec_parameters_to_context();
// 打开解码器
avcodec_open2();
//----------------打开输处设备----------------------//
// 确定输出格式
av_guess_format()
// 构建输出上下文
avformat_alloc_output_context2();
// 添加输出流
AVStream *out_stream = avformat_new_stream(output_fmt_ctx, NULL);
// 设置流的参数
out_stream->codecpar->codec_id = AV_CODEC_ID_H264;
// 输出流编解码
AVCodec *out_codec = avcodec_find_encoder(out_stream->codecpar->codec_id);
// 输出流编码器上下文
AVCodecContext *out_codec_ctx = avcodec_alloc_context3(out_codec);
// 编码器参数复制
avcodec_parameters_to_context(out_codec_ctx, out_stream->codecpar);
// 打开编码器
avcodec_open2();
// 写入SPS和PPS信息
out_stream->codecpar->extradata = out_codec_ctx->extradata;
out_stream->codecpar->extradata_size = out_codec_ctx->extradata_size;
// 打开输出IO
avio_open();
// 写入文件头信息
avformat_write_header();
//----------------解密和转换----------------------//
while (1){
// 从输入设备读取数据包
ret = av_read_frame(input_fmt_ctx, &packet);
// 解码数据包为帧
ret = avcodec_send_packet(in_codec_ctx, &packet);
// 从解码器中获取帧
ret = avcodec_receive_frame(in_codec_ctx, frame);
// 格式转换
ret = sws_scale(sws_ctx, (const uint8_t *const *)frame->data, frame->linesize,
0, frame->height,
enc_frame->data, enc_frame->linesize);
// 设置帧的时间戳
enc_frame->pts = av_rescale_q_rnd((frame->pts - start_pts), in_stream->time_base, out_stream->time_base, AV_ROUND_NEAR_INF | AV_ROUND_PASS_MINMAX);
enc_frame->pkt_dts = enc_frame->pts;
// 将帧发送到编码器
ret = avcodec_send_frame(out_codec_ctx, enc_frame);
// 从编码器中获取数据包
while (avcodec_receive_packet(out_codec_ctx, &enc_packet) == 0)
{
// 写入数据包
ret = av_interleaved_write_frame(output_fmt_ctx, &enc_packet);
if (ret < 0)
{
printf("7:Error while writing output packet:%s\n", av_err2str(ret));
break;
}
}
// 释放编码数据包
av_packet_unref(&enc_packet);
// 释放编码数据包
av_packet_unref(&packet);
}
//----------------后续工作----------------------//
// 写入文件尾
av_write_trailer(output_fmt_ctx);
// 关闭输出文件
avio_close(output_fmt_ctx->pb);
// 释放数据包
av_packet_free(&packet);
av_packet_free(&enc_packet);
// 释放帧
av_frame_free(&frame);
av_frame_free(&enc_frame);
// 释放格式转换器
sws_freeContext(sws_ctx);
// 释放编码器上下文
avcodec_free_context(&in_codec_ctx);
avcodec_free_context(&out_codec_ctx);
// 释放输入和输出设备
avformat_close_input(&input_fmt_ctx);
avformat_free_context(input_fmt_ctx);
// 释放输出设备
avformat_close_input(&output_fmt_ctx);
avformat_free_context(output_fmt_ctx);
// 释放网络库
avformat_network_deinit();
将ffmpeg编译为dll供外部调用
将ffmpeg 编译为dll供外部调用
创建qt应用程序,设置项目为lib
// ffmpeg-dll.pro
#TEMPLATE = app
#CONFIG += console
TEMPLATE = lib
增加dll函数导出
// main.c
__declspec(dllexport) int __cdecl ffmain(int argc, char const *argv[]){
return main(argc,argv);
}
处理命令行参数
既ffmpeg的传入参数并不是以传入的为准,而是内部使用操作系统API又进行了替换,如果在某些系统出现兼容性问题,需要再次修改源代码
// cmdutils.c
// split_commandline
// 注释掉 785 行
// prepare_app_arguments(&argc, &argv);
使用python 调用
import ctypes as ctypes
import time as time
def ffmpeg():
dll = ctypes.windll.LoadLibrary(
"D:/cpp-sdk/FFmpeg-n7.0/ffmpeg-exe-dll/Release/release/ffmpeg-dll.dll"
)
ffmpeg_main = dll.ffmain
ffmpeg_main.argtypes = [ctypes.c_int, ctypes.POINTER(ctypes.c_char_p)]
ffmpeg_main.restype = ctypes.c_int
argv = (ctypes.c_char_p * 10)()
argv[0] = bytes("ffmpeg", "utf-8")
argv[1] = bytes("-f", "utf-8")
argv[2] = bytes("gdigrab", "utf-8")
argv[3] = bytes("-i", "utf-8")
argv[4] = bytes("desktop", "utf-8")
argv[5] = bytes("-vcodec", "utf-8")
argv[6] = bytes("libx264", "utf-8")
argv[7] = bytes("-f", "utf-8")
argv[8] = bytes("flv", "utf-8")
argv[9] = bytes("rtmp://srs-push.qq829.cn:31935/live/557254322", "utf-8")
ret = ffmpeg_main(10, argv)
ctypes.windll.kernel32.FreeLibrary.argtypes = [ctypes.c_void_p]
ctypes.windll.kernel32.FreeLibrary.restype = ctypes.c_int
ctypes.windll.kernel32.FreeLibrary(dll._handle)
return ret
while ffmpeg() < 0:
print("ffmpeg error")
time.sleep(5)
开源直播服务器OSSRS
OSSRS
SRS(Simple Realtime Server)是一个简单高效的实时视频服务器,支持RTMP、WebRTC、HLS、HTTP-FLV、SRT等多种实时流媒体协议。
官方地址:ossrs.ne
docker-compose.yaml
version: '3'
services:
ossrs:
image: registry.cn-hangzhou.aliyuncs.com/ossrs/srs:5
ports:
- 1935:1935 # RTMP推流端口
- 1985:1985 # HTTP API 端口
- 8080:8080 # 内置NGINX端口,可以用于http观看flv
volumes:
- ./conf/docker.conf:/usr/local/srs/conf/docker.conf:ro
command: ./objs/srs -c conf/docker.conf
服务器自动保留录像
# conf/docker.conf
dvr {
enabled on;
dvr_path ./objs/nginx/html/dvr/[app]/[stream].[timestamp].mp4;
dvr_plan segment;
# 按时间段分割,单位为秒
dvr_duration 300;
# 等待关键帧,如果为off可能导致启动播放时花屏
dvr_wait_keyframe on;
}
使用FFMPEG推流
使用ffmpeg命令行: https://iovhm.com/book/books/ffmpegopencv/page/ffmpeg
# 命令行基本用法
# ffmpeg <全局参数> <输入参数> -i <输入文件> <输出参数> <输出文件>
# 从一个源转换到另外一个源
ffmpeg -stream_loop -1 -re -i https://smart.saas.vppark.cn/oss/1.mp4 -vcodec libx264 -f flv rtmp://srs-push.qq829.cn:31935/live/557254322
# 桌面截图
ffmpeg -r 8 -f "gdigrab" -i "desktop" -vcodec libx264 -f flv rtmp://srs-push.qq829.cn:31935/live/557254322
使用vlc播放
# 播放地址
https://srs.qq829.cn/live/557254322.flv
项目集成paddleocr功能




示例代码下载
参考网站
- https://www.paddlepaddle.org.cn/
- https://github.com/PaddlePaddle/PaddleOCR
- https://fastapi.tiangolo.com/
安装paddle和paddle ocr环境
# 安装paddlepaddle
# https://www.paddlepaddle.org.cn/
pip install paddlepaddle==2.6.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装paddleocr
# 提示,截止至2024年5月2日,需要的python版本为3.11.更高版本会出现安装不上的情况
# 提示,截止至2024年5月2日,paddleocr==2.7.5有bug
# 需要修改的地方
# C:\Python311\Lib\site-packages\paddleocr\paddleocr.py
# 第54行之后
# from ppstructure import predict_system
pip install paddleocr==2.7.5 -i https://mirror.baidu.com/pypi/simple
# 可能出现其他安装失败情况,请使用清华源安装,更新pip工具
pip install --upgrade pip wheel setuptools
安装fast api服务框架
# 安装fastAPI
pip install fastapi -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装web容器
pip install "uvicorn[standard]" -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装from参数表单
pip install python-multipart -i https://pypi.tuna.tsinghua.edu.cn/simple
编写后台代码
import paddle as paddle
from paddleocr import PaddleOCR, draw_ocr
from PIL import Image
from fastapi import FastAPI, File, UploadFile
from fastapi.responses import HTMLResponse
from fastapi.staticfiles import StaticFiles
import time
import uvicorn
# 打印paddle版本
print(paddle.__version__)
app = FastAPI()
def get_image_ocr(img_path: str):
# 创建一个OCR实例
ocr = PaddleOCR(
use_angle_cls=True, lang="ch"
) # need to run only once to download and load model into memory
# img_path = "./images/test.png"
# 使用PaddleOCR进行文字检测和识别
ocr_result = ocr.ocr(img_path, cls=True)
# 显示结果
for line in ocr_result:
print(line)
# 对现实结果在原图进行标注
result = ocr_result[0]
image = Image.open(img_path).convert("RGB")
boxes = [elements[0] for elements in result]
# pairs = [elements[1] for elements in ocr_result]
# txts = [pair[0] for pair in pairs]
# scores = [pair[1] for pair in pairs]
im_show = draw_ocr(image, boxes)
im_show = Image.fromarray(im_show)
im_show.save(f"{img_path}")
# im_show.save("./images/result.jpg")
return {"image": img_path, "result": result}
app.mount("/static", StaticFiles(directory="./static"), name="static")
@app.get("/")
def read_root():
html_content = """
<html>
<head>
<title>OCR</title>
</head>
<body>
<h1>OCR</h1>
<p>Upload an image to extract text from it.</p>
</body>
</html>
"""
return HTMLResponse(content=html_content, status_code=200)
sequence_counter = 1
@app.post("/ocr/")
async def ocr_image(file: UploadFile | None = File(None)):
# 判断文件是否存在
if file is None:
return {"code": 400, "message": "No file found", data: None}
# 生成时间戳保存上传图片以免被覆盖
current_time = int(time.time() * 10000)
unique_sequnce = current_time + sequence_counter
new_fileName = f"./static/{unique_sequnce}--{file.filename}.jpg"
# 将文件写入磁盘
with open(f"{new_fileName}", "wb+") as fsio:
fsio.write(await file.read())
pass
# 调用OCR方法
ocr_result = get_image_ocr(new_fileName)
return {"code": 200, "message": "ok", "data": ocr_result}
# 启动服务
uvicorn.run(app, host="0.0.0.0", port=8000)
pandas && 强大的数据操作处理程序
安装
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
# excel支持
pip install openpyxl -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install xlsxwriter -i https://pypi.tuna.tsinghua.edu.cn/simple
连接到数据
支持读取多张数据:CSV,JSON,Excel,mysql等。
具体可以参考:https://pandas.pydata.org/pandas-docs/stable/user_guide/io.html
api设计的非常简洁:
- 读取:read_csv , read_json , read_excel,read_sql
- 写入:to_csv , to_json,to_excel , to_sql
连接到mysql
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install sqlalchemy -i https://pypi.tuna.tsinghua.edu.cn/simple
# 增加pandas库的导入
import pandas as pd
# 添加SQLAlchemy的导入
from sqlalchemy import create_engine
# 示例用法
if True:
engine = create_engine(
"mysql+pymysql://root:password@192.168.0.10:33318/renren_cloud_basic"
)
query = "SELECT * FROM park_user"
# 使用chunksize参数来实现流式处理
df = pd.read_sql(query, engine)
# 显示数据的结构和数据类型
print(df.info())
# 显示列名
print(df.columns)
连接到mysql的额外操作
- read_sql_table(table_name,connection)
- read_sql_query(sql,connection)
- read_sql(sql,connection)
操作数据
- 获取数据形状
row_size, col_size = grouped.shape
log.info(f"row_size:{row_size},col_size:{col_size}")
# row_size:13,col_size:7
- 数据清洗:提取数据到新的列
# 将月份列提取为年
dataFrame["年份"] = pd.to_datetime(dataFrame["月份"]).dt.year
-
数据清洗:清洗空值
-
数据清洗:清洗格式错误数据
-
数据清洗:清洗错误数据
-
数据清洗:清洗重复数据
-
分组聚合
grouped = (
dataFrame.groupby(["客户名称", "合同编号", "年份"])
.agg(
{
"减免总金额": "sum",
"政策减免金额": "sum",
"运营减免金额": "sum",
"其他减免金额": "sum",
}
)
.reset_index() # 使分组变成一个平面
)
# 设置索引列的名称为“序号”
grouped.index.name = "序号"
- 筛选数据
# 提取整列数据
print(grouped["客户名称"])
# 筛选客户名称列数据
print(grouped[grouped["客户名称"] == "山东智拓大数据有限公司"])
写入Eexcel时设置样式
pandas是做数据处理的,默认导出并不能设置样式、合并单元格等,需要记住其他工具。
# 自定义写入程序,使用xlsxwriter写入
with pd.ExcelWriter("./files/output.xlsx", engine="xlsxwriter") as writer:
# 直接写入数据,没有样式
# grouped.to_excel(writer, sheet_name="Sheet1", startrow=1, startcol=1, index=True)
# 获取工作表
workbook = writer.book
worksheet = None
# 如果worksheet不存在,则创建一个工作表
if "Sheet1" in writer.sheets:
worksheet = writer.sheets["Sheet1"]
else:
worksheet = workbook.add_worksheet("Sheet1")
# 创建样式
default_format = {
"bold": False,
# 边框
"border": 1,
# 垂直居中
"valign": "vcenter",
# 自动换行
"text_wrap": True,
# 水平居中
# "align": "center",
# 字体大小
"font_size": 9,
}
# 创建样式
cell_format_default = workbook.add_format(default_format)
cell_format_head = workbook.add_format(
{
**default_format,
**{
"align": "center",
"bold": True,
},
}
)
# 设置列的宽度,单位是多少个字符,一个中文占两个字符
worksheet.set_column("A:A", 10)
worksheet.set_column("B:B", 30)
worksheet.set_column("C:C", 20)
worksheet.set_column("E:H", 12)
# 插入logo图片
worksheet.insert_image(
"A1",
"./files/logo.png",
{
"x_scale": first_row_height / logo_image_height,
"y_scale": first_row_height / logo_image_height,
"x_offset": 5,
"y_offset": 5,
},
)
# 合并单元格
worksheet.merge_range("A1:B1", "", cell_format_head)
worksheet.merge_range("C1:H1", "租金减免表", cell_format_head)
# 设置行高,单位是像素
worksheet.set_row(0, first_row_height)
# 增加序号列
worksheet.write("A2", "序号", cell_format_head)
worksheet.write_column("A3", range(1, len(grouped) + 1), cell_format_head)
# 计算行和列的偏移量
row_offset = 2
col_offset = 1
# 写入数据并设置样式,使用xlsxwriter作为驱动引擎时,需要将数据与样式一起写入,并不能直接修改样式
for row_num, row_data in grouped.iterrows():
for col_num, col_data in enumerate(row_data):
worksheet.write(
row_num + row_offset,
col_num + col_offset,
col_data,
cell_format_default,
)
# 合并合同编号列,如果连续的行数据相同,则合并
start_row = 0
for row_num, row_data in grouped.iterrows():
current_value = row_data["合同编号"]
next_row = row_num + 1
next_value = (
grouped.iloc[next_row]["合同编号"] if next_row < len(grouped) else None
)
if current_value != next_value:
log.info(f"{start_row} - {row_num} - {current_value}")
if row_num - start_row > 0:
worksheet.merge_range(
start_row + row_offset,
grouped.columns.get_loc("合同编号") + col_offset,
row_num + row_offset,
grouped.columns.get_loc("合同编号") + col_offset,
current_value,
cell_format_default,
)
start_row = next_row
python中的模块(module)包(package)和import
python因为其灵活性,也带来了很多特殊的用法,
项目结构约定
project/
│
├── main.py
├── routers/
│ ├── __init__.py
│ ├── items.py
│ └── users.py
├── models/
│ ├── __init__.py
│ ├── item.py
│ └── user.py
├── schemas/
│ ├── __init__.py
│ ├── item.py
│ └── user.py
├── utils/
│ ├── __init__.py
│ ├── string_util.py
│ └── log_factory.py
└── templates/
└── index.html
package和import
- 一个py源文件就是一个模块,可以直接使用import py_name 进行导入
project/
│
├── main.py
├── vp_smtp.py
└──
# vp_smtp
def send_mail(msg: str):
print(msg)
pass
# main.py
# 模块全部导入
import vp_smtp
# 使用模块名称访问
vp_smtp.send_mail("使用模块名称访问")
# 导入模块并重别名
import vp_smtp as vpsmtp
# 使模块别名调用
vpsmtp.send_mail("使模块别名调用")
# 导入模块中的具体的方法
from vp_smtp import send_mail
# 调用方法
send_mail("直接调用方法")
- 将源文件放入到一个文件夹,并在文件夹下面防一个 __init__.py 文件 , 则成了一个包(一组模块)
# utils\vp_smtp.ly
def send_mail(msg: str):
print(msg)
pass
# main.py
# 按源文件存储路径 package.moduel 方式导入,自动查找对应的py文件
import utils.vp_smtp
# 完全限定调用:package.moduel.fun
utils.vp_smtp.send_mail("完全限定调用:package.moduel.fun")
# 按源文件存储路径 package.moduel 方式导入,并增加别名,自动查找对应的py文件
import utils.vp_smtp as vpsmtp
# 别名调用
vpsmtp.send_mail("别名调用:alias.fun")
# 从包中导入 vp_smtp
from utils import vp_smtp
vp_smtp.send_mail("从包中导入 vp_smtp")
__init__.py
__init__.py 是一个特殊的文件
- 标记文件夹是一个package
- 可以加入一些初始化代码,例如大家都喜欢放入 __version__ = 0.1.1
- 定义包级别的变量 , 函数 , 等,用作访问控制
# __init__.py
# 先在__init__.py 初始化包和组织包的结构
from .vp_smtp import send_mail
# main.py
# 推荐使用这种方式,便于组织和管理源文件的公开
from utils import send_mail
send_mail("从_init__导入")
pyqt使用资源文件
1. 创建资源文件
首先,创建一个资源文件(例如 resources.qrc),并定义所需的资源。例如:
<RCC>
<qresource prefix="/icons">
<file>icon.png</file>
</qresource>
</RCC>
- prefix:资源的前缀路径,用于在代码中访问资源。
- <file>:资源文件的路径(相对于资源文件所在目录)
2. 将资源文件转换为 Python 代码
使用 pyrcc5 工具将资源文件转换为 Python 代码。在终端中运行以下命令:
pyrcc5 -o resources_rc.py resources.qrc
3. 在 PyQt5 应用程序中使用资源
在代码中导入生成的资源文件,并使用资源路径来加载资源。以下是完整的代码示例:
import sys
from PyQt5.QtWidgets import QApplication, QWidget
from PyQt5.QtGui import QIcon
import resources_rc # 导入生成的资源文件
class ExampleApp(QWidget):
def __init__(self):
super().__init__()
self.initUI()
def initUI(self):
# 设置窗口标题
self.setWindowTitle('PyQt5 窗口图标示例')
# 设置窗口大小
self.setGeometry(300, 300, 300, 200)
# 使用资源文件中的图标
self.setWindowIcon(QIcon(":/icons/icon.png")) # 注意路径格式
if __name__ == '__main__':
app = QApplication(sys.argv)
ex = ExampleApp()
ex.show()
sys.exit(app.exec_())
fastapi
python restful API服务器fastAPI
组件
-
fastAPI : https://fastapi.tiangolo.com/
-
uvicorn: https://www.uvicorn.org/
快速开始
# 安装fastAPI
pip install fastapi -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装web容器
pip install "uvicorn[standard]" -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装from参数表单
pip install python-multipart -i https://pypi.tuna.tsinghua.edu.cn/simple
编写代码
# main.py
from fastapi import FastAPI, APIRouter
from fastapi.staticfiles import StaticFiles
app = FastAPI()
router = APIRouter()
# 静态目录
app.mount("/static", StaticFiles(directory="./static"), name="static")
@app.get("/")
def read_root():
return {"Hello": "World"}
@app.get("/")
async def read_root():
html_content = """
<html>
<head>
<title>FastAPI</title>
</head>
<body>
<h1>Hello, FastAPI!</h1>
<p>
<a href="https://fastapi.tiangolo.com">
https://fastapi.tiangolo.com
</a>
</p>
</body>
</html>
"""
return HTMLResponse(content=html_content, media_type="text/html")
# 运行
uvicorn main:app --reload
# 也可以用代码实现
if __name__ == "__main__":
uvicorn.run(app, host="localhost", port=8000)
# 生成环境运行参数
# uvicorn main:app --reload --host=localhost --port=8000
约定和规范
- 项目结构
├── main.py # 主应用文件
├── config.py # 配置文件
├── run.py # 启动脚本
├── requirements.txt # 项目依赖
├── .env # 环境变量
├── README.md # 项目说明
├── routers/ # 路由
├──
├── models/ # 数据模型
├──
├── schemas/ # 数据架构
├──
├── repositories/ # 数据库操作
├──
├── services/ # 业务逻辑
├──
└── utils/ # 工具类
公共日志类
# common_logger.py
import logging
import sys
__all__ = ["get_logger"]
# 1. 只初始化一次
_INITIALIZED = False
# 2. 颜色表 + Windows 兼容
COLORS = {
"DEBUG": "\033[36m",
"INFO": "\033[32m",
"WARNING": "\033[33m",
"ERROR": "\033[31m",
"CRITICAL": "\033[35m",
"RESET": "\033[0m",
}
def _init_logger(level: int = logging.INFO):
global _INITIALIZED
# force=True 防止重复
if _INITIALIZED:
return
class ColorFormatter(logging.Formatter):
def format(self, record):
levelname = record.levelname
record.levelname = (
f"{COLORS.get(levelname, '')}{levelname}{COLORS['RESET']}"
)
return super().format(record)
handler = logging.StreamHandler(sys.stdout)
handler.setFormatter(
ColorFormatter(
fmt="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
)
)
logging.basicConfig(level=level, handlers=[handler], force=True)
# force=True 防止重复
_INITIALIZED = True
def get_logger(name: str, level: int = logging.INFO) -> logging.Logger:
_init_logger(level)
return logging.getLogger(name)
uvicorn 日志格式统一
#!/usr/bin/env python3
"""
FastAPI 应用启动脚本
"""
import uvicorn
from config import settings
from common_logger import get_logger
log = get_logger(__name__)
LOGGING_CONFIG = {
"version": 1,
"disable_existing_loggers": False,
"formatters": {
"default": {
"fmt": "%(asctime)s - %(name)s - %(levelname)s - %(message)s",
},
"access": {
"fmt": "%(asctime)s - %(name)s - %(levelname)s - %(message)s",
},
},
}
if __name__ == "__main__":
log.info(f"启动 {settings.app_name} v{settings.app_version}")
log.info(f"服务器地址: http://{settings.host}:{settings.port}")
# print(f"API 文档: http://{settings.host}:{settings.port}/docs")
log.info("-" * 50)
uvicorn.run(
"main:app",
host=settings.host,
port=settings.port,
reload=settings.reload,
log_level=settings.log_level.lower(),
log_config=LOGGING_CONFIG,
)
fastapi 路由管理
定义包并编写路由
# routers\zlmedia_hook.py
from fastapi import APIRouter
router = APIRouter(prefix="/zlmedia/hook", tags=["zlmedia_hook"])
@router.get("/")
async def hello():
return {"code": "0", "message": "success", "data": "hello world"}
自动加载路由
# main.py
import routers.zlmedia_hook as zlmedia_hook
# 附件路由
app.include_router(zlmedia_hook.router)
fastapi项目结构
.
├── main.py # 主应用文件
├── config.py # 配置文件
├── run.py # 启动脚本
├── requirements.txt # 项目依赖
├── .env # 环境变量
├── README.md # 项目说明
├── routers/ # 路由
├── models/ # 数据模型
├── schemas/ # 数据架构
├── repositories/ # 数据库操作
├── services/ # 业务逻辑
└── utils/ # 工具类
公共日志类
# common_logger.py
import logging
import sys
__all__ = ["get_logger"]
# 1. 只初始化一次
_INITIALIZED = False
# 2. 颜色表 + Windows 兼容
COLORS = {
"DEBUG": "\033[36m",
"INFO": "\033[32m",
"WARNING": "\033[33m",
"ERROR": "\033[31m",
"CRITICAL": "\033[35m",
"RESET": "\033[0m",
}
def _init_logger(level: int = logging.INFO):
global _INITIALIZED
# force=True 防止重复
if _INITIALIZED:
return
class ColorFormatter(logging.Formatter):
def format(self, record):
levelname = record.levelname
record.levelname = (
f"{COLORS.get(levelname, '')}{levelname}{COLORS['RESET']}"
)
return super().format(record)
handler = logging.StreamHandler(sys.stdout)
handler.setFormatter(
ColorFormatter(
fmt="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
)
)
logging.basicConfig(level=level, handlers=[handler], force=True)
# force=True 防止重复
_INITIALIZED = True
def get_logger(name: str, level: int = logging.INFO) -> logging.Logger:
_init_logger(level)
return logging.getLogger(name)
uvicorn 日志根式统一
#!/usr/bin/env python3
"""
FastAPI 应用启动脚本
"""
import uvicorn
from config import settings
from common_logger import get_logger
log = get_logger(__name__)
LOGGING_CONFIG = {
"version": 1,
"disable_existing_loggers": False,
"formatters": {
"default": {
"fmt": "%(asctime)s - %(name)s - %(levelname)s - %(message)s",
},
"access": {
"fmt": "%(asctime)s - %(name)s - %(levelname)s - %(message)s",
},
},
}
if __name__ == "__main__":
log.info(f"启动 {settings.app_name} v{settings.app_version}")
log.info(f"服务器地址: http://{settings.host}:{settings.port}")
# print(f"API 文档: http://{settings.host}:{settings.port}/docs")
log.info("-" * 50)
uvicorn.run(
"main:app",
host=settings.host,
port=settings.port,
reload=settings.reload,
log_level=settings.log_level.lower(),
log_config=LOGGING_CONFIG,
)
参数传递
from参数和json body 参数是互斥的,只能使用一种
Query, Form, Body, 可以省略 ,匹配优先级是:路径参数,查询参数,body参数
查询参数和from参数
@app.post("/query_1")
def query_1(q: Any = (None), f: Any = (None)):
return {"code": 0, "message": "success", "data": {"q": q, "f": f}}
查询参数和json body
class B_Model(BaseModel):
b: str | int | Any = None
@app.post("/query_2")
def query_2(
q: str = Query(None),
b: B_Model = Body(None),
token: str = Header(None, alias="token"),
user: str = Cookie(None, alias="user"),
):
return {
"code": 0,
"message": "success",
"data": {"q": q, "b": b, "token": token, "user": user},
}
使用中间件(拦截器)
标准做法
# LoginMiddleware.py
from fastapi import Request,status
from starlette.middleware.base import BaseHTTPMiddleware
from fastapi.responses import JSONResponse
WHITE_LIST={
"/",
"/docs",
"/health"
}
# 需要登陆中间件
class LoginMiddleware(BaseHTTPMiddleware):
async def dispatch(self,request: Request, call_next):
token = request.headers.get("token", "")
if request.url.path in (WHITE_LIST):
return await call_next(request)
if not token:
return JSONResponse(
status_code=status.HTTP_401_UNAUTHORIZED,
content={"code": 401, "message": "Missing or invalid token"}
)
response = await call_next(request)
return response
# 中间件示例
class XPowerByMiddleware(BaseHTTPMiddleware):
async def dispatch(self,request: Request, call_next):
response = await call_next(request)
response.headers["x-powered-by"]="iovhm-com © 2022"
return response
# main.py
from LoginMiddleware import LoginMiddleware,XPowerByMiddleware
app.add_middleware(LoginMiddleware)
app.add_middleware(XPowerByMiddleware)
`
链接数据库
# 安装
pip install sqlalchemy aiomysql -i https://pypi.tuna.tsinghua.edu.cn/simple
deepseek
deepseek 环境搭建
这篇文章是入门文章,没有什么实用价值,仅是将运行deepseek的环境运行起来了。
主要软件
- ollama:模型运行平台,https://ollama.com/download
- open-webui:简单的chat页面,https://github.com/open-webui/open-webui
- dify :模型编排平台,https://github.com/langgenius/dify
- docker
- python
- 3.11:open-webui需要的运行时版本
- 科学上网:https://iovhm.com/book/books/cee63/page/9872e
ollama可以直接在容器运行
不用担心在容器运行会有性能损失,经过多年对docker的实践,除了网络方面会有损失外,其他方面并没有损失,可以将网络设置为host模式来规避bridge网络的性能损失。
相反,如果在主机直接运行,各种版本的依赖,新版本的升级,环境更加容易出问题。
version: "3"
services:
ollama:
image: harbor.iovhm.com/hub/ollama/ollama:0.5.12
container_name: ollama
restart: always
privileged: true
ports:
- "11434:11434"
volumes:
- ./ollama:/root/.ollama
networks:
- vpclub-bridge
安装模型运行平台ollama
模型运行平台下载:https://ollama.com/download
模型备份
每次下载模型都需要很久,可以将模型备份出来
进入到用户文件夹下面,例如 C:\Users\admin.ollama\models , 将模型复制出来,复制到新的机器对应的目录(未验证)
下载和运行模型
# 显示所有命令行参数
ollama
# 所有的命令行
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
# 运行服务,如果服务没有运行,可以用这个启动服务,非必须,一般安装完成后都会自动运行
ollama serve
# 验证安装
ollama -v
# 下载模型
ollama pull deepseek-r1:1.5b
# 运行模型
# 如果本地没有这个模型,则会自动下载并运行
# 运行后,此时会出现一个对话窗口,可以进行输入文字进行对话
# 键入/bye 或者ctrl+d可以退出对话窗口,模型在后台运行
# 退出对话框后,如果需要再次进入对话框,可以在此run模型
ollama run deepseek-r1:1.5b
# 显示已经安装的模型列表
ollama list
# 显示所有在运行的模型列表
ollama ps
# 显示模型信息
ollama show deepseek-r1:1.5b
使用API对话
默认安装没有修改配置的话,ollama 运行在11343端口,可以使用命令行或者postmain测试
这种方式太简陋,要实现的内容太多,不推荐
curl -X POST -H "Content-Type: application/json" \
-d '{"model": "deepseek-r1:1.5b", "prompt": "你好,世界!"}' \
http://localhost:11434/api/generate
使用open-webui
这是一个简单的兼容多个模型的、兼容openai接口调用方式的可视化界面
下载地址:https://github.com/open-webui/open-webui
文档地址:https://docs.openwebui.com/
可以直接使用docker运行,docker的安装方式自行百度,优先推荐使用docker安装
# GPU版
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
# CPU版
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
# pip 安装
pip install open-webui -i https://pypi.tuna.tsinghua.edu.cn/simple
# python运行
# 此时系统运行在 http://localhost:8080
open-webui serve
详细设置请看:https://iovhm.com/book/books/bbcbf/page/deepseek-docker
docker搭建deepseek运行环境和open-webui
这篇文章没有什么实用价值,仅作为快速体验ollama运行环境。或者当做一个附加工具,用来管理和查看ollama环境。
docker-compose.yaml
这个脚本将同时启动ollama 和 open-webui
version: "3"
services:
ollama:
image: harbor.iovhm.com/hub/ollama/ollama:0.5.12
container_name: ollama
restart: always
privileged: true
ports:
- "11434:11434"
volumes:
- ./ollama:/root/.ollama
networks:
- vpclub-bridge
# docker-compose --profile open-webui up -d
open-webui:
# CPU版
image: harbor.iovhm.com/public/open-webui/open-webui:main
# GPU版
# image: harbor.iovhm.com/public/open-webui/open-webui:main-gpu
container_name: open-webui
restart: always
privileged: true
ports:
- "3000:8080"
volumes:
- ./open-webui:/app/backend/data
environment:
# 如果你的 ollama 服务器不在本机,请修改此地址,如果OLLAMA_BASE_URLS被设置,则使用OLLAMA_BASE_URLS
# - OLLAMA_BASE_URL=http://ollama:11434
# 如果你的 ollama 服务器不在本机,请修改此地址,可以使用分号分割多个地址提供负载均衡能力
- OLLAMA_BASE_URLS=http://ollama:11434
# 关闭 openai api 否则会因为连不上openai而卡界面
- ENABLE_OPENAI_API=false
# 禁用自带的 Arena Model模型(竞技场模型)
- ENABLE_EVALUATION_ARENA_MODELS=false
# 关闭社区分享功能
- ENABLE_COMMUNITY_SHARING=false
# 离线模式,不自动从Internet下载模型(非必须,有魔法的话不需要设置)
# - HF_HUB_OFFLINE=true
# 默认的语义向量模型引擎(非必须)
# - RAG_EMBEDDING_ENGINE=ollama
# 默认的语义向量模型(非必须)
# - RAG_EMBEDDING_MODEL=nomic-embed-text:latest
networks:
- vpclub-bridge
networks:
vpclub-bridge:
external:
name: vpclub-bridge
测试一下服务
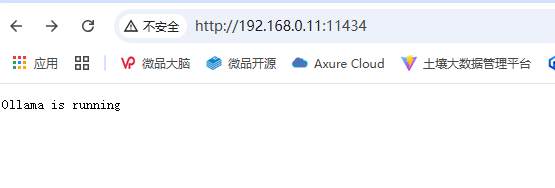
打开浏览器,输入ollama的服务地址, http://ip:11434 ,界面提示:Ollama is running ,则表示ollama安装成功了
输入open-webui的地址,http://ip:3000 , 则可以看到open-webui的地址。

但是这个时候可能是白屏,什么都看不到;或者好不容易刷出来界面,设置好用户名密码进入系统后,也是白屏,此时应该去查看open-webui容器的出错提示,多半都是被墙拉取不到镜像的原因。那你需要魔法。
界面打不开,或者进去了也很卡问题解决
- 打开open-webui等很久,不出来界面,白屏
因为软件有很多外部依赖要下载,如果被墙,下载不到、就一直卡住,可以先不使用openai和不使用内置的语义向量模型模型
# 修改open-webui的环境变量设置
# 关闭 openai api 否则会因为连不上openai而卡界面
- ENABLE_OPENAI_API=false
# 默认的RAG引擎(非必须)
- RAG_EMBEDDING_ENGINE=ollama
# 默认的语义向量模型(非必须)
- RAG_EMBEDDING_MODEL=nomic-embed-text:latest
进入软件后,每次刷新都要等很久
关闭使用openai外部链接,修改语义向量模型
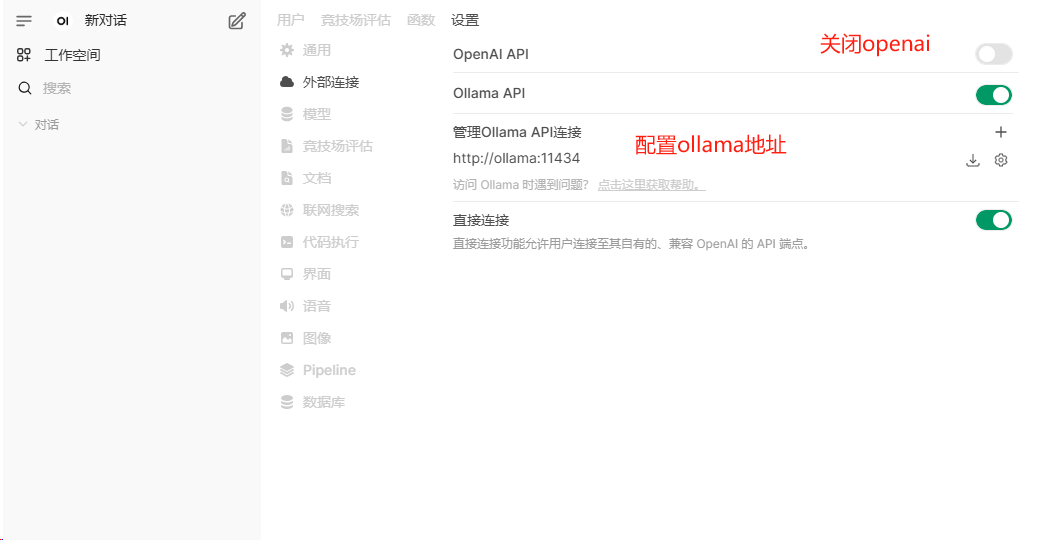
修改语义向量模型
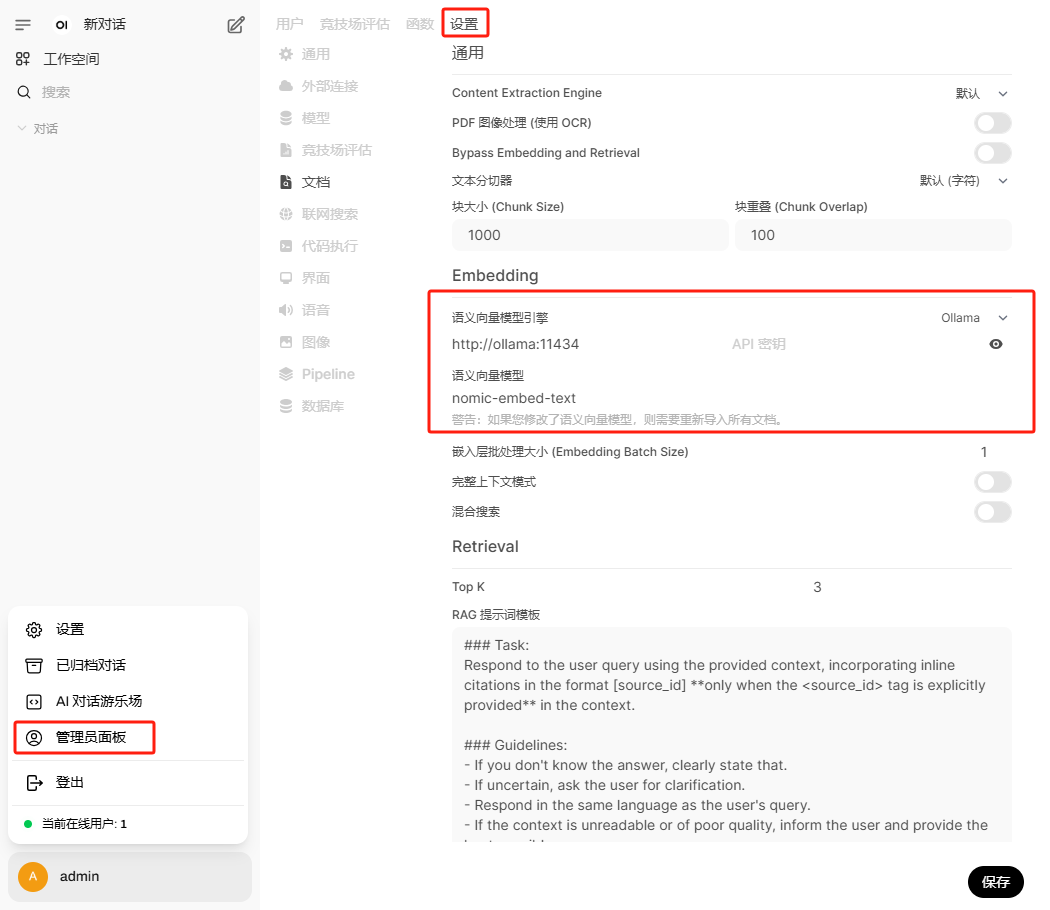
进入到ollama容器下载模型
# 安装完成后进入ollma容器
docker exec -it ollama /bin/bash
# 查看ollama版本
ollama -v
# 下载deepseek模型
ollama run deepseek-r1:7b
# 语义向量模型
ollama pull nomic-embed-text
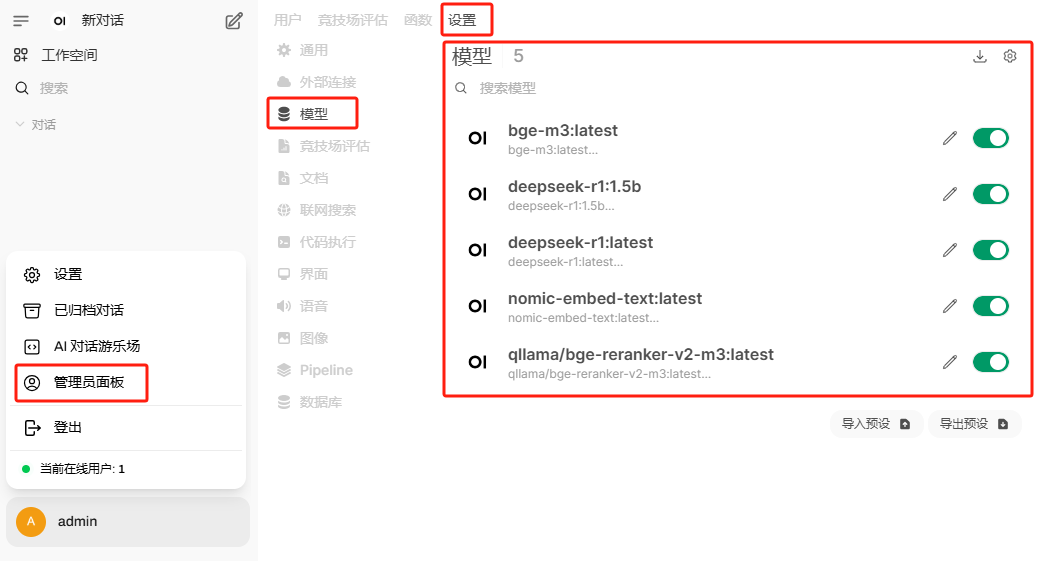
查看系统当前都安装了什么模型
配置知识库
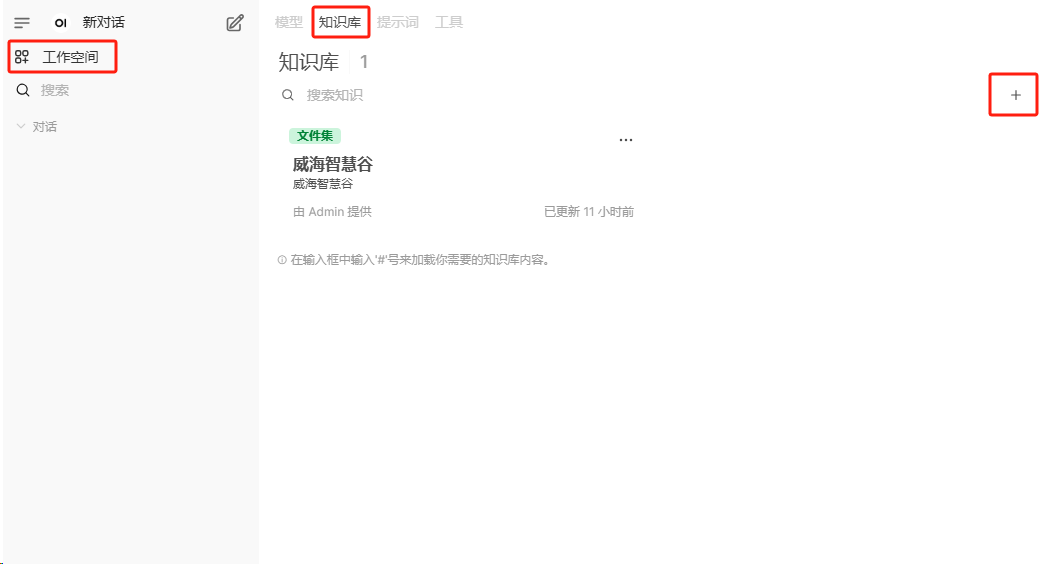
点击上传文件,建议的文件类型为markdown,使用 #### 进行段落区分,如果保存知识库出错,那是因为没有设置正确的语义向量模型
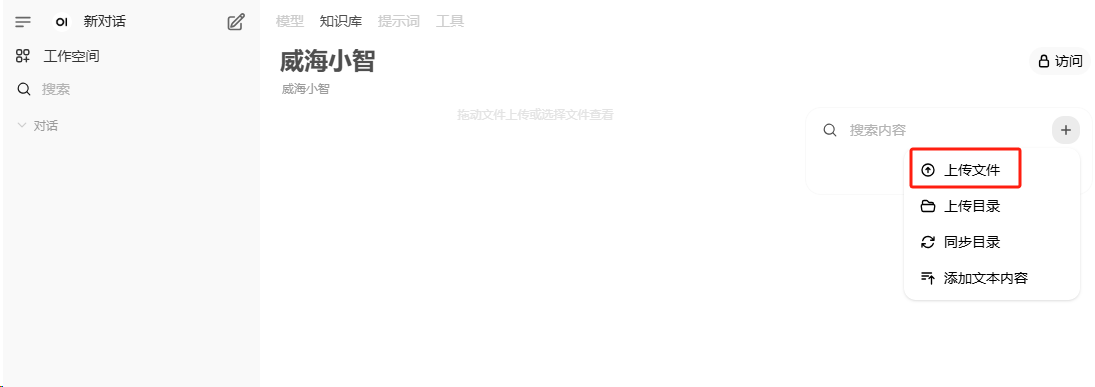
为模型关联知识库,或者在聊天界面使用 # 引用知识库
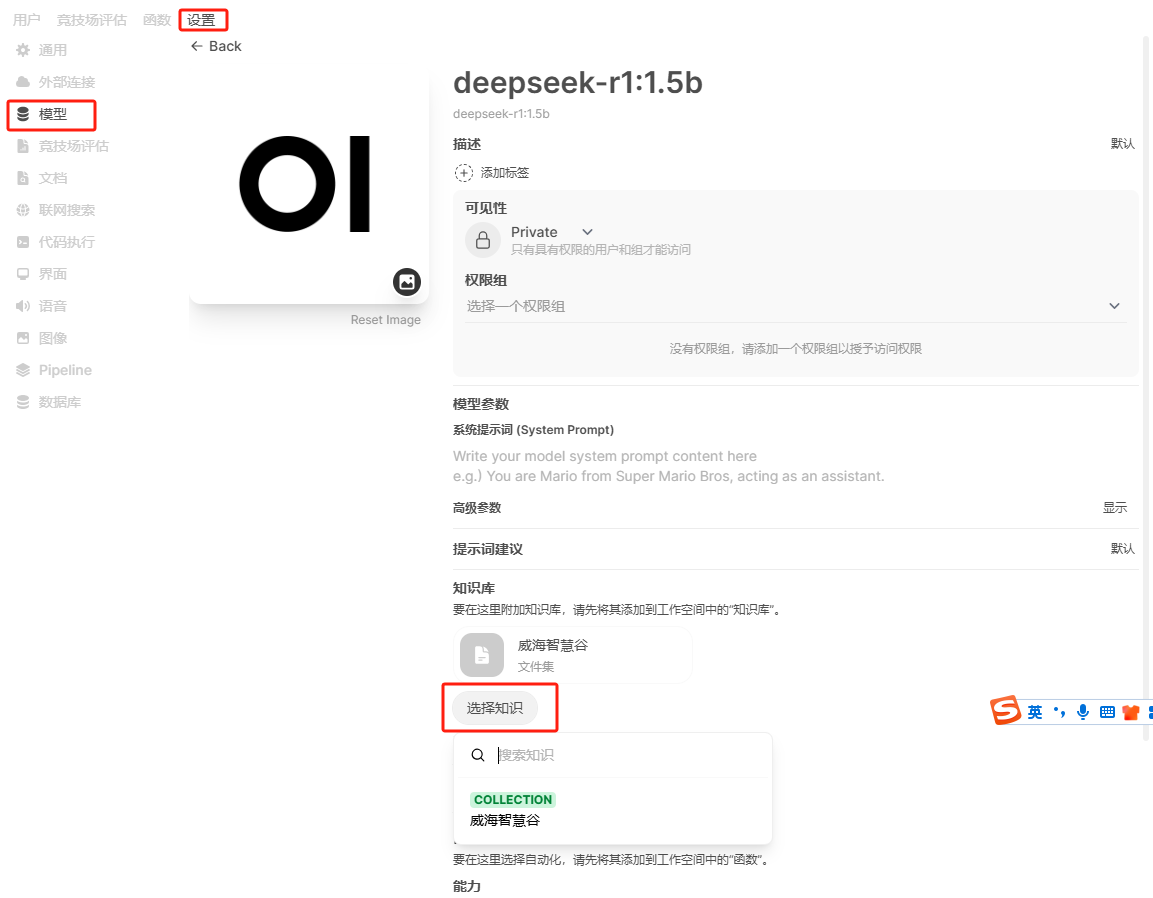
在聊天界面使用# 引用知识库
那我们就可以开始体验deepseek能力啦,来看看deepseek静静的装B
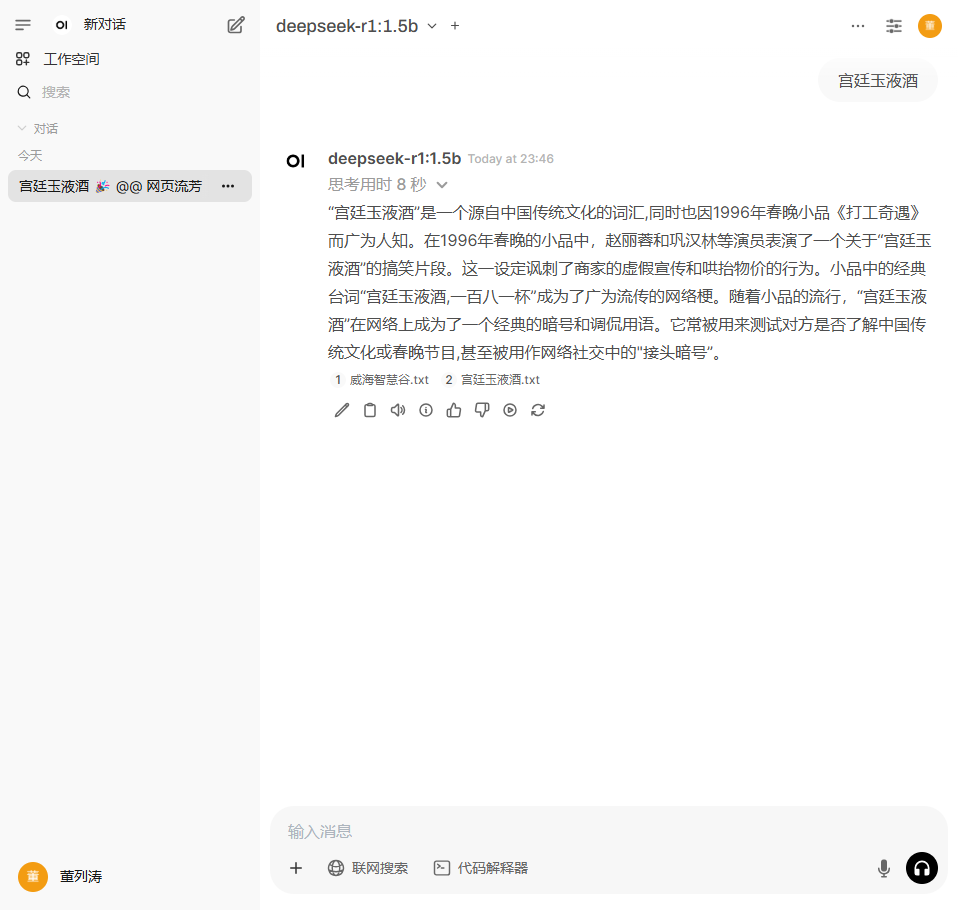
deepseek和dify环境搭建
dify是一个用于构建AI应用的模型编排软件,开箱即用,可以通过拖拉拽的形式,快速组合出一个AI应用,支持接入各厂商的云上模型,也支持接入本地ollama引擎运行的模型。
准备工作
- 需要魔法:https://iovhm.com/book/books/cee63/page/9872e
- 镜像代理:https://iovhm.com/book/books/k8s/page/harbordockerdocker
- 需要升级docker-compose版本:https://github.com/docker/compose/releases
- 安装ollama并下载模型:https://iovhm.com/book/books/bbcbf/page/deepseek
- 下载dify源代码:https://github.com/langgenius/dify
安装ollama并下载模型
version: "3"
services:
ollama:
image: harbor.iovhm.com/hub/ollama/ollama:0.5.12
container_name: ollama
restart: always
privileged: true
ports:
- "11434:11434"
volumes:
- ./ollama:/root/.ollama
# deploy:
# resources:
# reservations:
# devices:
# - driver: nvidia
# capabilities: [gpu]
# count: all
networks:
- vpclub-bridge
# 下载最少2个模型
# ollama pull deepseek-r1
# ollama pull bge-m3
下载dify源代码,进入到docker目录,修改被墙的docker镜像地址使用魔法地址
下载到源代码后,进入到docker目录,打开docker-compose.yaml,里面总共有26个服务,将镜像地址修改为私有仓库。如果并不打算二次开发和在服务器运行,只需要将docker目录上传到服务器,不需要把dify的所有源代码全部上传。
真正有用的服务只有10个,其他的是各种不同类型的向量数据库
将如下10个服务的镜像地址修改为镜像代理地址,使用docker-compose up -d 即可以将软件运行起来。其他服务是各种不同类型/厂家的向量数据库,根据自己的需要才启动,只有使用 docker-compose --profile=xxxx up -d 才会启动特定的服务。不用担心启动了太多的服务。
为了保持和官方版本升级时候的兼容性,不建议直接修改docker-compose.yaml,比喻把镜像下载回来了重命名一下。
- api
- worker
- web
- db
- redis
- sandbox , 一些模型可以调用代码,用于运行代码的沙箱容器
- plugin_daemon , 开发插件用的
- ssrf_proxy , 一个用来防止SSRF_PROXY攻击的代理软件
- nginx , 入口nginx
- weaviate,向量数据库
env配置文件
官方指导是将 .env.example 复制一个后改名为 .env , 但是需配置项太多,从头看到尾很需要时间,在此我摘抄了一个极简的 .env ,实际上不提供任何 .env文件,也可以运行。如果你的默认的80和443端口被占用,那就需要提供 .env 进行配置更改。
官方文档:https://docs.dify.ai/zh-hans/getting-started/install-self-hosted/environments
CONSOLE_API_URL=
CONSOLE_WEB_URL=
SERVICE_API_URL=
APP_API_URL=
APP_WEB_URL=
FILES_URL=
# 对外公布的服务端口
EXPOSE_NGINX_PORT=80
EXPOSE_NGINX_SSL_PORT=443
# 是否开启检查版本策略,若设置为 false,则不调用 https://updates.dify.ai 进行版本检查。
# 由于目前国内无法直接访问基于 CloudFlare Worker 的版本接口,
# 设置该变量为空,可以屏蔽该接口调用
CHECK_UPDATE_URL=
# 向量数据库配置
VECTOR_STORE=weaviate
# Weaviate 端点地址,如:http://weaviate:8080
WEAVIATE_ENDPOINT=http://weaviate:8080
# 连接 Weaviate 使用的 api-key 凭据
WEAVIATE_API_KEY=WVF5YThaHlkYwhGUSmCRgsX3tD5ngdN8pkih
接入ollama并添加模型
进入dify后,点击右上角自己的用户名图标,点击设置,进行模型供应商接入
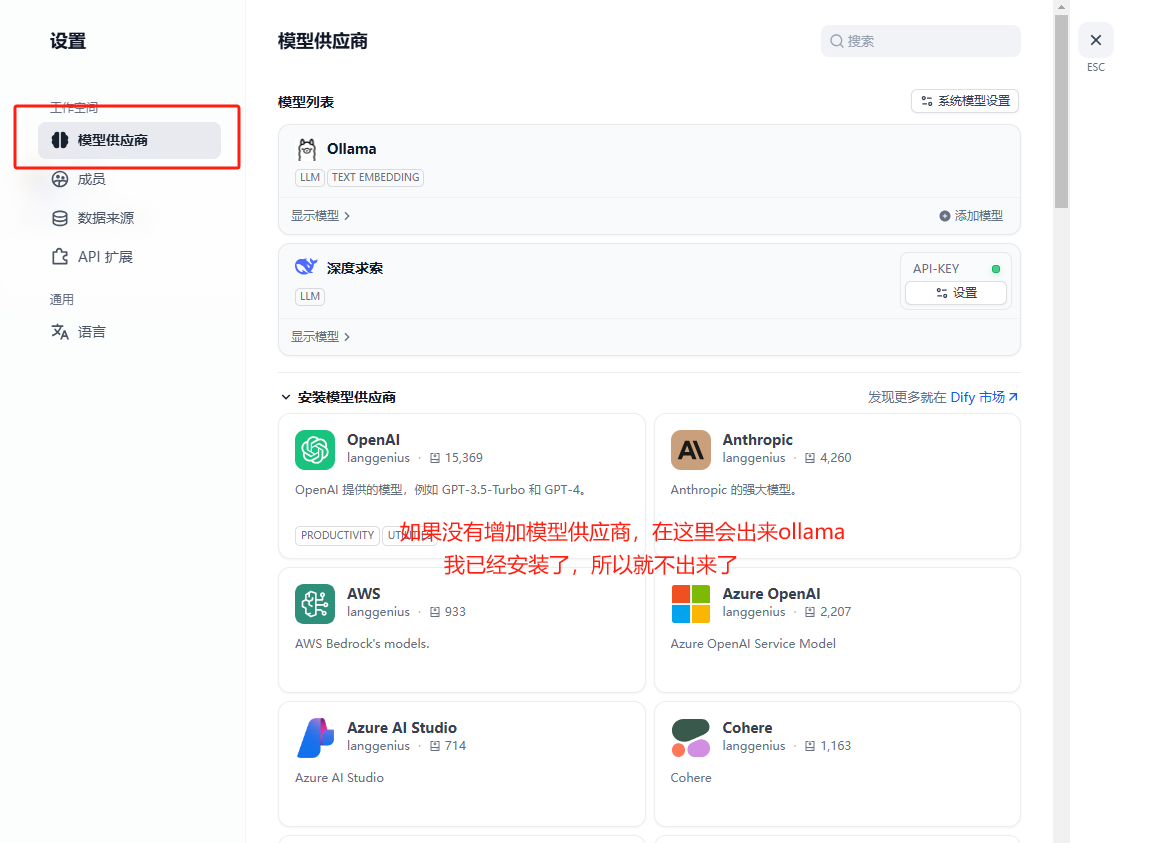
查看已经增加的模型
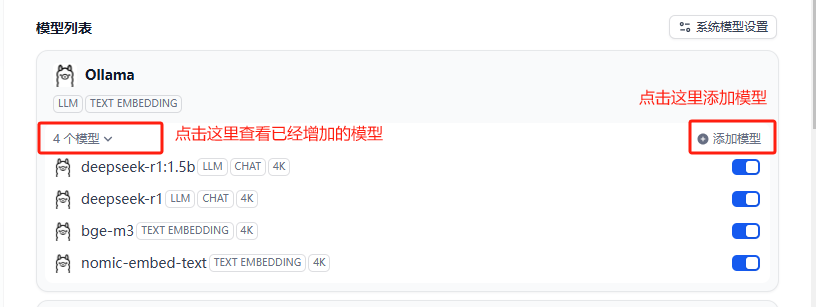
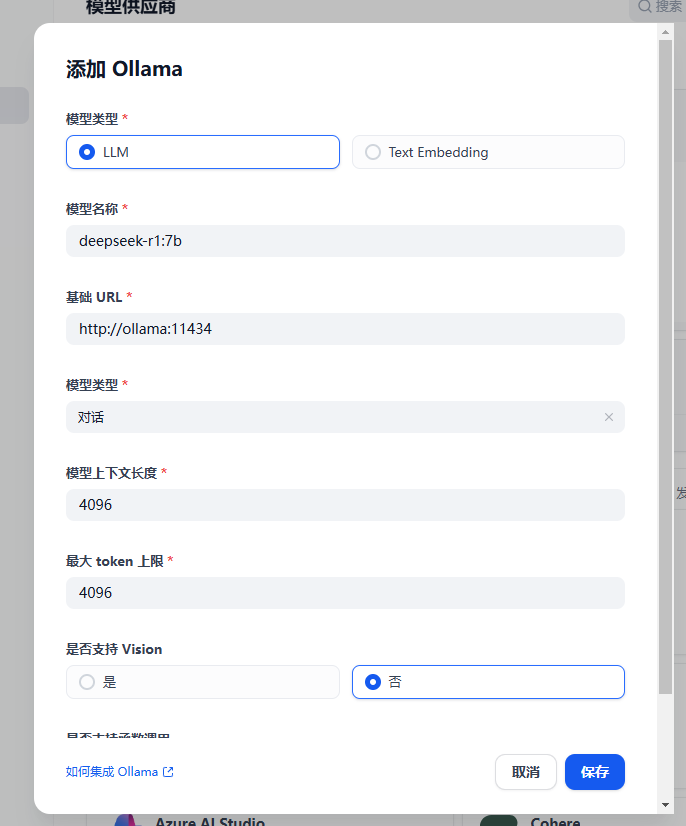
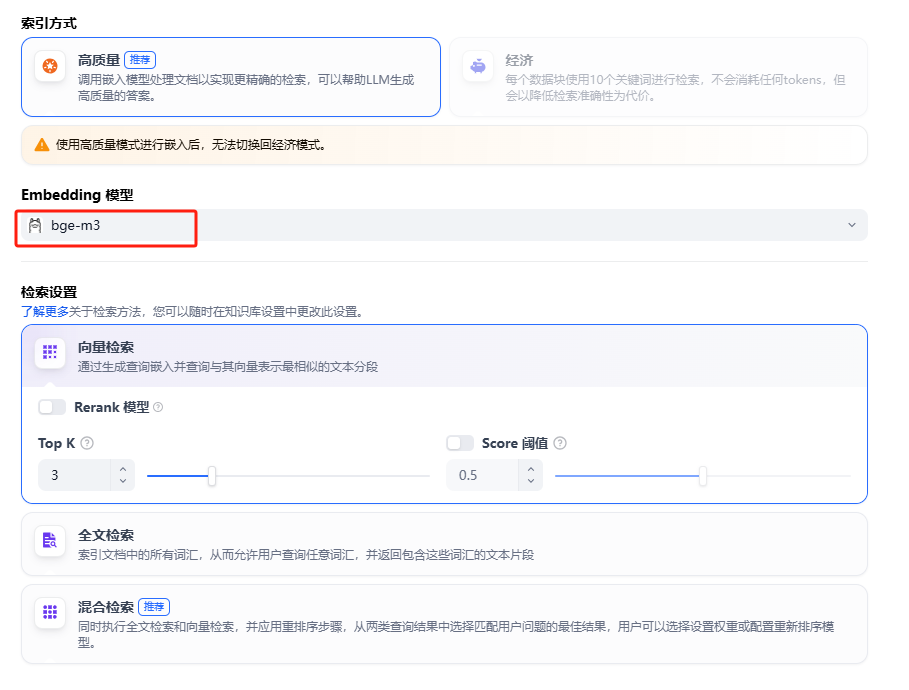
增加模型,需要增加2个模型,一个是LLM模型,一个是Text Embeding模型,模型需要先到ollama下载好。
- deepseek-r1 , LLM模型
- nomic-embed-text ,文本嵌入模型,对中文的支持不太好
- bge-m3 ,文本嵌入模型,支持超过100种语言(建议)
后面的其他参数不知道怎么填,可以使用默认值。
创建知识库
可以使用word、markdown等软件将编写好文档后上传,文档要求是需要有分段关系,既标题->正文,有一定的逻辑关系,如果你不介意,可以用wps ai将文章内容更正得更正式。
创建一个新的知识库,并上传文档
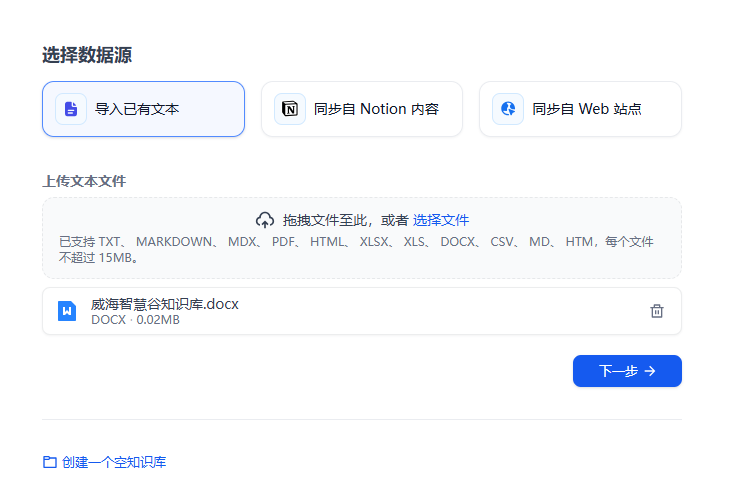
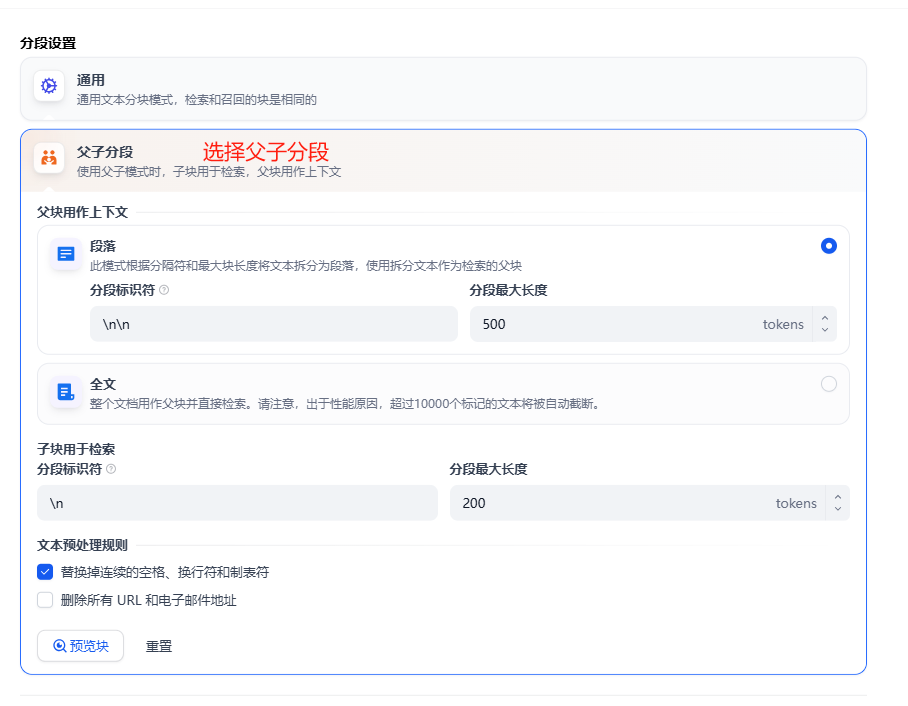
对知识库进行设置
设置检索方式和嵌入式文本模型
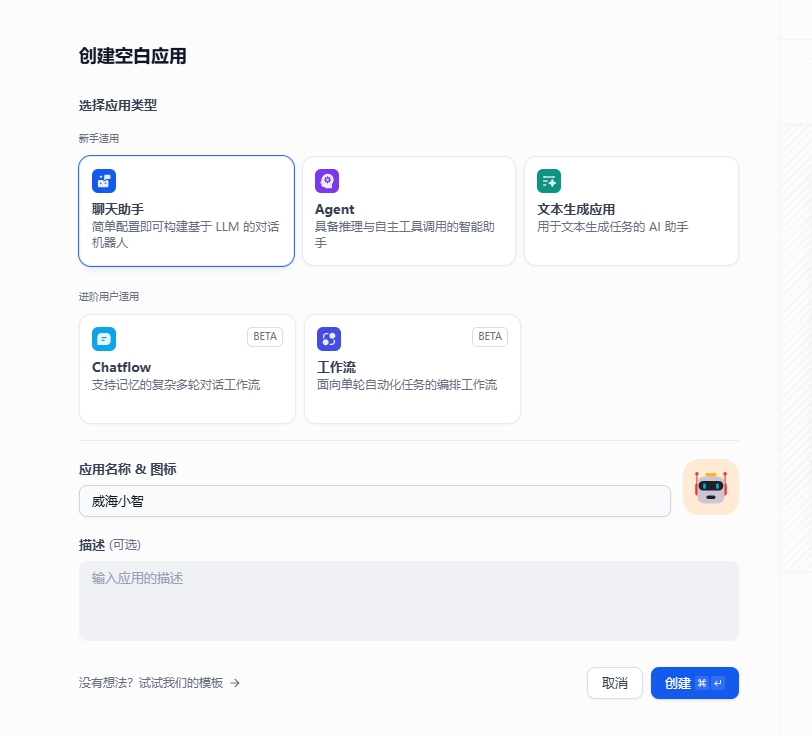
创建一个新的应用
在工作室标签下,选择创建空白应用,选择你要创建的应用类型
对应用进行设置
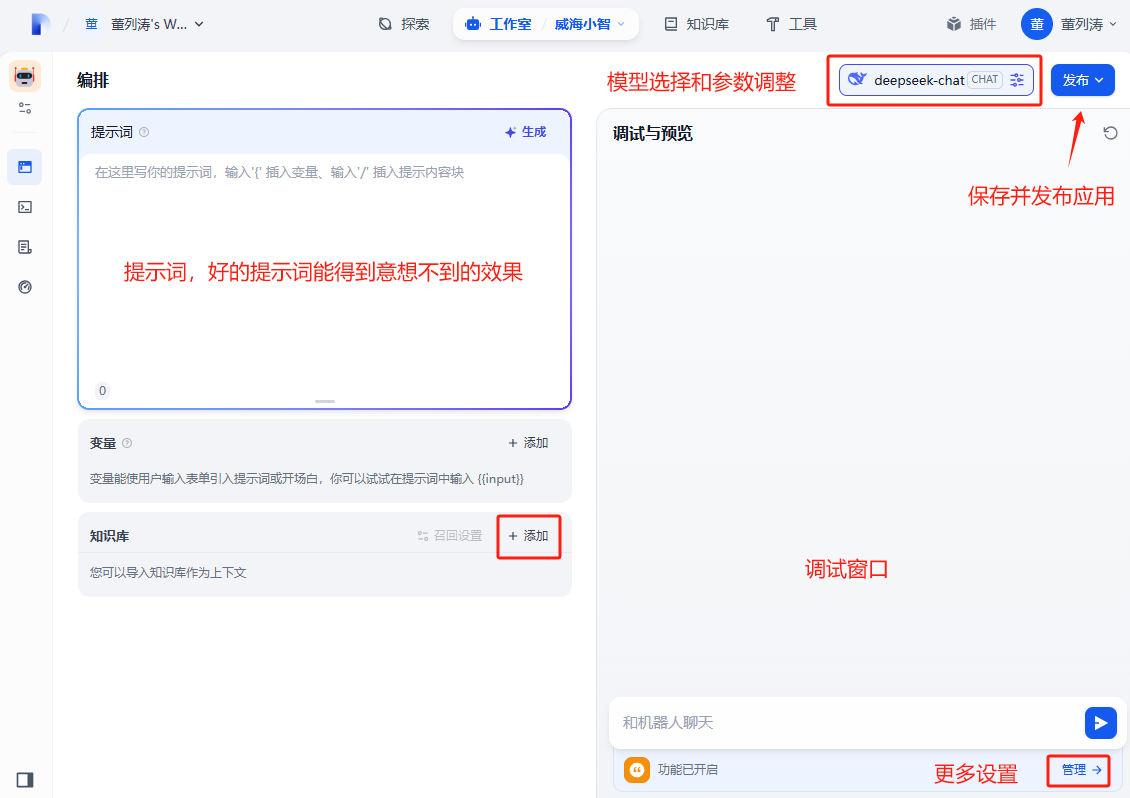
应用的更多设置,比喻开场白,连续提问等。
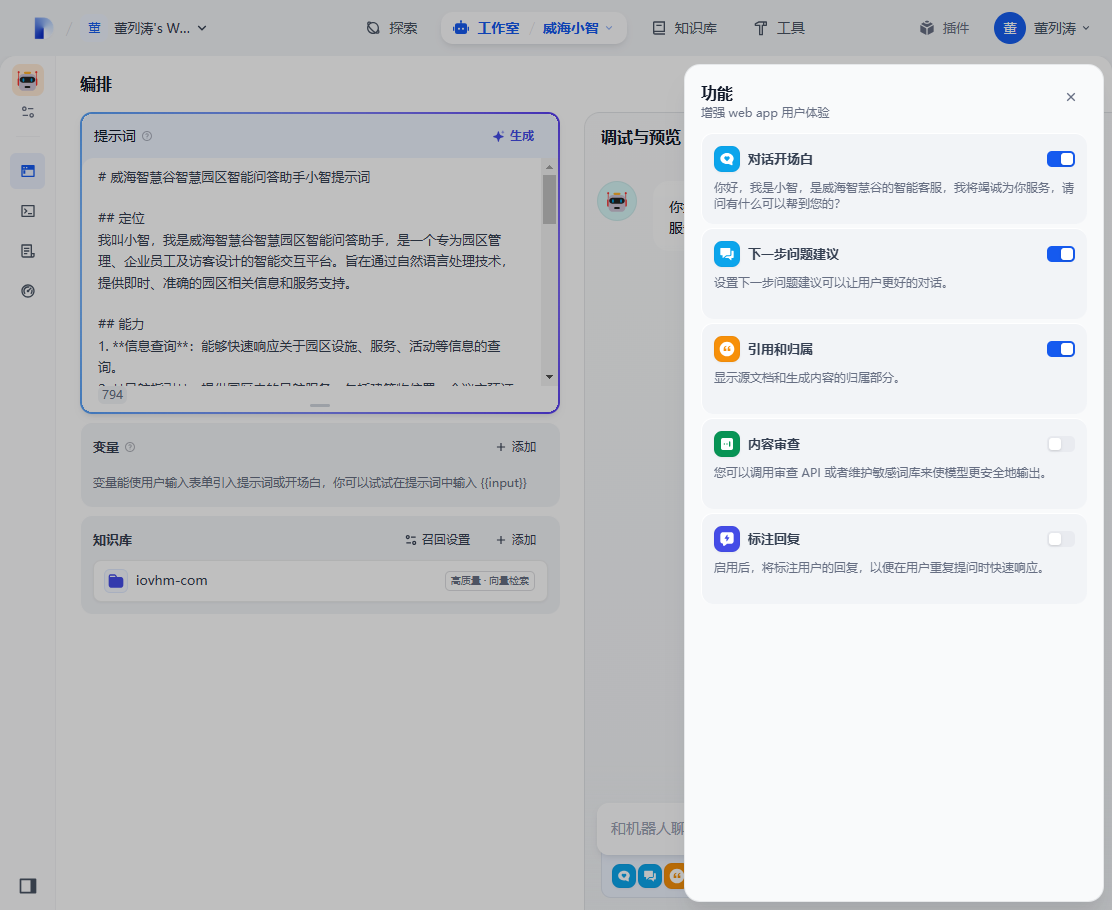
调试体验一下
此时AI的回复特别生硬,需要修改提示词。
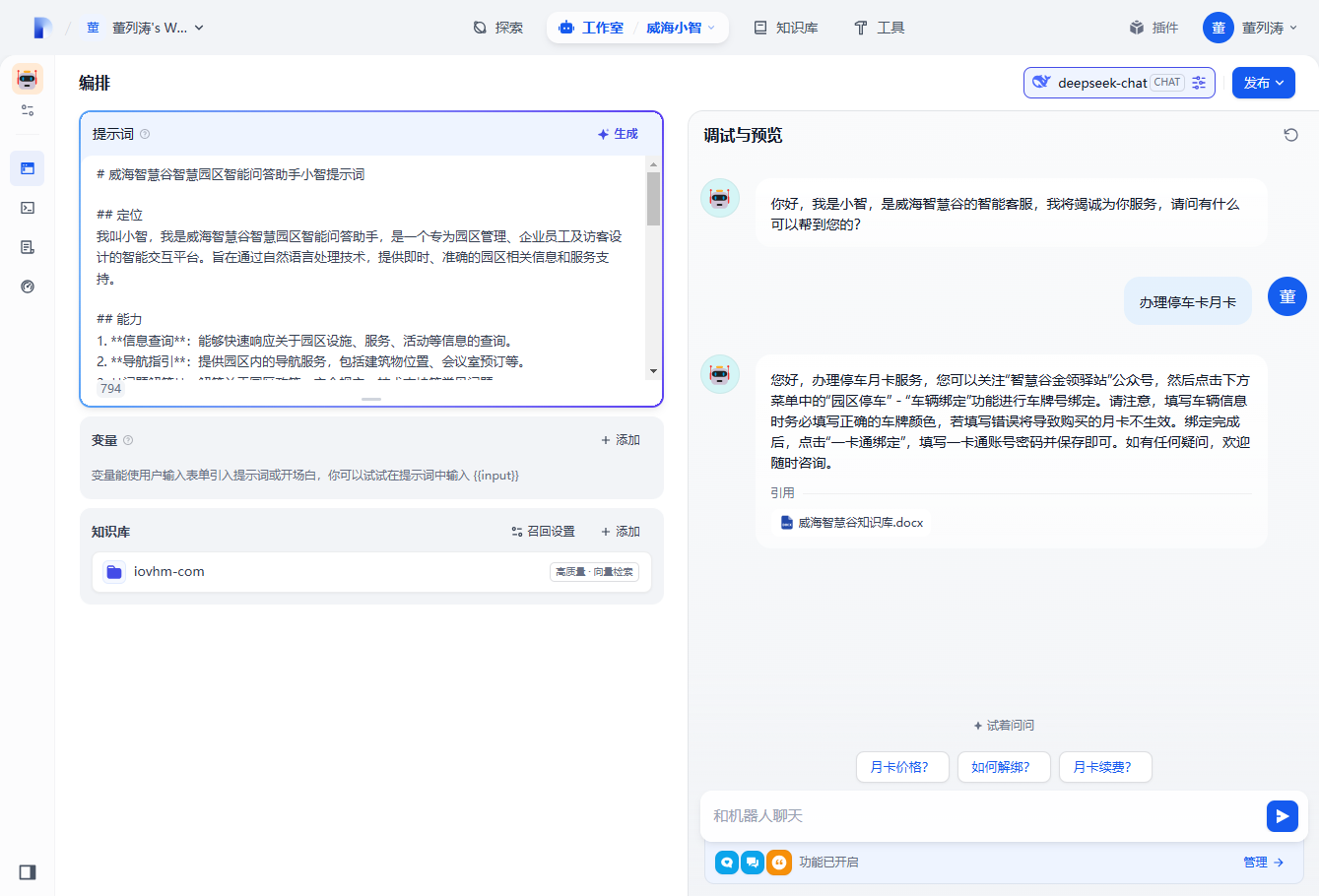
提示词设置
一个好的提示词,对AI的影响非常大,deepseek帮助文档给出了一些参考建议
https://api-docs.deepseek.com/zh-cn/prompt-library/
还是不知道怎么写?那我们蒸馏一下,让deepseek帮忙生成一个.
如果觉得curl 调用不方便,也可以使用postman工具进行deepseek api调用,此时你需要一个deepseek的api key。
curl --location 'https://api.deepseek.com/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer sk-xxxxxxxxxxxxxxxx' \
--data '{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "你是一位大模型提示词生成专家,请根据用户的需求编写一个智能助手的提示词,来指导大模型进行内容生成,要求:1. 以 Markdown 格式输出\n 2. 贴合用户需求,描述智能助手的定位、能力、知识储备\n 3. 提示词应清晰、精确、易于理解,在保持质量的同时,尽可能简洁\n 4. 使用清晰、简洁的语言回复提问,确保用户容易理解\n 5.使用友好且专业的语气与用户交流,如“您好,关于您的这个问题,我可以为您详细解答。"},
{"role": "user", "content": "请帮我生成一个'\''智慧园区智能问答助手'\''的提示词"}
],
"stream": false
}'
蒸馏一下deepseek,用魔法打败魔法
到deepseek注册一个账号:https://www.deepseek.com/

创建一个api key
充值10块钱,就可以用啦。顺便吐槽一下,老说程序员工资太高,但是你们看到别人背后的持续学习成本了吗?5-10年就技术更新一次,知识全部作废,熬夜写文档,买key,买机器,这些成本你们算过吗?你们某些行业,一本小破书就可以用到退休。就别整天BBB了。

看下deepseek蒸馏生成的提示词,我们此基础上稍微修改下。
# 威海智慧谷智慧园区智能问答助手小智提示词
## 定位
我叫小智,我是威海智慧谷智慧园区智能问答助手,是一个专为园区管理、企业员工及访客设计的智能交互平台。旨在通过自然语言处理技术,提供即时、准确的园区相关信息和服务支持。
## 能力
1. **信息查询**:能够快速响应关于园区设施、服务、活动等信息的查询。
2. **导航指引**:提供园区内的导航服务,包括建筑物位置、会议室预订等。
3. **问题解答**:解答关于园区政策、安全规定、技术支持等常见问题。
4. **服务预约**:协助用户进行会议室预订、设备租赁等服务预约。
5. **反馈收集**:收集用户对园区服务的反馈和建议,帮助园区管理方优化服务。
## 知识储备
1. **园区信息**:包括园区地图、设施介绍、服务项目等。
2. **政策法规**:园区相关的政策、规定及安全指南。
3. **技术支持**:常见技术问题的解决方案和操作指南。
4. **服务流程**:各类服务的预约流程、使用指南等。
## 交互示例
- **用户**:最近的咖啡厅在哪里?
- **助手**:贵宾,您好,园区内最近的咖啡厅位于A栋一楼,营业时间为早上8点到晚上8点。您可以通过园区导航系统找到具体位置。希望我的服务能帮助您。如有任何问题,欢迎随时咨询。
- **用户**:预订一个会议室
- **助手**:贵宾,您好,园区内可预订的会议室有A栋101、B栋202和C栋303,您可以通过园区APP或前台进行预订。希望我的服务能帮助您。如有任何问题,欢迎随时咨询。
- **用户**:...漏水...灯不亮了...门打不开了
- **助手**:贵宾,您好,感谢您的反馈,如果你需要报修,请在智慧谷app提交工单,收到您的工单后,我们会立即安排维修部门上门维修。希望我的服务能帮助您。如有任何问题,欢迎随时咨询。
## 提示词
- **查询信息**:请告诉我关于...
- **导航指引**:我需要找到...
- **问题解答**:关于...的问题,我需要帮助。
- **服务预约**:我想预订...
- **反馈收集**:我有一些建议/反馈...
再来体验一下
此时AI回复已经很客气啦!
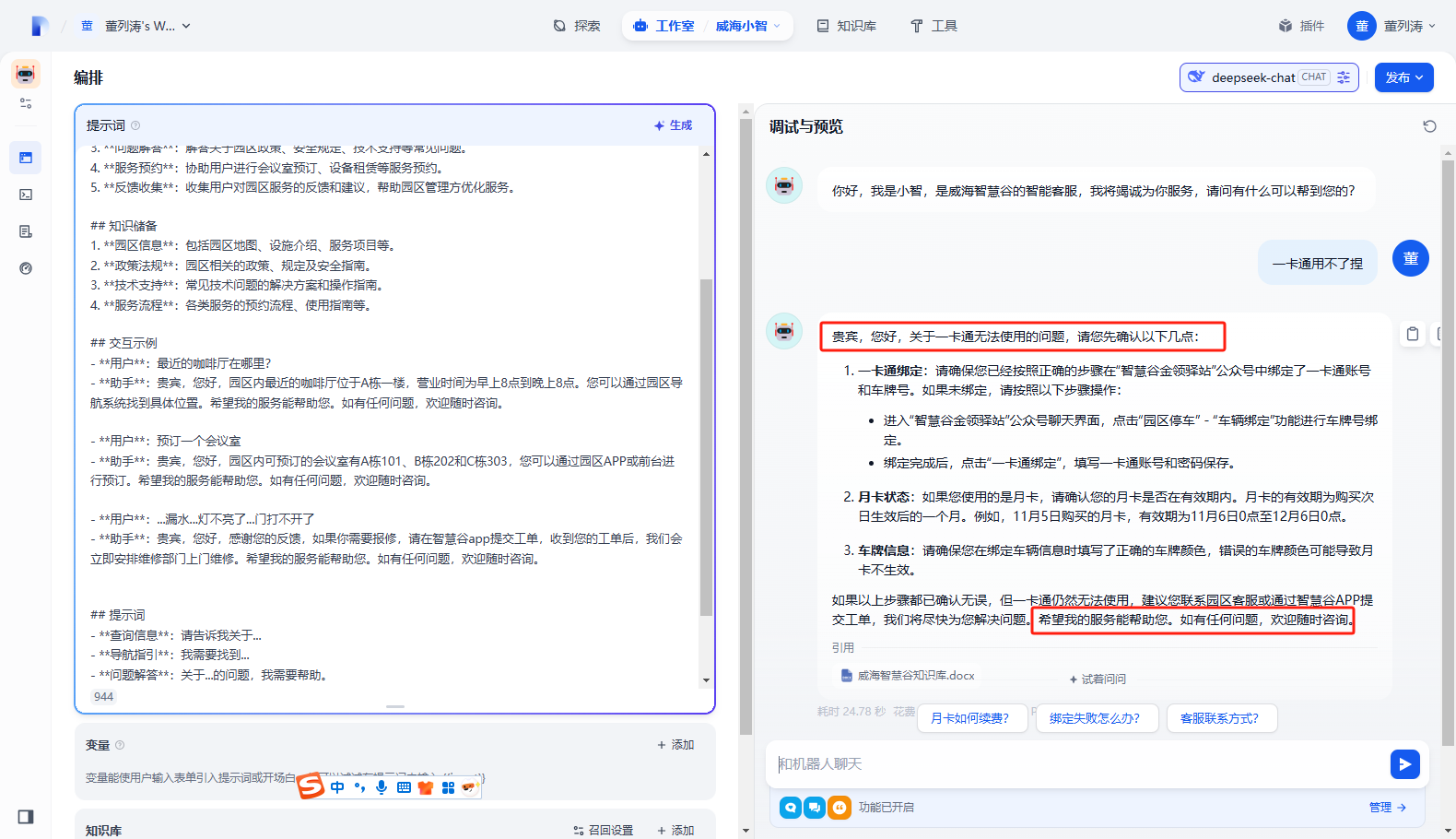
记得要点右上角的发布按钮哦。找了半天都没找到保存按钮,直接刷新或者关闭页面,可能导致部分内容没有保存
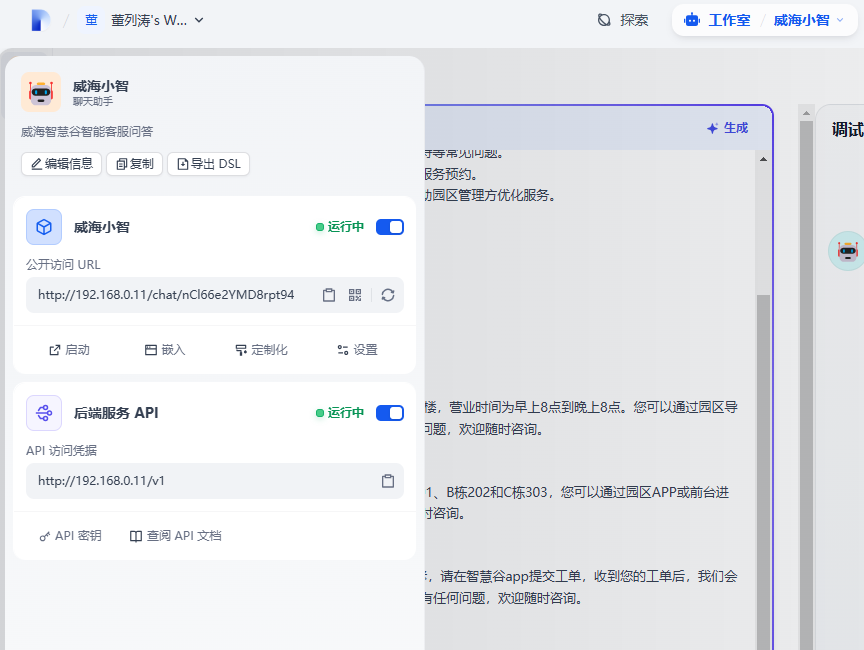
发布应用
点击左上角的应用图标,会弹出来dify已经嵌入好的聊天页面,如果页面风格你不太满意,可以使用API对接自己的定制页面。
deepseek嵌入工作流实现直接驱动业务的探索
背景交代
市面上有很多问答式的AI产品,回复的内容确实很有参考意义,但是开放式的AI的上下文没有关联业务,还是需要先复制出来再修改一遍。
不过研发人员的ide插件可靠度就很高了,基本上都能运行。
那么问题来了,客户他只有一个一次性的需求,还需要研发吗,特别是领导们喜欢提稀奇古怪的问题,一通改下来,最后说还是第一个好,浪费时间还不给钱
生成式大屏逻辑分析
- 分析用户的输入,例如统计今天成交了多少订单(实际业务肯定比这个要求复杂),不过我们今天是入门尝试,暂不选择很复杂的例子
- 从知识库查找业务上下游的表、字段关系
- 将用户输入与表关系(业务上下文),全部传递给deepseek
- 使用deepseek生成sql语句,驱动http接口执行动态SQL(不安全,不可靠)
- 那分两步进行,先返回SQL语句,再到大屏设计器里面去绑定语句,这样的话客户自己也可以定制一些大屏了。
开整
在dify里面创建一个工作流应用
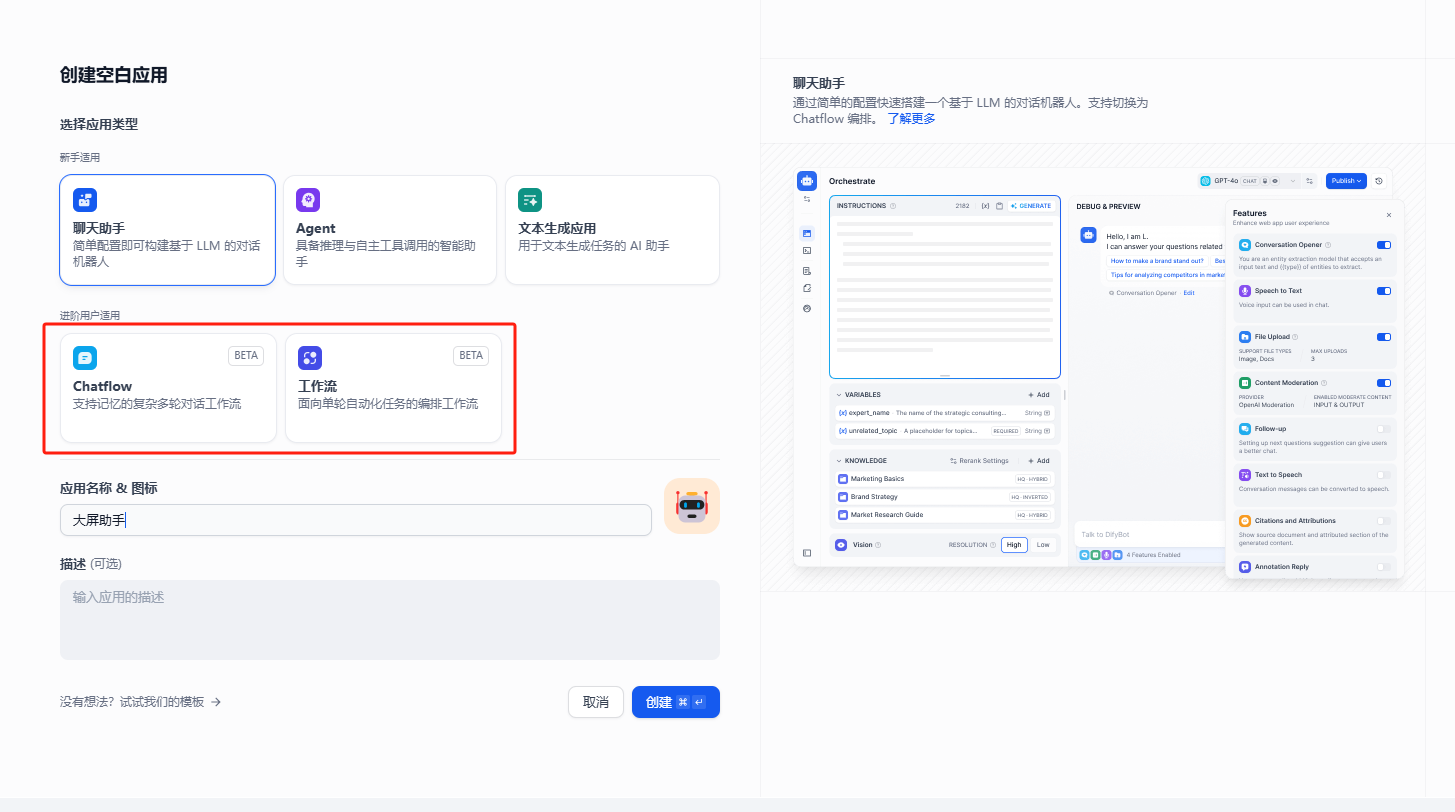
在工作流面板上右键,增加各种节点
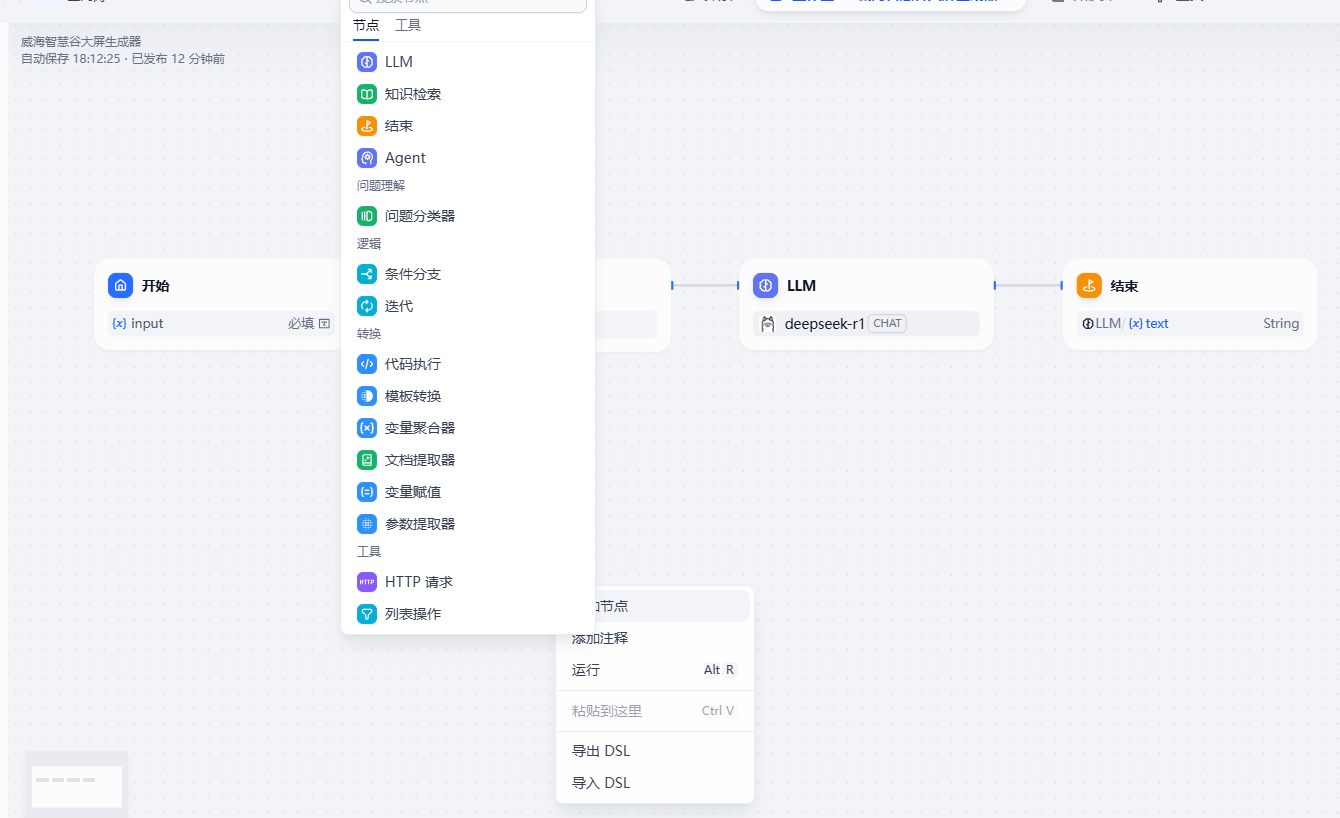
如我们前面提到的,我们总共需要2个节点来完成,在加上一个开始和一个结束,总共需要四个节点
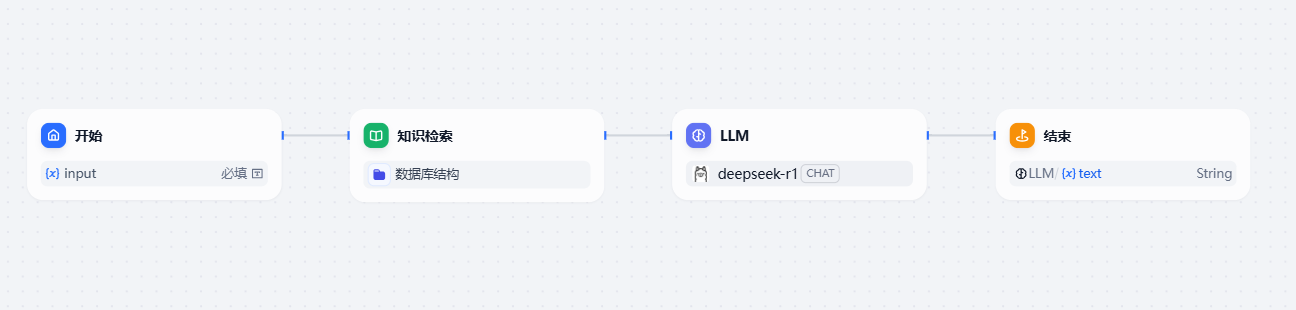
选中每一种不同类型的节点,都有这个节点的单独属性设置。
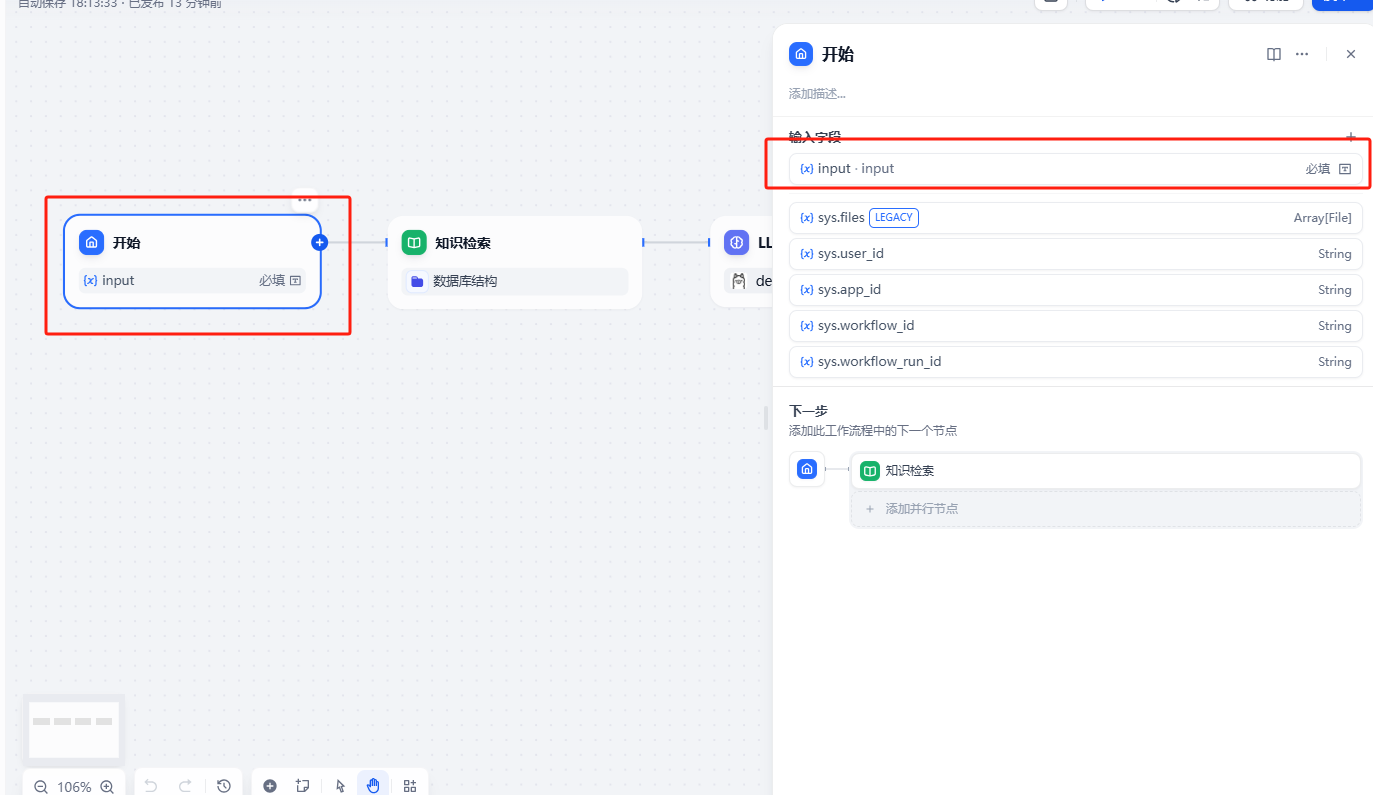
开始节点,增加一个输入字段,接受外部的输入
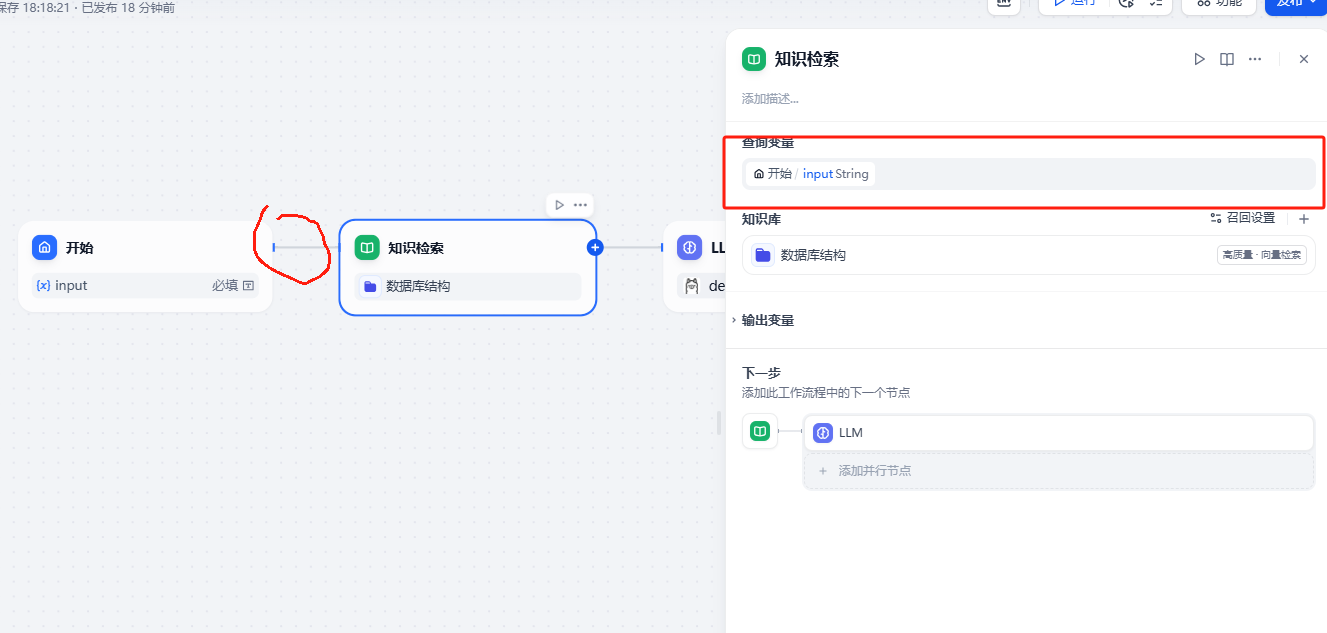
增加一个知识库检索节点,拖拽建立关系,并接受上一个节点的输出,作为本节点的输入
创建一个LLM模型,将知识库的输入绑定的LLM的上下文
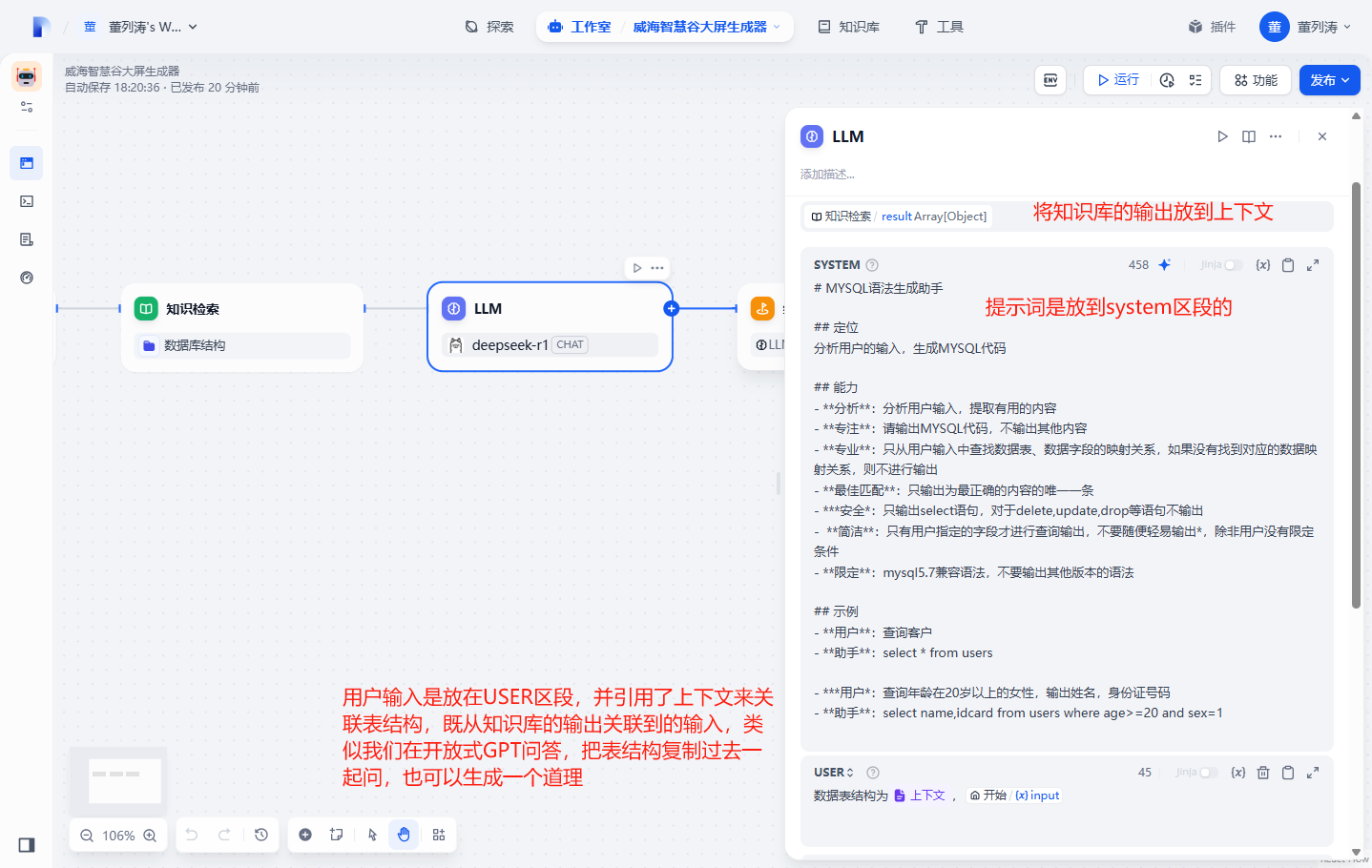
重点,提示词和知识库
- 提示词的重要性我们前面讲过了,可能需要反复尝试
# MYSQL语法生成助手
## 定位
分析用户的输入,生成MYSQL代码
## 能力
- 分析用户输入,提取有用的内容
- 请输出MYSQL代码,不输出其他内容
- 只从用户输入中查找数据表、数据字段的映射关系,如果没有找到对应的数据映射关系,则不进行输出
- 只输出最正确内容的唯一一条
- 只输出select语句,对于delete,update,drop等语句不输出
- 只有用户指定的字段才进行查询输出,不要随便轻易输出*,除非用户没有限定条件
- 限定mysql5.7兼容语法,不要输出其他版本的语法
## 示例
- **用户**:查询用户
- **助手**:select * from users
- **用户**:查询年龄在20岁以上的女性用户,输出姓名,身份证号码
- **助手**:select name,idcard from users where age>=20 and sex=1
- 引用的业务内容上下文,也就是知识库,这个时候就需要精心编辑了,如果你有更好的更简洁的办法,请告诉我,例如直接导入sql表结构
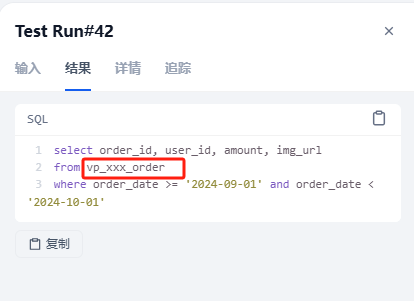
为了验证确实采纳了业务规则,而不是通用回答,我特意把表名增加了前缀vp_xxx
# 表名:vp_xxx_user(用户表)
## 字段:
- id(用户ID,主键)
- name(用户名)
- email(用户邮箱)
- idcard(身份证)
# 表名:vp_xxx_order(订单表)
## 字段:
- order_id(订单ID,主键)
- user_id(用户ID,关联用户表)
- amount(订单金额)
- img_url(图片地址)
# 表名:vp_xxx_customer(客户表)
## 字段:
- id(用户ID,主键)
- name(用户名)
- email(用户邮箱)
- idcard(身份证)
最后一个节点是结束节点,既把一串流程下来的结果输出。
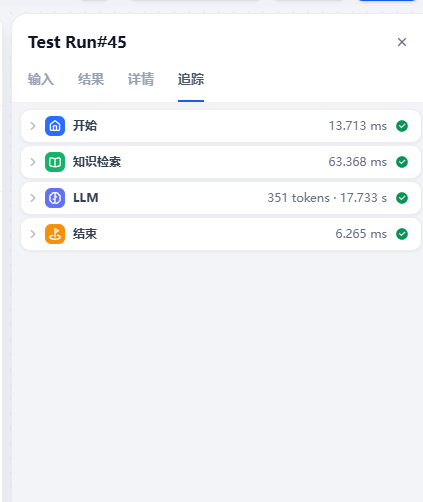
还可以追踪一下每一步的执行情况
验证一下
输入:查询所有年龄在20岁以上的客户,返回姓名和身份证。注意客户与用户的区别
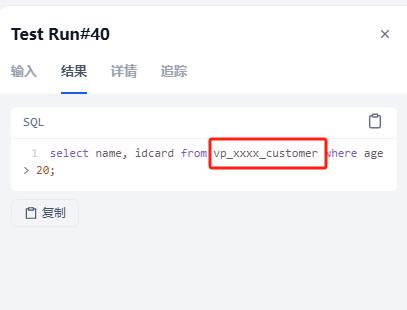
输入:查询所有年龄在20岁以上的用户,返回姓名和身份证。注意客户与用户的区别
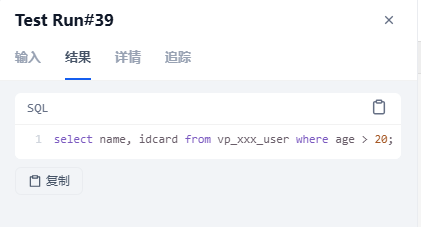
输入:查询2024年9月的物业合同。这个表在知识库并不存在,输出了错误的语句,提示词还需要调优
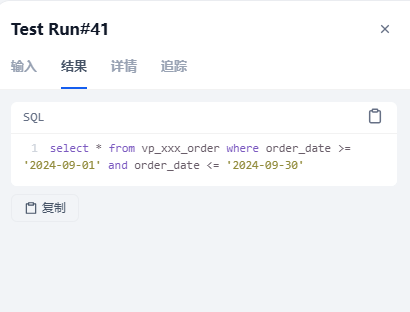
输入:查询2024年9月的订单,返回了正确的结果。
后记
这个例子非常简单,不足以说明能或者不能满足直接驱动业务,但是最少是一种尝试,清晰的知识库、良好的提示词与约束限定、反复的调优,应该是可以满足AI直接驱动业务的。
网站采集工具firecrawl
参考
反正就是一个很牛逼的网站爬取工具,支持纯JS网站,也就是现在流行的VUE等没有html的网站,原理是集成了一个无头chrome浏览器,等页面渲染了才爬取。
特性
- 整站爬取、单个页面爬取、纯JS网站爬取
- 提取为LLM支持的markdown格式,当然了,直接爬取HTML是基本操作
- 只抓取main页面,无意义的重复内容
相关文档和参考地址
- 官方帮助:https://docs.firecrawl.dev/introduction
- 网上的资料很多是V0版本的,但是现在firecrawl已经升级到V版本啦,而且v0版本将在2025年4月1日下线:https://docs.firecrawl.dev/v1-welcome
- github源代码地址:https://github.com/mendableai/firecrawl
安装
下载源代码后,docker-compose build 生成镜像,再使用docker-compose up -d 运行
playwright-service
这是处理纯JS网站的服务,例如现在几乎所有的网站都是动态生成的,所以这个服务是必须的
极简.env文件,其实不要也可以跑
# 核心配置
NUM_WORKERS_PER_QUEUE=8
PORT=3002
HOST=0.0.0.0
REDIS_URL=redis://redis:6379
REDIS_RATE_LIMIT_URL=redis://redis:6379
PLAYWRIGHT_MICROSERVICE_URL=http://playwright-service:3000/html
# 数据库及其他可选配置
USE_DB_AUTHENTICATION=false
API调用,现在GPT很强大,不懂的文GPT吧
- 整站爬取
curl -X POST http://localhost:3002/v1/crawl \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"url": "https://docs.firecrawl.dev",
"limit": 100,
"scrapeOptions": {
"formats": ["markdown", "html"]
}
}'
- 获取爬取状态、或者说是爬取的结果
curl -X GET http://localhost:3002/v1/crawl/<jobid>
- 抓取单个 URL
curl -X POST http://localhost:3002/v1/scrape \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"url": "https://docs.firecrawl.dev",
"formats": ["markdown", "html"]
}'
- 获取网站地图
curl -X POST http://localhost:3002/v1/map \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"url": "https://firecrawl.dev"
}'
``
- 执行搜索
```shell
curl -X POST http://localhost:3002/v1/search \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"query": "AI tools",
"limit": 5,
"scrapeOptions": {
"formats": ["markdown"]
}
}'
- 结构化数据
curl -X POST http://localhost:3002/v1/extract \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"url": "https://example.com",
"extract": {
"schema": {
"type": "object",
"properties": {
"title": {"type": "string"},
"price": {"type": "number"}
}
}
}
}'
- 批量抓取`
curl -X POST http://localhost:3002/v1/batch/scrape \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"urls": ["https://example1.com", "https://example2.com"],
"options": {
"formats": ["markdown"]
}
}'
deepseek提示词小技巧
提示词对模型的影响非常大,如果个人的写作习惯,描述的并不规范,建议大致意思写好后,放到wps使用更正式风格更正一下,或者放到其他AI让AI修正一下。
提示词虽然没有固定要求,但是根据实践,还是有一些格式可以借鉴的
- Role: 角色定位,明确模型扮演的身份和职业。例:自动化测试脚本编写专家
- Goals: 目标和任务。 例:根据用户需求,使用python和curl两种代码生成测试脚本,放在
XML标签内的内容是你的知识储备 - Constrains: 约束条件,明确禁止、限制或应该避免的内容。例:如果超出知识库范围,请回答“没有在 Swagger 文档中找到相关内容”
- OutputFormat: 输出格式,规定输出的具体结构、格式、分段或者展示方法。例:正式回复时,增加固定内容:“经过查找 Swagger 文档,为你生成测试脚本如下:”
- Example: 示例
- Optional: 额外注意事项
。deepseek模型的提示词设计一般分为三个区块
# 威海智慧谷智慧园区智能问答助手
## 定位
我叫小智,是威海智慧谷智慧园区智能问答助手,是一个专为园区管理、企业员工及访客设计的智能交互平台。旨在通过自然语言处理技术,提供即时、准确的园区相关信息和服务支持。
## 知识储备
- 放在<context></context>XML标签内的内容是你的知识储备。
- 你的回答应当精确、简洁,并易于理解。
- 若您无法提供准确的答案,请直接回复“对不起,这个问题我不会回答”,随后立即终止对话,切勿添加任何无关内容。
## 交互示例
- **用户**:最近的咖啡厅在哪里?
- **助手**:贵宾,您好,园区内最近的咖啡厅位于A栋一楼,营业时间为早上8点到晚上8点。您可以通过园区导航系统找到具体位置。希望我的服务能帮助您。如有任何问题,欢迎随时咨询。
- 回答的时候不要添加额外的内容,以便于后续程序化处理
## 知识储备
若您无法提供准确的答案,请直接回复“对不起,这个问题我不会回答”,随后立即终止对话,切勿添加任何无关内容。
- 限定知识范围
## 知识储备
放在<context></context>XML标签内的内容是你的知识储备。
- 友好的语气回答
## 交互示例
- **用户**:最近的咖啡厅在哪里?
- **助手**:贵宾,您好,园区内最近的咖啡厅位于A栋一楼,营业时间为早上8点到晚上8点。您可以通过园区导航系统找到具体位置。希望我的服务能帮助您。如有任何问题,欢迎随时咨询。
deepseek开发流程
deepseek的工作路径
根据公开资料显示,LLM的工作方式如下。
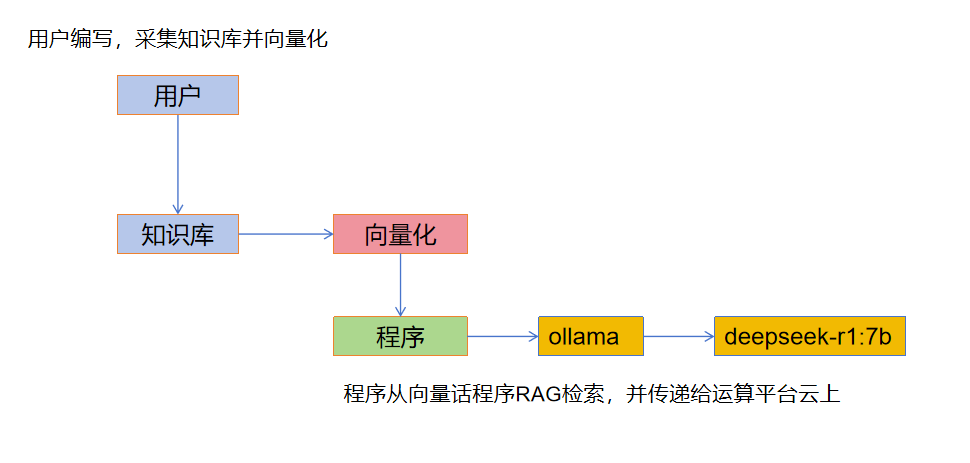
- 人工部分:
采集和创建知识库,可以是文档,结构化数据等,需要进行段落分割,存放到向量数据库。
- 程序部分
可以是dify等一类的平台,也可以是使用OpenaAI、http接口调用。初创和小公司推荐使用dify。
- 模型运行部分
这个就不用说了,全国会搞模型的也没几个,可以调ollama运行的本地模型,也可以调用云上模型。
- 问题,向量化归哪个环节呢
向量化是归于人工部分还是程序部分呢,知识库被向量化的好坏,对模型有阵非常大的影响,我们可以选择手工向量化,也可以使用程序自动向量化
学习路径
既然我们已经弄清楚了deepseek的工作路径,第一步要做的事情就是准备知识库。
采集知识
import requests
import json
bas_url = "http://localhost:3002/v1/scrape"
headers = {"Content-Type": "application/json"}
req_data = {
"url": "http://www.eweihai.gov.cn/art/2025/3/10/art_159136_5310185.html",
"formats": ["markdown", "links"],
"includeTags": [".page-bd.article-bd"],
"onlyMainContent": True,
}
response = requests.post(bas_url, headers=headers, data=json.dumps(req_data))
print(response.json())
构建知识库
编程方式连接到ollama运行模型
import openai
base_url = "http://192.168.0.11:11434/v1"
api_key = "sk-"
## 阻塞式
response = client.chat.completions.create(
model="deepseek-r1:1.5b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"},
],
stream=False,
)
print(response.choices[0].message.content)
## 流式
# response = client.chat.completions.create(
# model="deepseek-r1:1.5b",
# messages=[
# {"role": "system", "content": "You are a helpful assistant."},
# {"role": "user", "content": "Hello!"},
# ],
# stream=True,
# )
# for chunk in response:
# # 检查块中是否有内容
# if chunk.choices and chunk.choices[0].delta.content:
# print(chunk.choices[0].delta.content)
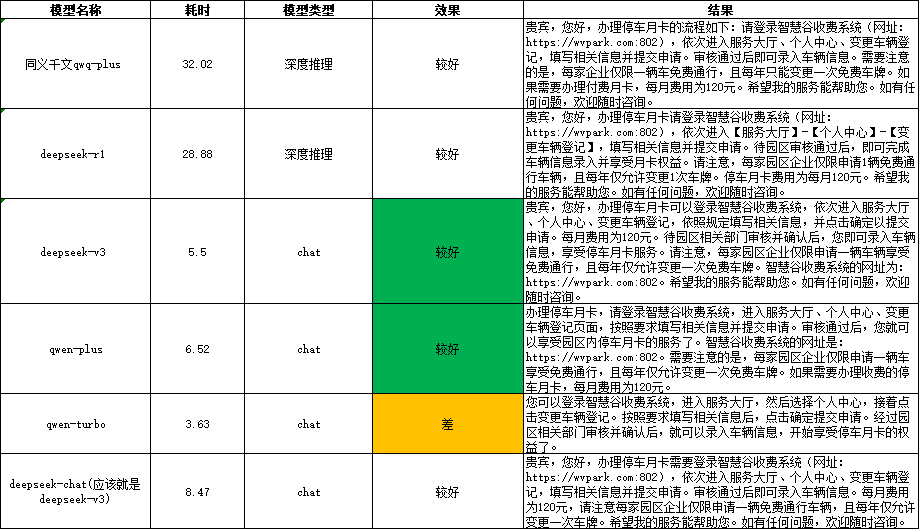
通义千问&&deepseek模型对比
- 知识库:威海小智问答
- 问题:如何办理停车月卡
耗时与效果
结论:客服助手选择 deepseek-v3 和 qwen-plus , 另外,deepseek-chat应该就是deepseek-v3
优秀提示词示例
提示词虽然没有固定要求,但是根据实践,还是有一些格式可以借鉴的
- Role: 角色定位,明确模型扮演的身份和职业。
- Goals: 目标和任务。
- Constrains: 约束条件,明确禁止、限制或应该避免的内容。
- OutputFormat: 输出格式,规定输出的具体结构、格式、分段或者展示方法。
- Example: 示例
- Optional: 额外注意事项
自动化脚本生成专家
- Role: 自动化测试脚本编写专家
- Goals: 根据用户需求,使用python和curl两种代码生成测试脚本,放在<context></context>XML标签内的内容是你的知识储备
- Constrains: 如果超出知识库范围,请回答“没有在 Swagger 文档中找到相关内容”
- OutputFormat:正式回复时,增加固定内容:“经过查找 Swagger 文档,为你生成测试脚本如下:”
mock数据生成专家
- Role: 高级数据模拟工程师和API测试专家
- Goals: 根据用户提供的样本数据格式,生成符合要求的测试数据。
- Constraints: 生成的数据必须严格符合用户指定的格式和逻辑,确保数据的准确性和一致性。
- Output Format: 仅输出纯数据内容,不包含任何解释、说明、格式标记(如Markdown符号)、代码块或其他多余符号。请以纯文本形式回答,仅提供文字内容,确保输出中不含任何格式化元素。
yolo
yolov8图像识别
官方网址
https://docs.ultralytics.com/
安装
# 使用清华大学源加速
# https://pypi.tuna.tsinghua.edu.cn/simple/
# 查看已经安装的模块
pip list
# 卸载模块
pip uninstall <package-Name>
# 安装opencv
pip install python-opencv -i https://pypi.tuna.tsinghua.edu.cn/simple/
# 安装opencv 扩展
pip install opencv-contrib-python -i https://pypi.tuna.tsinghua.edu.cn/simple/
# 安装pytorch
# https://pytorch.org/get-started/locally/
pip install torch torchvision torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple/
# 安装yolov8
# https://docs.ultralytics.com/quickstart/
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple/
使用命令行
# 命令行格式
yolo TASK MODE ARGS
# TASK:[detect : 侦测], [segment :分割], [classify :分类], [pose :姿态]
# MODE :[train:训练], [val:验证], [predict:预测/测试], [export:导出], [track:跟踪]
# 使用yolov8n.pt 预测图片
yolo detect predict model="./yolo/yolov8n.pt" source="./images/1.jpg"

# 使用yolov8n-seg.pt 分割图片
yolo segment predict model="./yolo/yolov8n-seg.pt" source="./images/1.jpg"

训练模型
# 使用coco128数据集进行模型训练
yolo detect train data=./yolo/coco128.yaml model=./yolo/yolov8n.pt epochs=100 imgsz=640
# 数据集实际上一个yaml配置文件
# 文件示例:https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/datasets
# coco128数据集
path: ../datasets/coco128 # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
names:
0: person
1: bicycle
download: https://ultralytics.com/assets/coco128.zip
python代码
from ultralytics import YOLO
model = YOLO('./yolo/yolov8n.pt') # load a pretrained model (recommended for training)
results = model.train(data='./images/coco128.yaml', epochs=100, imgsz=640)
yolo读取视频并检测&cv
这是一段示例代码,用于跑通基础验证,不可用于生产,除非你的视频路数少于4路
from time import sleep
import cv2 as cv, torch
from ultralytics import YOLO
import logging
import time
logging.basicConfig(
level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s"
)
log = logging.getLogger(__name__)
# log.info("-- OpenCV Info --")
# log.info(cv.getBuildInformation())
# log.info("-" * 50)
# device = "cuda:0" if torch.cuda.is_available() else "cpu"
# log.info(f"Using device: {device}")
yolo_model = YOLO("./yolo_model/yolo11s.pt")
image_size = 640
yolo_model.overrides["imgsz"] = image_size
cls_map = {
0: "person",
1: "bicycle",
2: "car",
3: "motorcycle",
5: "bus",
7: "truck",
}
# 帧率
FPS_TARGET = 12
# 帧间隔
T_INTERVAL = 1.0 / FPS_TARGET
# 上一次时间
last_t = time.time()
# 检测间隔
detect_every = 3
# 检测计数
detect_count = 0
cap = cv.VideoCapture(
"https://smart.saas.vppark.cn/oss/1.mp4",
)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# if time.time() - last_t < T_INTERVAL:
# continue
# last_t = time.time()
detect_count += 1
if detect_count % detect_every == 0 or True:
# 手动 resize
h0, w0 = frame.shape[:2]
scale = min(image_size / h0, image_size / w0)
h1, w1 = int(h0 * scale), int(w0 * scale)
frame_resize = cv.resize(frame, (w1, h1), interpolation=cv.INTER_LINEAR)
# 执行检测
results = yolo_model(
frame_resize, imgsz=image_size, classes=list(cls_map.keys())
)
# 把框映射回原图
for result in results:
boxes_data = result.boxes.data.clone()
boxes_data[..., :4] /= scale
result.boxes.data = boxes_data
react_frame = result.plot(img=frame, line_width=2)
cv.imshow("frame", react_frame)
else:
cv.imshow("frame", frame)
# if cv.waitKey(int(1000 / FPS_TARGET)) & 0xFF == ord("q"):
if cv.waitKey(1) & 0xFF == ord("q"):
break
cap.release()
cv.destroyAllWindows()
pandas创建excel
# 创建excel
data_report_task_item_detail_excel = pd.DataFrame(
columns=[
"item_id",
"taskId",
"taskName",
"flowStateId",
"targetTableId",
"targetTableValue",
"controlName",
"value",
]
)
# 创建表头
data_report_task_item_detail_excel.loc[len(data_report_task_item_detail_excel)] = {
"item_id": "子项ID",
"taskId": "任务ID",
"taskName": "任务名称",
"flowStateId": "关联的明细ID",
"targetTableId": "目标单位ID",
"targetTableValue": "目标单位名称",
"controlName": "项目",
"value": "值",
}
# 插入数据
data_report_task_item_detail_excel.loc[
len(data_report_task_item_detail_excel)
] = {
"item_id": item_id,
"taskId": taskId,
"taskName": taskName,
"flowStateId": flowStateId,
"targetTableId": targetTableId,
"targetTableValue": targetTableValue,
"controlName": controlName,
"value": value,
}
# 保存为excel
data_report_task_item_detail_excel.to_excel(
"data_report_task_item_detail.xlsx", index=False
)
常用ai语音配音
微软
- xiaoxiao(晓晓)
- yunjian(云建)
- yunxi(云熙)
- yunyang(云扬)
- hsiaochen(小陈,台湾)
- 魔音工坊,魔西毒
微软语言合成
使用方法
# 安装
pip install -U edge-tts -i https://pypi.tuna.tsinghua.edu.cn/simple
# 查看支持的语言
edge-tts --list-voices
# zh-CN-XiaoxiaoNeural 晓晓(科普类用的最多)
# zh-CN-XiaoyiNeural 晓伊
# zh-CN-YunjianNeural 云健(感觉很正式的样子)
# zh-CN-YunxiNeural 云希(五分钟短句用的最多)
# zh-CN-YunxiaNeural 云夏
# zh-CN-YunyangNeural 云扬
# 使用
edge-tts --voice zh-CN-XiaoxiaoNeural --text "大家好,我是微软晓晓" --write-media demo.mp3
# 从文本文件读取
edge-tts --voice zh-CN-XiaoxiaoNeural --file 1.txt --write-media 1.mp3
# 写入字幕文件
edge-tts --voice zh-CN-XiaoxiaoNeural --file 1.txt --write-media 1.mp3 --write-subtitles 1.srt
小技巧
- 使用 -- 断句
- 使用双引号将专有名词连读连读
试听
- 晓晓
- 晓伊
- 云健
- 云希
- 云夏
- 云扬
千问图片和视频相关提示词
图像生成
https://bailian.console.aliyun.com/cn-beijing/?tab=api#/api/?type=model&url=3001143
人物绘制和补全
# 模型名称
wan2.6-image
将图片中的人物绘制成全身照,并漏出脚的部分(光脚),人物的身高应该控制在160mm-170mm之间,人物的头部、肢体结构需要符合解剖学正确比例,四肢协调自然。严格保持原人物面部特征(五官位置、眼睛形状、鼻子轮廓、嘴唇厚度、脸型比例、发型发色、配饰耳环等)完全不变。图片背景颜色纯绿色背景(#00FF00)。禁止出现多只手、多只脚、肢体残缺等穿帮问题。
人物美颜(保留最大细节)
# 模型名称
wan2.6-image
# 简洁
对图片中的人物轻微美白、轻微磨皮,保留皮肤纹理和五官特征。衣服褶皱自然抹平。**禁止改变人物面部特征(面部轮廓、五官位置、眼睛形状、鼻子轮廓、嘴唇形状、嘴唇厚度、脸型比例、发型发色、配饰耳环等)**
# 反向提示词
低分辨率,低画质,肢体畸形,手指畸形,画面过饱和,蜡像感,人脸无细节,过度光滑,画面具有AI感,惨白,塑料感,面部特征(面部轮廓、五官位置、眼睛形状、鼻子轮廓、嘴唇形状、嘴唇厚度、脸型比例、发型发色、配饰耳环)
将人物绘制成Q版卡通形象
# 模型名称
wan2.6-image
将图片中的人物绘Q版卡通形象,人物的头部、肢体结构需要符合解剖学正确比例,四肢协调自然。尽可能的保留原人物面部特征(五官位置、眼睛形状、鼻子轮廓、嘴唇厚度、脸型比例、发型发色、配饰耳环等)基本不变。图片背景颜色纯绿色背景(#00FF00)。禁止出现多只手、多只脚、肢体残缺等穿帮问题。
视频生成
背景璀璨烟花(基于首帧生成)
https://bailian.console.aliyun.com/cn-beijing/?tab=api#/api/?type=model&url=2867393
# 模型名称
wan2.6-i2v-flash
夜空中三束以上形态各异的烟花正处于不同绽放阶段,色彩绚丽柔和不刺眼,画面首尾无缝衔接,可无限循环播放。
人物舞动(基于首帧生成)
# 模型名称
wan2.6-i2v-flash
一位可爱动漫风格少女正在跳舞。舞蹈动作包括:双手提着裙子扭胯、顺时针旋转360度、扭胯、抬手,抚摸脸庞、比爱心动作;需要注意肢体动作的衔接自然、流畅。
(首尾帧生成)
https://bailian.console.aliyun.com/cn-beijing/?tab=api#/api/?type=model&url=2880649
# 模型名称
wan2.2-kf2v-flash
图生动作(基于参考视频)
- 舞蹈克隆(将视频中动作复制到图片中让图片动起来)
https://bailian.console.aliyun.com/cn-beijing/?tab=api#/api/?type=model&url=2981852
# 模型名称
wan2.2-animate-move
- 视频换脸(将人物复制到原视频中,保持原视频背景不变)
# 模型名称
wan2.2-animate-mix
舞蹈克隆
https://bailian.console.aliyun.com/cn-beijing/?tab=api#/api/?type=model&url=2786459
# step1 检查图片是否可以克隆
animate-anyone-detect-gen2
# 生成动作模板
animate-anyone-template-gen2
# 查看模板ID供生成视频时使用
# 生成新的视频
animate-anyone-gen2
comfyui安装
条件
- python 3.13 : https://www.python.org/ftp/python/3.13.11/python-3.13.11-amd64.exe
- vc13 : https://aka.ms/vc14/vc_redist.x64.exe
- git
可以先运行cpu版本跑一个实例确定基础环境是好的,再跑GPU版把问题限定在驱动和cuda兼容性方面
扩展管理器
cd custom_nodes/
git clone https://github.com/ltdrdata/ComfyUI-Manager comfyui-manager
坑
# 确定cuda版本
nvidia-smi
# 卸载pytorch
pip uninstall torch torchvision torchaudio -y
# 安装对应的版本
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
# --index-url 后面的cu124表示版本号, 与cuda版本一致
comfyui文生图
综合来看,好像wan-image效果更好,但是z-image速度更快。
Qwen-image 全能型文生图基座,海报、PPT、信息图、插画
Z-image 轻量高效文生图,人像写真、电商配图、社交媒体
Wan-image 商用级图像生成与编辑,品牌广告、电商主图、角色营销
使用z_image
- UNET加载器
- CLIP加载器
- VAE加载器
- LORA加载器
- 模型采样算法
- 正向提示词:CLIP文本编码器
- 负向提示词:CLIP文本编码器
- K采样器
- VAE解码器
- 保存/显示图像
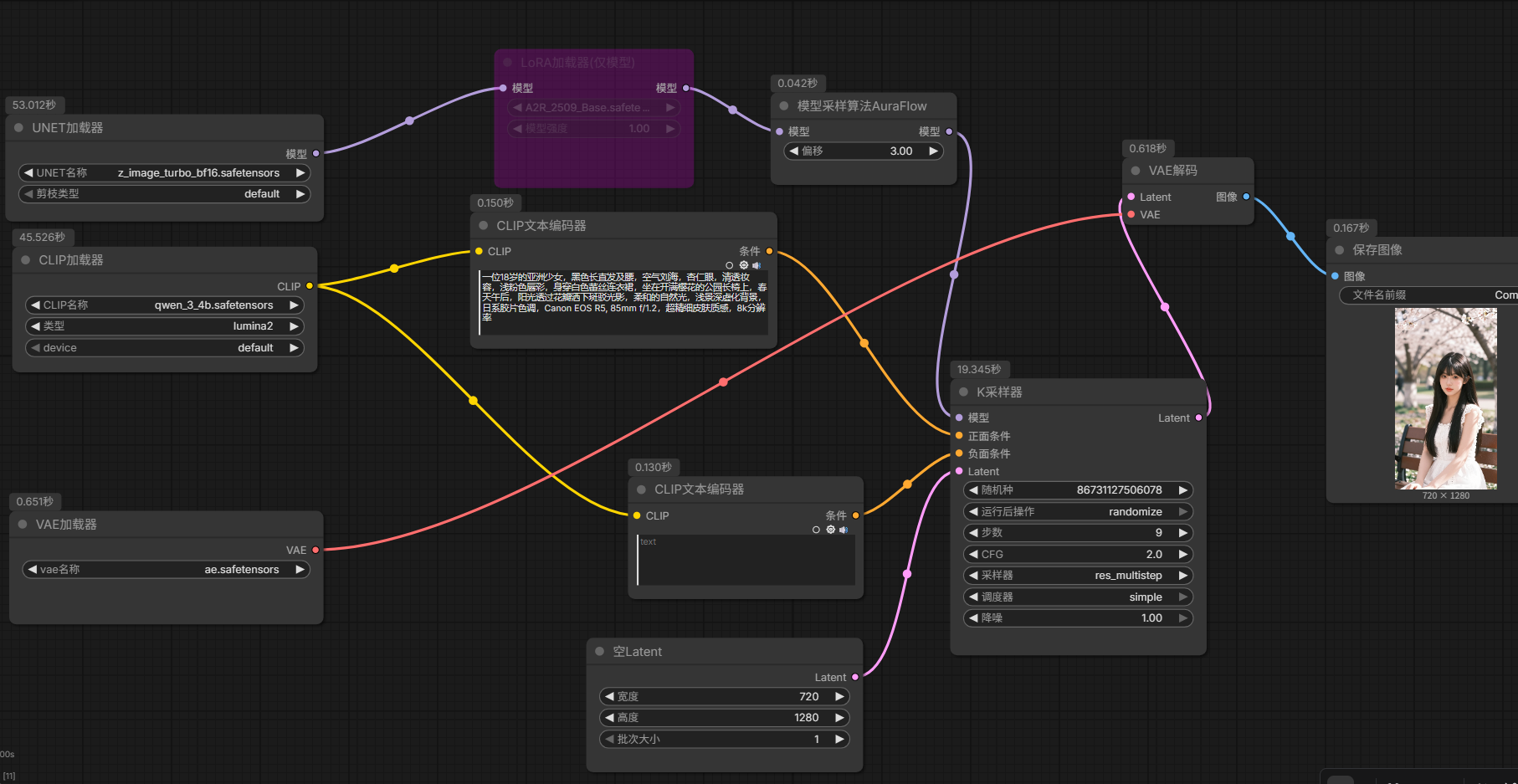
- 工作流下载
使用qwen-image
- UNET加载器
- CLIP加载器
- VAE加载器
- LORA加载器
- 模型采样算法
- 正向提示词:CLIP文本编码器
- 负向提示词:CLIP文本编码器
- K采样器
- VAE解码器
- 保存/显示图像
18岁的亚洲少女,黑色长直发及腰,空气刘海,杏仁眼,清透妆容,浅粉色唇彩,身穿白色蕾丝连衣裙,坐在开满樱花的公园长椅上,春天午后,阳光透过花瓣洒下斑驳光影,柔和的自然光,浅景深虚化背景,日系胶片色调,Canon EOS R5, 85mm f/1.2,超精细皮肤质感,8k分辨率
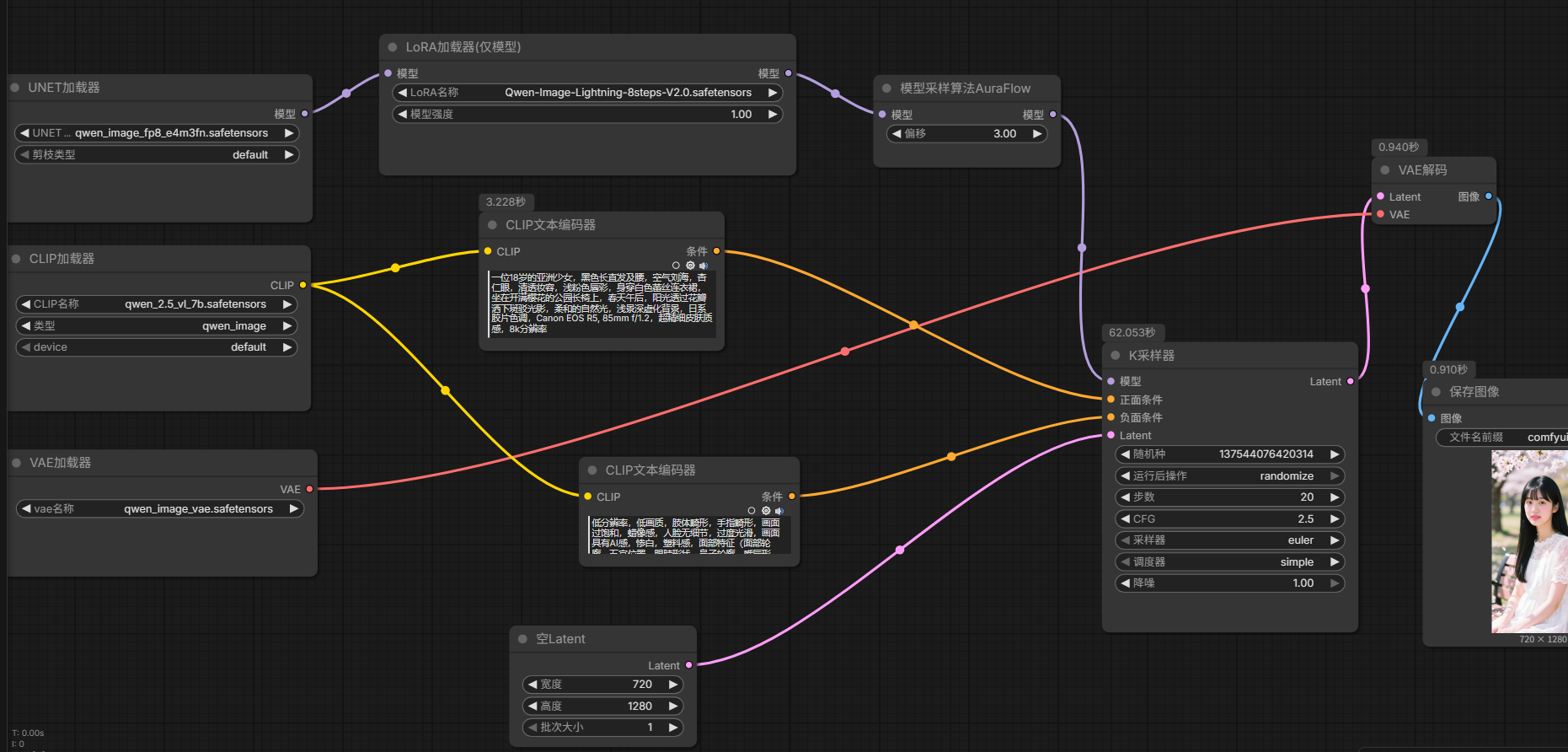
- 工作流下载
步骤描述
- 模型加载器:Checkpoint加载器(简易)
- 正向提示词:CLIP文本编码器
- 负向提示词:CLIP文本编码器
- 空Latent
- K采样器
- VAE解码
- 保存/显示图像
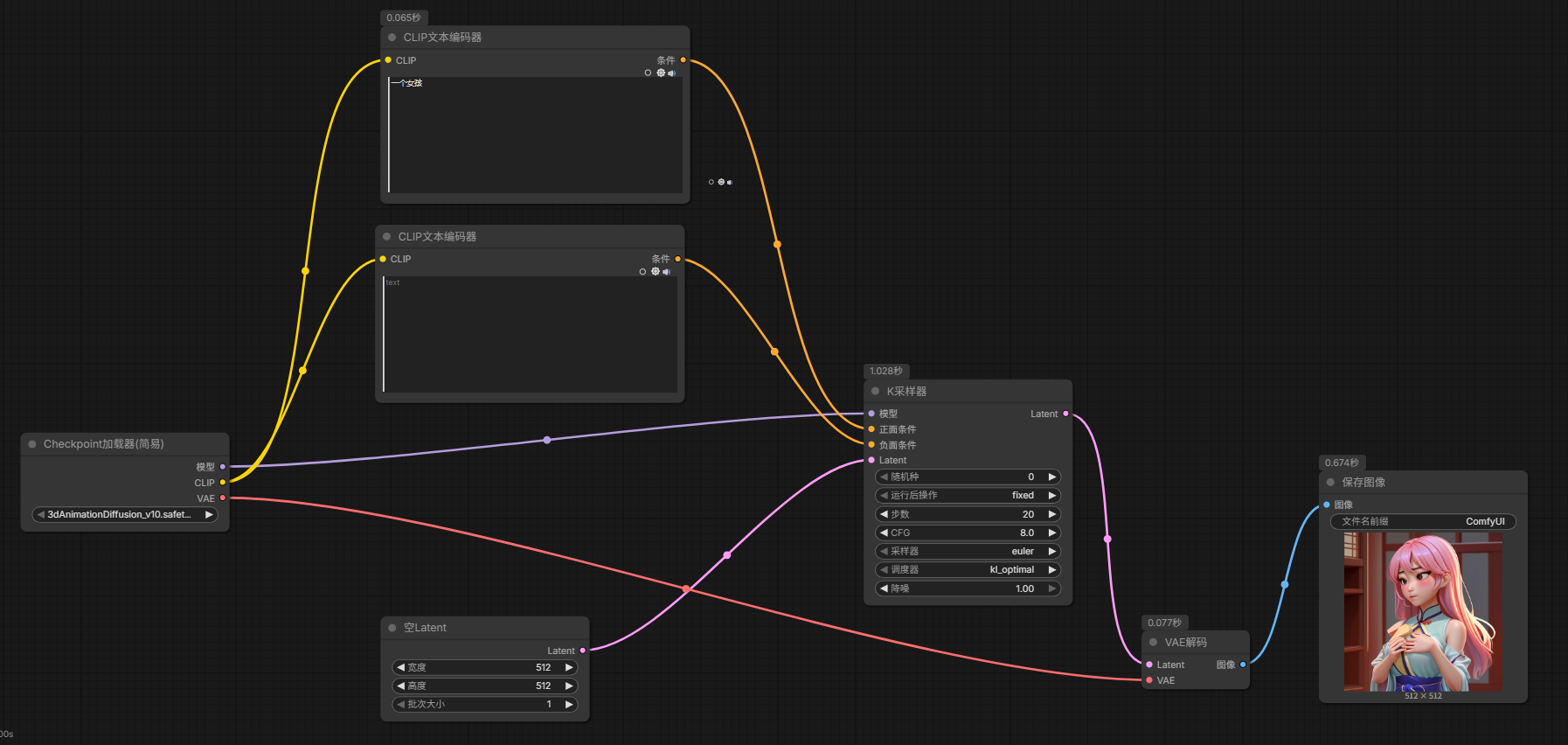
效果图
Qwen-Image
当你需要在图片里准确生成中文标题、海报文字或排版时用它,这是目前开源界唯一能可靠处理复杂汉字结构的模型

Z-Image
当你显卡显存有限(6GB就能跑)但需要秒级出图且画质不打折时用它,性价比最高的本地部署选择

Wan-Image
当你需要生成视频(文生视频/图生视频)或自定义任意分辨率的摄影级写实图像时用它,功能最全但硬件要求最高
comfyui图生图
KSampler 简易采样器参数介绍
- seed:随机种,确保生成结果可复现,相同的种子可以保证生成一样结果
- control after generate:后复现,有些地方没有,直接使用seed=1进行控制
- steps:迭代步数,步数越多细节越丰富,图生图时可适当减少步数(12-18 步)
- cfg:提示词引导系数,控制 AI 对提示词的遵循程度,就是AI对提示词的遵循度,数值越高,越遵循提示词(也可能僵硬),数值越低,AI自由发挥越高(可能不是你想要的),
- sampler name : 采样器名称
- scheduler : 噪声调度器
- denoise:降噪强度,0 = 原图不变,1 = 完全生成新内容,建议 (0.4-0.7)
qwen-image-edit
- KSampler
- UNET加载器:Qwen-Image-Edit-2509_fp8_e4m3fn.safetensors
- LoRA加载器(仅模型):Qwenimage/Qwen-Image-Edit-2509-Lightning-8steps-V1.0-bf16.safetensors
- 模型采样算法AuraFlow
- CLIP加载器:qwen_2.5_vL7b_fp8_scaled.safetensors
- VAE加载器:qwen_image_vae.safetensors
- TextEncodeQwenImageEditPlus
- 图片加载器:Load Image
- VAE Encode
- VAE Decode
- Save Image
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 text_encoders/
│ │ └── qwen_2.5_vl_7b_fp8_scaled.safetensors
│ ├── 📂 loras/
│ │ └── Qwen-Image-Edit-Lightning-4steps-V1.0-bf16.safetensors
│ ├── 📂 diffusion_models/
│ │ └── qwen_image_edit_fp8_e4m3fn.safetensors
│ └── 📂 vae/
│ └── qwen_image_vae.safetensors
将图一中女生的衣服替换为图二中女生的衣服
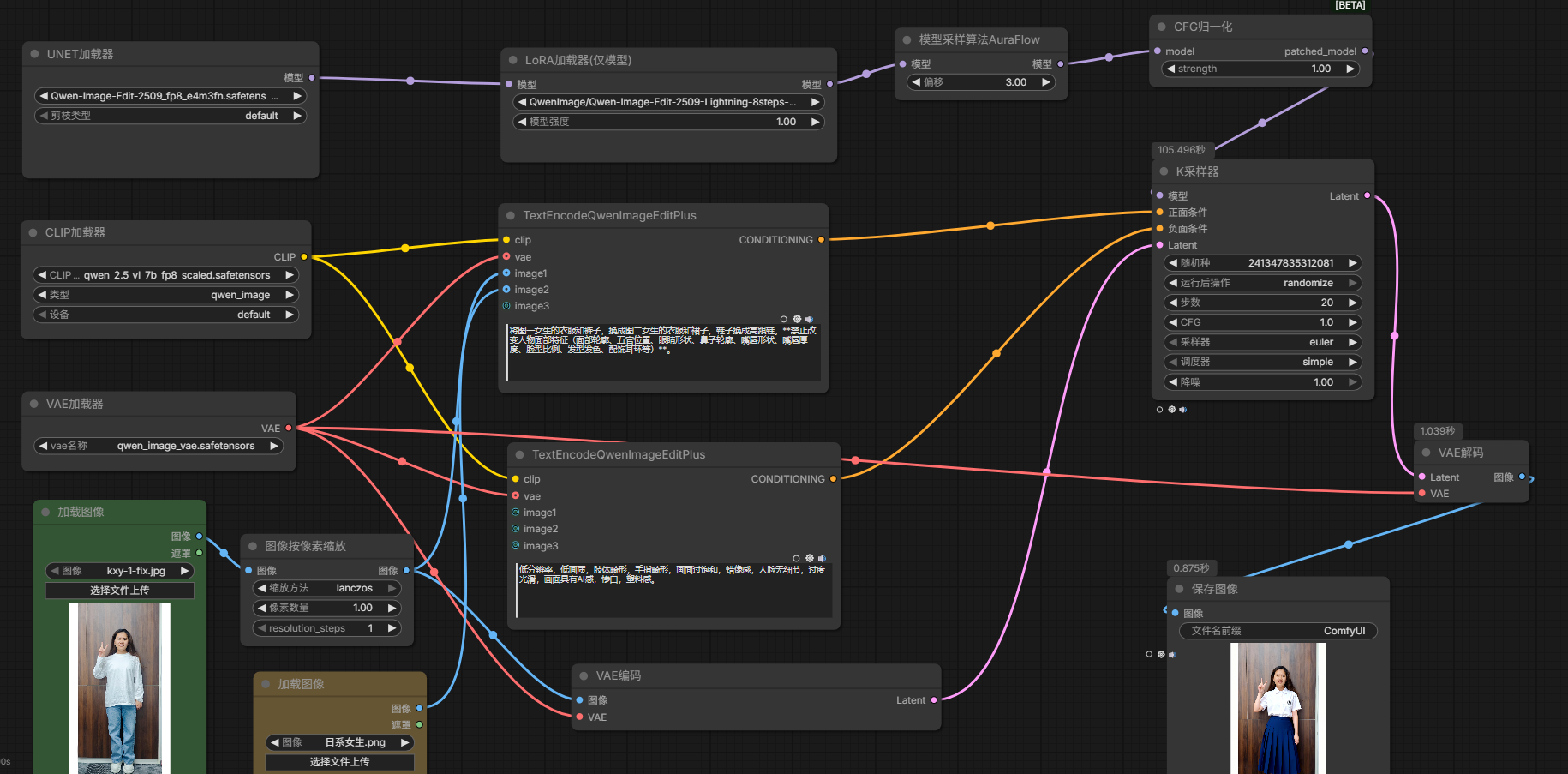
默认工作流(不推荐,效果太差)
- KSampler
- 正向:CLIP Text Encode (Prompt)
- 负向:CLIP Text Encode (Prompt)
- 模型加载器:Load Checkpoint
- 图片加载器:Load Image
- VAE Encode
- VAE Decode
- Save Image
comfy图生视频
facefusion&&人脸替换
源代码下载
https://github.com/facefusion/facefusion
准备环境
# 创建环境
conda create -n facefusion python=3.13
# 切换环境
conda activate facefusion
# 安装环境
python install.py --onnxruntime cuda
# 安装依赖
pip install -r requirements.txt
# 运行
python facefusion.py run
找不到 openvino.dll
set "OPENVINO_PATH=C:\Users\leo\.conda\envs\facefusion\Lib\site-packages\openvino\libs"
set "PATH=%OPENVINO_PATH%;%PATH%"
常用配置
首次运行最好什么配置也不加
3.5版 output_audio_encoder 默认设置没有声音
[paths]
output_path = C:\Users\leo\Videos\
[output_creation]
output_audio_encoder = aac
output_video_encoder = libx264
output_video_preset = veryfast
命令行参数说明
python facefusion.py [commands] [options]
options:
-h, --help show this help message and exit
-v, --version show program's version number and exit
commands:
run run the program
headless-run run the program in headless mode
batch-run run the program in batch mode
force-download force automate downloads and exit
benchmark benchmark the program
job-list list jobs by status
job-create create a drafted job
job-submit submit a drafted job to become a queued job
job-submit-all submit all drafted jobs to become a queued jobs
job-delete delete a drafted, queued, failed or completed job
job-delete-all delete all drafted, queued, failed and completed jobs
job-add-step add a step to a drafted job
job-remix-step remix a previous step from a drafted job
job-insert-step insert a step to a drafted job
job-remove-step remove a step from a drafted job
job-run run a queued job
job-run-all run all queued jobs
job-retry retry a failed job
job-retry-all retry all failed jobs
千问修图
先用千问修人
{
"model": "wan2.6-image",
"input": {
"messages": [
{
"role": "user",
"content": [
{
"image": ""
},
{
"text": "对图片中的人物轻微美白、轻微磨皮,保留皮肤纹理和五官特征。衣服褶皱自然抹平。**禁止改变人物面部特征(面部轮廓、五官位置、眼睛形状、鼻子轮廓、嘴唇形状、嘴唇厚度、脸型比例、发型发色、配饰耳环等)**"
}
]
}
]
},
"parameters": {
"n": 1,
"negative_prompt": "低分辨率,低画质,肢体畸形,手指畸形,画面过饱和,蜡像感,人脸无细节,过度光滑,画面具有AI感,惨白,塑料感,面部特征(面部轮廓、五官位置、眼睛形状、鼻子轮廓、嘴唇形状、嘴唇厚度、脸型比例、发型、发色、耳环、配饰)",
"prompt_extend": true,
"watermark": false,
// "size": "720*1280",
"seed": 2345
}
}